"Many things prevent knowledge, including the obscurity of the subject and the brevity of human life."
-- Protagoras
「整晚又整晚...整個星期又整個星期...就只為了一個字...有時還只為了一個連接詞。您要了解,醫生,嚴格說來,在『但是』與『而且』之間做選擇還算簡單。介於『而且』與『接著』之間就已經比較困難。『接著』與『然後』困難度更高。但最困難的莫過於是選擇到底該不該加『而且』這個字。」
-- 〈瘟疫〉,卡繆著,嚴慧瑩譯
這次的感受真的與前幾次參賽非常不同,幾番動手行文,總是增修刪減不斷,難以開始。後來才豁然開朗,既然如此踟躕,那還是就從踟躕的本身開始說起,才是我的風格。由於除了技術部份之外並無準備文章,本來想要以完全生冷的方式只論實作與實驗結果,但這樣一破題後,顯然我也已經廢棄了這條路線。所以還是讓這個專案的分享如多維度的雜訊分佈一般,什麼都有的大雜燴類型來呈現吧。
這次大會新增了佛心分享-SideProject 類別,剛好切合我一貫以來參賽的角度。但時也命也,這次的 AI 實戰於我卻又是最跌跌撞撞的專案。比之予焦啦,助跑期大致相仿(兩年左右),但是完成度和每個小階段的踏實感都遠遠不及;比之前年放飛自我的 hyperscube 也少了遊興與隨手亂寫的瀟灑(說也奇怪,ChatGPT 出現之後,反而沒有憑本能亂寫英文的勇氣了)。雖然是遊戲位居核心的一個專案,卻總令我眉頭深鎖,好像突然被宇宙開了個玩笑,置放到完全不同物理尺度的時空,所有的常識若不是被挑戰或推翻,就是意會到那些只是欠缺深度的愚者之信。
我會偶爾混用遊戲 AI、遊戲代理人、代理人或機器人,他們都指涉能夠成功與 server 互動並做出決策抵達遊戲終局的程式。
DeltaPathogen 專案的目的在於,針對疫途這個遊戲,訓練出可以擊敗真實玩家的代理人。
要論遊戲 AI 以及相關的衝擊性事件,必當回顧 Google/DeepMind 團隊在 2016 以 AlphaGo 風光擊敗世界棋王李世石的第一局實況的那個奇點,或許是最快能夠累積感覺的方式,但該年年底,DeepMind 繼續以升級版 Master 在對弈平台上斬盡中日韓高手之後,他們還再以後來的 AlphaZero 超越了團隊先前的成就:這些超人數等的遊戲 AI,不再仰賴人們過去累積的圍棋知識,而純以自我對局的方式累積棋譜並進化。
感謝旗標在 2021 年翻譯並出版了布留川老師的強化式學習:打造最強通用演算法 AlphaZero,讓我們業餘愛好者能夠試著移植;也感謝深顏色工作室在棋類遊戲的研發努力,讓我在 2023 年初得以在展覽攤位上入手疫途這款遊戲。至於為什麼要以這款遊戲作為目標,而非其他更經典或更具代表性的桌遊或特定抽象棋,我也沒有明確的理由,只是把約五百天前的一個起心動念當作槍響,就或急或徐地走走停停起來,至今仍茫然不知終點線在何方。
