為了避免資料使用上有侵犯隱私的疑慮,在許多領域,如:金融、醫療等,常會使用合成資料來符合研究需求。合成資料是透過各種技術生成的數據,模擬真實資料的統計特徵。常見的技術包括:生成對抗網絡 (GANs)、變分自編碼器 (VAE) 等。這樣可以在進行資料分析或模型訓練時,避免暴露真實的個人資訊。同時,合成資料也能用來解決資料稀缺或無法取得的問題,提供研究人員更大的靈活性。
CTGAN 是一套基於深度學習的合成資料生成器,用於表格資料。它們能夠從真實資料中學習,並生成具有高準確度的合成資料。
程式碼如下:
!pip install ctgan
from ctgan import CTGAN
from ctgan import load_demo
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import mutual_info_score
from sklearn.utils import resample
real_data = load_demo()
# 離散資料欄位
discrete_columns = [
'workclass',
'education',
'marital-status',
'occupation',
'relationship',
'race',
'sex',
'native-country',
'income'
]
ctgan = CTGAN(epochs=10)
ctgan.fit(real_data, discrete_columns)
# 生成合成資料
synthetic_data = ctgan.sample(1000)
# 將合成資料轉換為 DataFrame
synthetic_df = pd.DataFrame(synthetic_data, columns=real_data.columns)
# 對真實資料進行重抽樣,以匹配合成資料的樣本數量
real_data_sampled = resample(real_data, n_samples=len(synthetic_df), random_state=42)
# 視覺化真實資料和合成資料的分佈
def visualize_column(column_name):
plt.figure(figsize=(10, 5))
sns.histplot(real_data_sampled[column_name], color='blue', label='Real Data', kde=True, stat="density", linewidth=0)
sns.histplot(synthetic_df[column_name], color='red', label='Synthetic Data', kde=True, stat="density", linewidth=0)
plt.legend()
plt.title(f'Distribution of {column_name}')
plt.show()
# 視覺化`age`欄位
visualize_column('age')
# 評估真實資料和合成資料之間的mutual_information
def evaluate_mutual_information(real_data, synthetic_data, columns):
mi_scores = {}
for column in columns:
mi = mutual_info_score(real_data[column], synthetic_data[column])
mi_scores[column] = mi
return mi_scores
# 計算 mutual information scores
mi_scores = evaluate_mutual_information(real_data_sampled, synthetic_df, real_data.columns)
print("Mutual Information Scores:", mi_scores)
age 欄位於真實資料和合成資料的分佈:
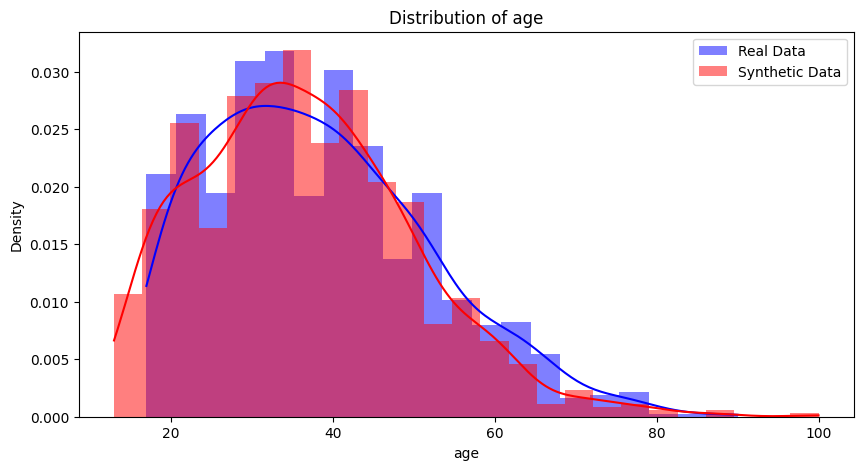
從分布來看合成資料跟真實資料在age欄位生成的比例有高度相似。
最後兩天決定實作一個side project來收尾🔥


 iThome鐵人賽
iThome鐵人賽