前言
在簡單介紹完 RAG(檢索增強生成)的基本概念及其在現代自然語言處理中的重要性。接下來,我們將深入探討 RAG 的技術架構,了解其內部各個核心元件的運作流程,以實現高效且精確的生成結果。
RAG 流程
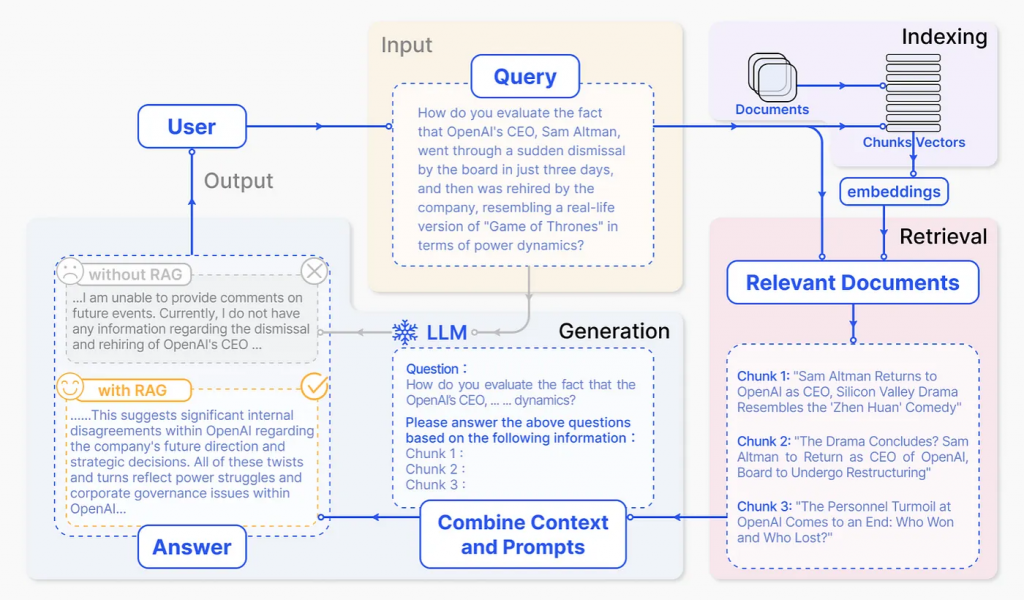
上圖為 RAG 的流程,可以分為四個部分:
- Input(輸入):Input 為輸入 LLM 的問題。如果沒有使用 RAG,則 LLM 直接回覆。
- Indexing(索引):分為兩個部分
- Raw Data:在進行問題的處理前,會先將外部原始資料切分成較小的 chunk(區塊),接著透過 Embedding Model(詞嵌入模型)轉換成向量,再將轉換好的向量儲存至 Vector Database(向量資料庫)。
- Input Query:將 Input 的問題透過 Embedding Model 轉換成向量後,接著會進入 Retrieval 步驟。
- Retrieval(檢索):Retrieval 會將問題轉換的向量,透過如餘弦相似性(cosine similarity)來計算兩個詞向量之間的相似性,以得到檢索結果。
- Generation(生成):最後會將 Input 的問題與 Retrieval 的結果一併提供給 LLM,LLM 會將檢索的內容當作參考資料來進行問題的回覆。
從上面的圖可以看出,如果直接透過 LLM 進行問題的回覆,結果可能會不理想,但如果先透過 RAG 檢索相關資料提供給 LLM 進行問題的回覆,可以有效提升回覆的精確度。
參考文獻
Gao, Yunfan et al. “Retrieval-Augmented Generation for Large Language Models: A Survey.”, 2023.