該書,在之後的系列文當中,以參考書直接略稱。
不是沒有想過以 PathogenZero 或是 AlphaPathogen 來命名這個專案,但兩者都太狂妄了,完全沒有把握,也不認為合宜。排名第四的希臘字母 Delta 的話卻是剛剛好,代表這個專案只是小小的一些嘗試,與毫不嘗試略有不同,也就這樣而已。
我會偶爾混用這個專案與 DeltaPathogen。
形式上,這個專案的程式碼大致上都涵蓋在 PathogenEngine repo 裡面。這是一個 Rust 專案,裡面實作了疫途遊戲基本規則,而真正對弈時使用的 server 以及強化學習的部份,各自存在 examples 裡面,符合一般函式庫型的 Rust 專案的做法。
雖然沒有具體的章節規劃,但涵蓋的重點大致如下:
這個打算是,選擇較大的單一概念或主題當作一天的題目,而非按照時序或檔案序走過現有的程式碼。寫作力求教學意義的技術文章於我,一直有一個窒塞的感受,最近接觸到有人描述(抱歉,也不確定原典出自何處了),寫作只能對應到讀者的主觀時間感受而序列化(serialization)自己的材料,豁然開朗。大前年的拙作予焦啦系列花了非常多的力氣,先求技術上達到可接受的程度,於開賽前又重新整理程式碼,將完全非線性的開發、除錯經驗收編乾淨,好不容易才能夠理出一個順暢的敘事,於 DeltaPathogen,完全沒有這個餘裕。
想要增設每日的「目前狀況」一節,讓兩條並行的時間軸事件能夠有一個參照的機會。
第一條當然就是系列文,官方的話是 30 天,但有些延伸材料的話也可超過。這是表面上的。
第二條則是實際上的進行。往年我的作法會是在後記再當作幕後花絮論及,但這對這次的我來說又是額外的認知負擔,所以不如直接作為每日展示的部份。這應該可以算作是多重奏的一種拙劣模仿(相較於鋼琴詩人與這段影片的安迪老師本人)。總之,
那些厲害的研究者都會描述「訓練了幾個世代之後...」這樣的句子,但是我作為孵育員怎麼選擇親代?沒有明顯的優勢,還需要以該模型作為下階段的展開嗎?由於時常陷在這些猶豫之中,以至於現在我還沒有長出一個族譜,而還在非常早期從最低劣的隨機對局開始學習的狀態。
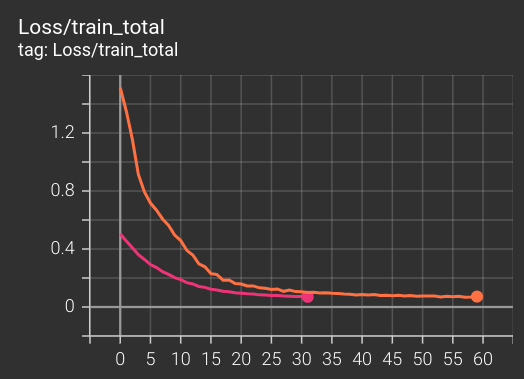
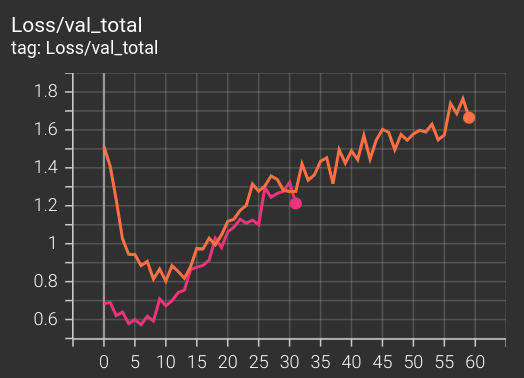
而且生成這些對局資料並紀錄,也是著實考驗著我的程式能力,但無奈沒有太多力氣可以做效能最佳化,所以還是需要非常多時間收集,但又幾個 epoch 內就會過擬合(overfitting)。所以最誠實的開賽語就是,我沒有把握能夠在這三十天內訓練出一個真的有學會什麼遊戲策略(乃至於遊戲規則!!!)的代理人,但是我可以展現我在這個過程中的謙卑。
在寫作的此刻,訓練的進度仍然令人難以滿意。但總之,我自己會把這一系列當作夾帶不少資訊技術的遊記來寫,希望還能寫出一些第一手的困惑與疑問、咀嚼的過程中反覆的苦澀與微甘,其他就很難再多奢求什麼了。

