在聊 RAG 之前,要先聊聊現在大家熟悉的 LLM 侷限,這應該大部分的人的碰過。
知識不完整/過時:
由於語言模型是靠 data train 出來的。基本上大宗的 LLM 像是大家熟知的 ChatGPT,都是用網路開放資料餵出來的。這有兩個狀況
你不可能 always 拿資料 train 他,因為資源是有限的(計算資源和儲存空間)。所以資料難以有最新的
若是公司內部或是個人資料,因為 LLM 無法拿到對應資料,所以他也沒辦法協助回答。
幻覺
資安
於是有了 RAG ,RAG 是針對 LLM 輸出進行最佳化(優化)的方式。最簡單理解方式就是我們將想餵的資料(可能是公司 data)+網路開放資料餵出來的LLM一起作為評估。藉此解決 知識不完整/過時 的問題,同時我們優化 prompt,讓 prompt 跟 LLM 協作,避免讓幻覺的回答跑出來。同時,我們並沒有將公司 data 喂給 LLM,這也可以避免資安的疑慮。
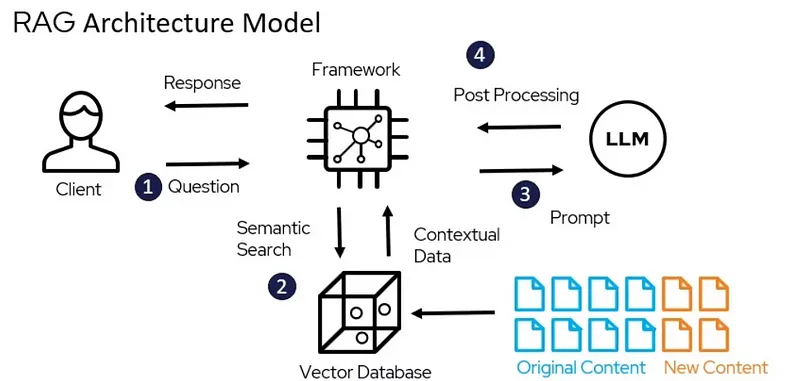
ref: https://medium.com/@bijit211987/advanced-rag-for-llms-slms-5bcc6fbba411
目前網路上找到比較清楚的圖大概是這張。當使用者提問後,這個提問會被轉成向量文字,而向量文字會跟公司的向量資料庫(裡面可能是公司 data)比對後,給予最相關的文字,然後丟出來的文件我們再藉由定義好的 prompt 丟給 LLM ,最後讓 LLM 回傳 answer,再根據 output 格式回傳。


 iThome鐵人賽
iThome鐵人賽