在 RAG 上,使用者問的問題會被轉成向量資料,跟資料庫向量資料做比對找相似性。但使用者問題有時並不能很明確的對照到向量資料。所以我們會在中間做一層加工,在 HyDE 中,會使用指令跟隨語言模型(InstructLM),它會根據給定的查詢和指令生成"假設性"文檔。藉由中間多一層 LLM 來捕捉查詢的語義和意圖。
論文查看:https://arxiv.org/abs/2212.10496
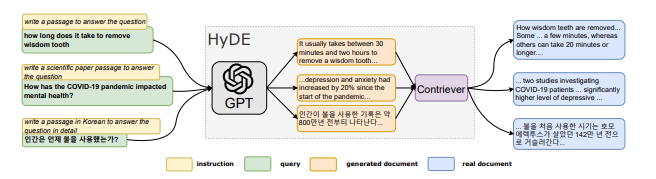
ref: https://arxiv.org/pdf/2212.10496
從架構圖來看,我們可以發現最左邊我們採用InstructLM,對用戶的問題延伸了不同的問法,然後用生成出來的文件向 向量資料進行比對,最終的查詢向量會採取這些假設文檔向量的平均值。
HyDE 方法的核心實現有以下步驟
generate_hypothetical_document = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一個專門研究台北大稻埕歷史的專家。"},
{"role": "user", "content": f"請簡短回答這個關於大稻埕的問題:{query}"}
]
)
model = SentenceTransformer('distiluse-base-multilingual-cased-v1')
query_embedding = model.encode([query, hypothetical_doc])
query_vector = np.mean(query_embedding, axis=0)
# 編碼文檔
doc_embeddings = model.encode(documents)
similarities = cosine_similarity([query_vector], doc_embeddings)[0]

