今天把剩餘的動作進行完成、收尾。
主要就剩過濾重複資料跟分頁處理。
要過濾重複資料,就需要找到這些資料的唯一值,我選用的是網址。
昨天我們安裝了H2資料庫,只要網址不在資料庫中,就寫入。反之,則代表是舊的物件,則跳過。
下面實作:
JpaRepository 是 Spring Data JPA 提供的一個介面,它為你的資料庫操作提供了一個簡化的方法。當你定義一個 Repository 介面時,這個介面通常會繼承 JpaRepository,並且需要與一個 Entity 類別對應。
那JpaRepository本身已經含基礎的CRUD了,我額外需要查找是否有重複的物件查詢,所以增加了findByLink,我的條件就是網址。
package tw.grass.rental_crawler.repositories;
import org.springframework.data.jpa.repository.JpaRepository;
import tw.grass.rental_crawler.entity.RentalDetail;
public interface RentalDetailRepository extends JpaRepository<RentalDetail, Long> {
RentalDetail findByLink(String link);
}
先在Service引入Repository
@Autowired
private RentalDetailRepository rentalDetailRepository;
邏輯處理
//確認是否有重複資料
RentalDetail findByLink = rentalDetailRepository.findByLink(link);
//無重複就寫入,有就跳過
if (findByLink == null) {
RentalCatalogDTO rentalIfo = new RentalCatalogDTO();
setRentalCatalogValue(title, link, address, price, floorAndArea, distanceToMrtName, distanceToMRT, rentalIfo);
list.add(rentalIfo);
//寫入資料庫
RentalDetail entity = new RentalDetail();
entity.setLink(link);
rentalDetailRepository.save(entity);
log.info("寫入:{}", title);
} else {
log.info("重複:{}", title);
}
執行結果如下: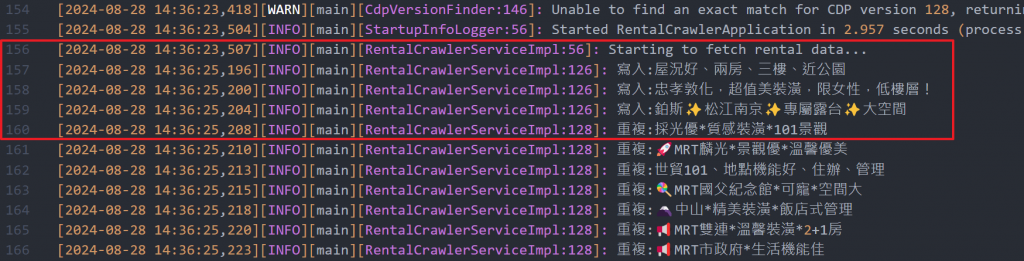
591條件都是get,所以換頁只要在url參數增加&page=2即可
// 591一頁為30個租屋資訊,所以當有30筆新資料時,去第二頁再做一次
if (rentaCatalogList.size() == 30) {
log.info("第一頁皆為新資料,去第二頁進行爬去");
doc = getJsoupDoc("https://rent.591.com.tw/list?other=newPost&sort=posttime_desc&page=2");
rentaCatalogList.addAll(parseRentalCatalog(doc));
}
執行結果如下: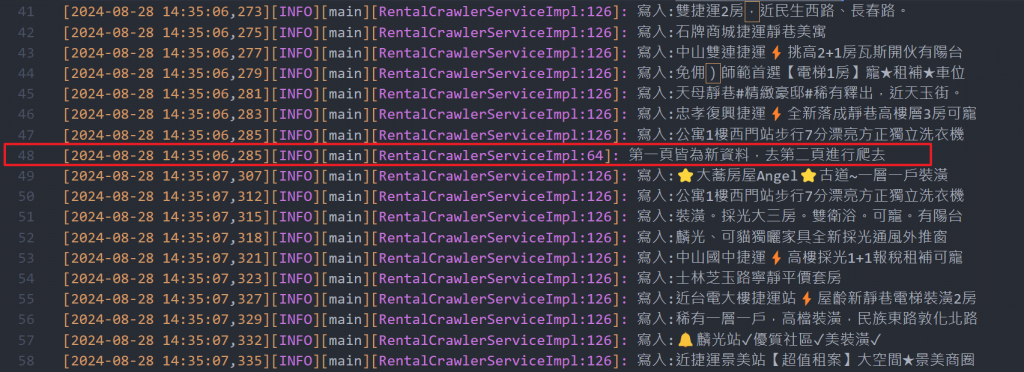
理論上應該使用While迴圈,撈完30筆就去下一頁,直到最尾頁。但是我怕造成591 Server的負擔,就取最新的60筆即可(我也怕我被黑單XD)。
取得詳細資料這邊,我也有限制筆數,執行一次最多取得三筆詳細資料。
因為一筆就會打591的網址一次,開發階段,先打少次一點,怕黑單XD
後面有機會再來研究如何避開這問題。
rentaCatalogList = rentaCatalogList.stream().limit(3).collect(Collectors.toList());
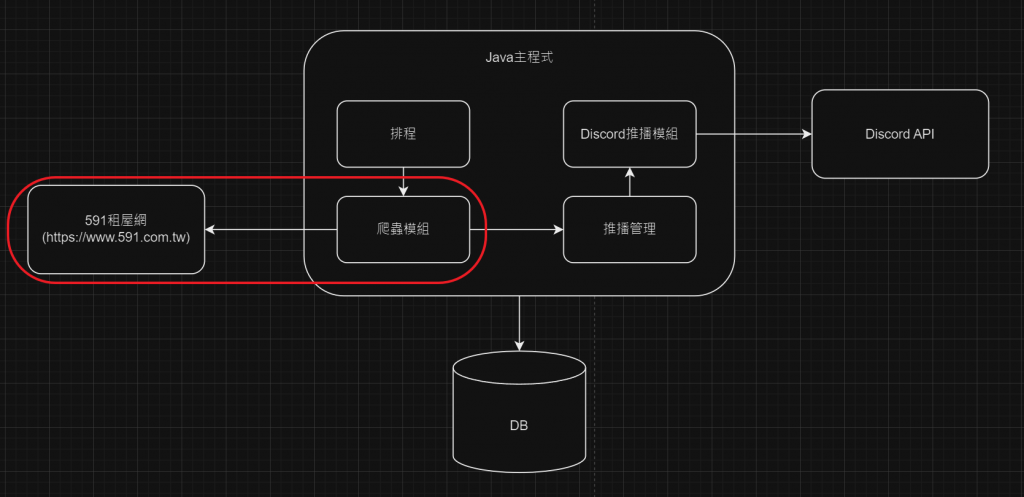
沒意外的話,明天開發排程模組。


 iThome鐵人賽
iThome鐵人賽