Embedding 是 RAG 很重要的一個概念,他讓文字內容的文字特徵或表徵(Feature/Representation)被轉成數字,變成數字後,就可以進行運算,像是文字相似度、文字檢索、推薦等
舉例單詞"貓"可能被表示為[0.7, 0.3],而"狗"可能是[0.6, 0.4],向量之間的距離反映了單詞的相似度。
這邊實作 Embedding 我們靠 open ai 的 model text-embedding-3-small。請 ChatGPT 給了一個範例,可以比較清楚理解文字透過 Embedding 轉成向量的樣子,以及他們如何被做比較
from openai import OpenAI
import numpy as np
import os
from google.colab import userdata
# OpenAI API Key
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
client = OpenAI()
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def cosine_similarity(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
def compare_words(words):
embeddings = {word: get_embedding(word) for word in words}
print("Embeddings:")
for word, embedding in embeddings.items():
print(f"{word}: {embedding[:5]}... (顯示前5個元素)")
print("\nCosine similarities:")
for i, word1 in enumerate(words):
for word2 in words[i+1:]:
similarity = cosine_similarity(embeddings[word1], embeddings[word2])
print(f"{word1} - {word2}: {similarity:.4f}")
# 使用示例
words_to_compare = ["狗", "貓", "魚", "鳥"]
compare_words(words_to_compare)
Embeddings:
狗: [0.002514792140573263, -0.011070974171161652, -0.017623620107769966, -0.01839452050626278, 5.516582677955739e-05]... (顯示前5個元素)
貓: [0.022809654474258423, -0.009842266328632832, -0.024440694600343704, 0.056675516068935394, -0.025897424668073654]... (顯示前5個元素)
魚: [0.0210289154201746, 0.001990667777135968, 0.01998624950647354, 0.02225816249847412, 0.039731040596961975]... (顯示前5個元素)
鳥: [0.041211631149053574, 0.011997758410871029, 0.004766767378896475, 0.006946657318621874, 0.0010369810042902827]... (顯示前5個元素)
Cosine similarities:
狗 - 貓: 0.5808
狗 - 魚: 0.4329
狗 - 鳥: 0.4548
貓 - 魚: 0.4917
貓 - 鳥: 0.5154
魚 - 鳥: 0.5246
同理今天使用者如果提出了一個問題,我們也要用 embedding 轉成數值才有辦法比對。下面找到了張圖分享給大家。
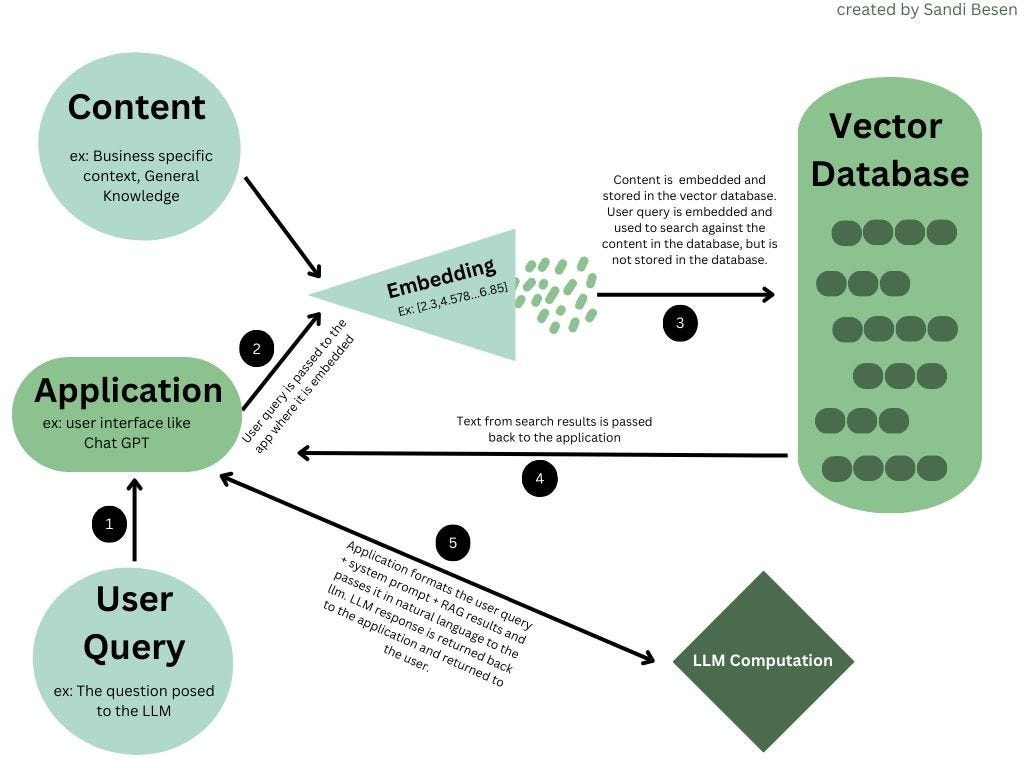
ref: https://pub.aimind.so/llm-embeddings-explained-simply-f7536d3d0e4b

