沒過多久局面倒轉,電腦開始讓子給人類對手。我也曾好奇地挑戰了電腦幾次,但每次都比不到一半便敗跡畢露。明知沒有辦法,還是被激怒了......
-- <突圍思考>,曹薰鉉著,盧鴻金譯
也過了這麼多天,如果機器學習的部份還不進場,單就遊戲系統的部份的描述實在有暖場過久之嫌。如果以原本我預期的文稿的出場順序繼續發文,恐怕還要拖個一陣,才能真的輪到機器學習的部份。由於在前十天的目前狀況也已經陸續更新訓練代理人過程中的一些想法與進度,所以還是盡快補上這個部份吧。
同前述,為了 DeltaPathogen 專案,購買了主要參考書的強化式學習:AlphaZero 通用演算法之外,其實我也買了強化學習深度解析以及深度強化式學習。後兩者介紹了許多強化學習(以下或略寫為 RL)的典範概念,最後這本尤其附有程式碼,不像第二本是演算法教科書。這些強化學習典範概念,從最簡單的一些(比方說 Q-Learning),到複雜的(Intrinsic curiosity module 之類),也都有小遊戲(大多是 OpenAI Gym)作為範例且成功訓練。
過去的得獎系列文 Knock Knock! Deep Learning,以及從根本學習Reinforcement Learning,也都介紹了相關的強化學習方法。另外線上學習資源也很多,如李弘毅老師的教學影片
但有一個直接的事實,情感上有點尷尬。AlphaZero 的論文的方法一節,整理了許多西洋棋和將棋的 AI 研究先驅之後,於結語這麼說道:
None of the techniques described in this section are used by AlphaZero. It is likely that
some of these techniques could further improve the performance of AlphaZero; however, we
have focused on a pure self-play reinforcement learning approach and leave these extensions
for future research.
我認為,「純粹的閉關自我修煉即可修成一代高手,也許你們的技巧可以幫助武學再上層樓(,但我不需要)。」的感覺濃厚。所以在主要參考書中,也不見整個強化學習領域那些令人頭暈的演算法。DeepMind 的論文作者以及參考書作者可能是相關知識已經內化,而我們這些啃食懶人包密笈的實作者難免因此根基不穩,但,根基有空再補就好,side project 不就是要圖個做得好玩嗎?
還有,論文中所有的 Reinforcement Learning 一詞,都出現在強調 AlphaZero 方法自己,而不是參照到過去的前輩。雖然是概念上都屬於強化學習,但隱然有「我也不是奠基在你們之上,當然不需引用你們作為參考」之感。一開始覺得光是這樣就有傲慢躍然紙上,但仔細想想這根本不關我的事,人家 CEO 是西洋棋大師,並且 AlphaZero 輕鬆擊敗 Master,而 Master 是能夠輕鬆擊敗擊敗了棋王李世乭的 AlphaGo 的圍棋 AI。一切全憑實力。
