Retrieval :是給定我們user的question並且使用檢索器撈出我們設定好K值的近似值EX:search_kwargs={"k": 6},就會撈出前6名相似值,
generation:簡單來說就是LLM啦,不要想的太復雜!
流程就會是以下:
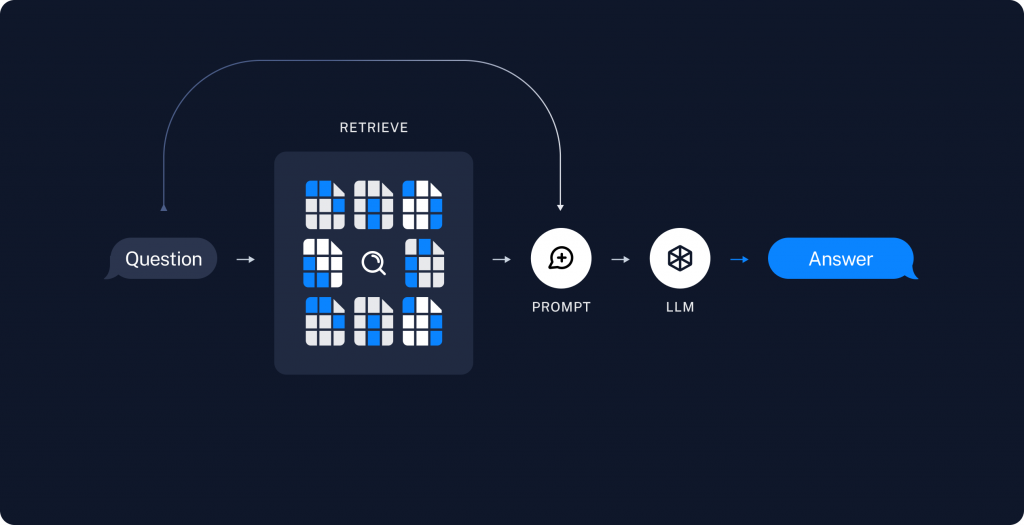
user 問完問題找出相關的值透過我們設定好的prompt template最後全部給LLM,生成最後的答案!是不是看起來很簡單呢~
以下程式碼是我們db連線後,並且把文字轉成向量存入資料庫的方式!
retriever 就是我們產生出來的檢索系統!
CONNECTION_STRING = "postgresql+psycopg://benson:benson@localhost:5432/postgres"
embeddings = OpenAIEmbeddings()
vectorstore = PGVector(
embeddings=embeddings,
collection_name="rag_demo",
connection=CONNECTION_STRING,
use_jsonb=True)
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore.add_documents(splits)
retriever = vectorstore.as_retriever()
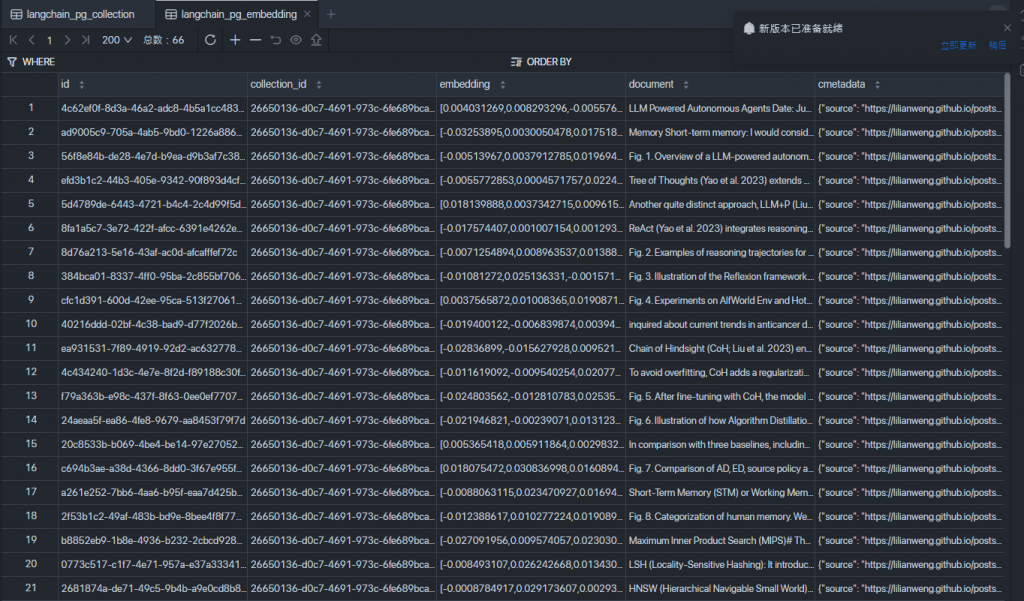
先看一下embeddings 後的廬山真面目!

最後就是把retriever 的值一起帶入給AI一起做最後的生成~
prompt = PromptTemplate.from_template("""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
""")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
llm = ChatOpenAI(model='gpt-4o-mini')
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
result = rag_chain.invoke("What is Task Decomposition?")
print(result)
以下完整程式碼範例:
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_postgres import PGVector
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
# Load, chunk and index the contents of the blog.
CONNECTION_STRING = "postgresql+psycopg://benson:benson@localhost:5432/postgres"
embeddings = OpenAIEmbeddings()
vectorstore = PGVector(
embeddings=embeddings,
collection_name="rag_demo",
connection=CONNECTION_STRING,
use_jsonb=True)
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore.add_documents(splits)
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
print(retriever)
prompt = PromptTemplate.from_template("""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
""")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
llm = ChatOpenAI(model='gpt-4o-mini')
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
result = rag_chain.invoke("What is Task Decomposition?")
print(result)
大概解釋一下更動,因為有些是langchian還在測試中的beta版,以及程式碼有棄用的方法,故抽出一些來做使用,並且整理成目前比較符合現行較新的方法,也降低學習的復雜程度,一樣把參考的程式改為pgvector,並且prompt的地方改為使用PromptTemplate來做使用,最後產生出回答的值!
參考資料:
1.https://python.langchain.com/v0.2/docs/tutorials/rag/#retrieval-and-generation
2.https://python.langchain.com/v0.2/docs/integrations/vectorstores/pgvector/#delete-items-from-vector-store


 iThome鐵人賽
iThome鐵人賽