本文內容整理自中文版(旗標出版)「強化式學習:AlphaZero 通用演算法」的教學與說明。以下以主要參考書指稱。
AlphaZero 強化演算法有三大組成元素:
在主要參考書的第六章,作者實作了一個井字遊戲代理人。其架構如下
我一直很感興趣的是這些模組如何應用在不對稱棋類上。比方說,是否有別於井字遊戲或圍棋只須訓練一個代理人,我是否應該要訓練三組代理人,分別餵食純的疫病方著手資料、純的醫療方著手資料、和混合的綜合遊戲著手資料?是否應該同時維護三組最強,然後每次迭代就來個 3x3 的循環賽矩陣分看各個代理人的勝率?但,這美好的遊玩心態最後敗給了時間。實在沒有時間展開那些組合,也因為後續陸續的發現而更新作法,以至於必須先專注在單獨訓練疫病方的代理人。
接下來我會進入蒙地卡羅樹模擬部份的實作,這無疑的是這個專案裡面最燒腦的環節。從六、七月開始思考相關的作法,但還是牛步進行。另外我在 python 部位的測試實踐完全是一片空白,所以短暫衝刺的結果還是留下了許多不確定性。總之這個部份也會在接下來的數日與各位分享。
趕在這個不至於太尷尬的地方切入機器學習篇。如前幾日已經有宣言給讀者做心裡準備,那就是我沒有要百分之百引用 AlphaZero,而是想要先以我自己的想法踩出第一步。從 訓練紀錄看來,現在已經進行到第 15 代,但其實前面的各個世代多得是重開機的全新模型訓練。實際上,完全還沒有開始自我對弈迭代這麼回事。所以,說現在還在等待槍響,也不為過。
事實上更有趣的是,在這過去的 15 個世代當中(well,在 github 上只看得到 summary,因為 simulation 的棋譜、train 的每個 epoch 的模型,都會佔空間。沒有 train 好的模型根本沒有分享的價值),這種「終於要踏出第一步了!」的感覺時常出現,以至於我現在根本也很難盡數每個轉折點、每個興奮的期待和每次失落所為何來。希望之後能夠再慢慢跟大家分享那些轉折點。
接下來,這種定性論述的簡介文稿,大概還有以下幾篇比較明顯的主題,
算起來 19 天;再之後就沒有主題了,就分享當時的訓練心得或是回顧目前為止的心得。假設可以分享 5 篇上述說的數個世代間的轉折,這樣是 24 天的份。剩下的 6 天,或許就可以開始寫附錄,描述相關的一些內容、之後有時間應該進行的研究方向、與友人之間針對桌遊的閒聊之類。
我曾描述上一屆晶心壯士 II 的隊友是用一個月的時間進行黑客松(打通 rv32 版本的 alpine linux),這一次則輪到我,而且還更不確定未來如何...
但是!!!就在昨晚,向友人 J 訴苦之後,稍微轉向的作法,竟然又有一種,終於要踏出第一步了!的感覺。不囉唆,上圖:
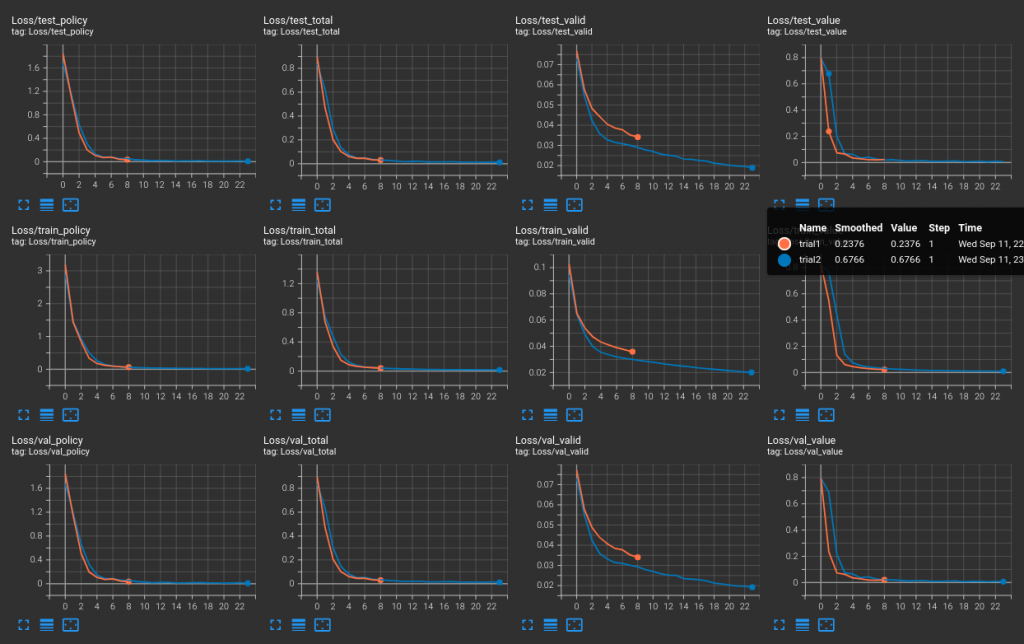
個別圖表的標題意義會在明天的對偶網路實作之中解釋。但總之,這裡三排,下兩排是使用交叉驗證的訓練和訓練中驗證的損失曲線,可以看到兩者都 fit 得還不錯,這還沒什麼;最驚喜的是上排的測試用資料,竟然也 fit 得很好。這表示有些通用的概念開始累積在模型內部,讓它推論未曾見過的資料集也能夠有不錯的表現。
但是,這樣就能夠確定下棋下得更好嗎?這就必須留待後續檢驗了。

