如果在聊到開發產品時,只能夠挑一件最重要的事來說,我一定會選擇「簡單原則」。
會選在系列文章的前面聊聊這個原則,就是因為我覺得這實在是太重要的觀念了!最初我是在學習 System Design 時看到的設計哲學,但是我發現這樣的心法很適合指導一切在產品開發上的選擇。
小到程式碼的排版、Library 的選擇,大到需求的確認、系統的架構設計,在面對每個選擇時,通常都沒有所謂「最好」的答案,此時如果有一套能夠幫助我們做出決定的心法,首推「簡單原則」。
客戶及老闆們大多都希望產品的功能越多越好,工程師在選擇 Library 及第三方服務時也往往希望功能越強大越好。
然而更多的 Features 通常意味著更複雜的設計、更多潛在的 Bugs,也意味著更高的成本,不論是在維護或是開發上。
如果可以選擇,我們應該挑選最「簡單」的那一個。
如果你是 PO (Product Owner)、PM,或是客戶的溝通窗口,在決定需求時可以想想「簡單原則」。
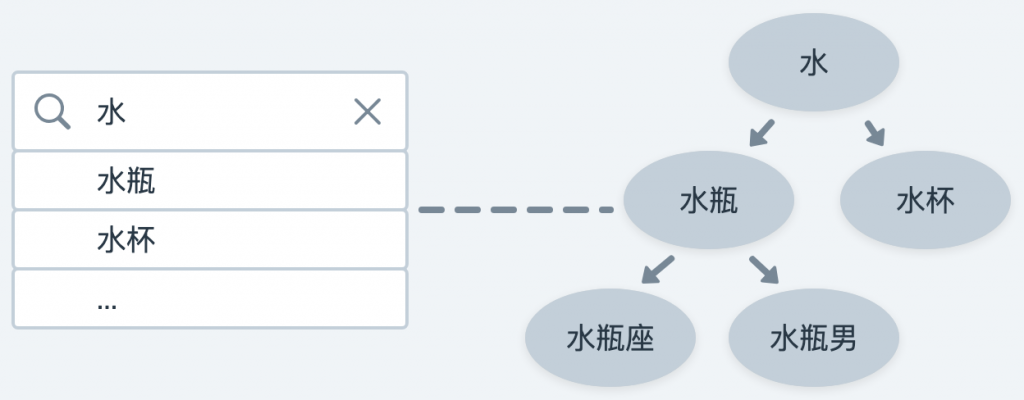
例如我們要開發一個商品的搜尋功能,光是商品名稱的字串搜尋,要做到複雜及完善就可以羅列出很多點
Auto Complete(自動補齊),例如打了「水」就出現「水瓶」、「水杯」
Fuzzy Search(模糊搜尋),例如打錯了「appple」依舊能搜尋出「apple」相關商品
…
*Auto Complete 及 Trie 資料結構
實際要開發時,Auto Complete 通常要考慮送出搜尋請求的頻繁程度,避免伺服器無法負擔;資料量多到一定程度的話,在搜尋的資料結構也要考慮更高效的方式,例如 Trie。
Fuzzy Search 就更複雜了,本質上是在做拼字錯誤的檢查,需要計算資料庫中商品和輸入字串的 Levenshtein Distance 來判斷哪些商品可能是結果;如果要做的是中文模糊搜尋,則就更具挑戰性。
開發這些功能固然能讓產品更加強大,但同時也增加了開發的複雜度和未來維護的維護成本。
因此,在確認需求時一定要問問:真的有這個需要嗎?
常見的情境是這些需求是在發想時覺得很酷,感覺可以幫產品大大加分的,但仔細思考過後才往往發現,實則不然。
就像是,我們開發的產品如果是個後台系統,使用者可能都相當熟悉商品的名稱了,那麼這些額外功能的效益就會大大降低,與其分配資源在 CP 值不高的功能上面,不如在可靠性上花多一點功夫。
把沒這麼必要的功能砍掉,讓需求更「簡單」,留下資源給其他更重要的事。
在挑選 Library、3rd-Party Services 的時候更是時常面臨選擇。舉個例子來說,當我們的系統中有多個服務需要相互溝通時,可以挑選不同種類的資料傳輸方式,例如最簡單的 Request-Response Model(基本的 HTTP API)、雙向傳輸(如 WebSocket)、Message Queue(如 RabbitMQ, Kafka 等等)。
一切先從需求出發,假如需要傳輸大量的數據、能夠實時的處理資料流(如 ETL),同時建立在分散式的架構上,則 Kafka 可能會是不錯的選擇。
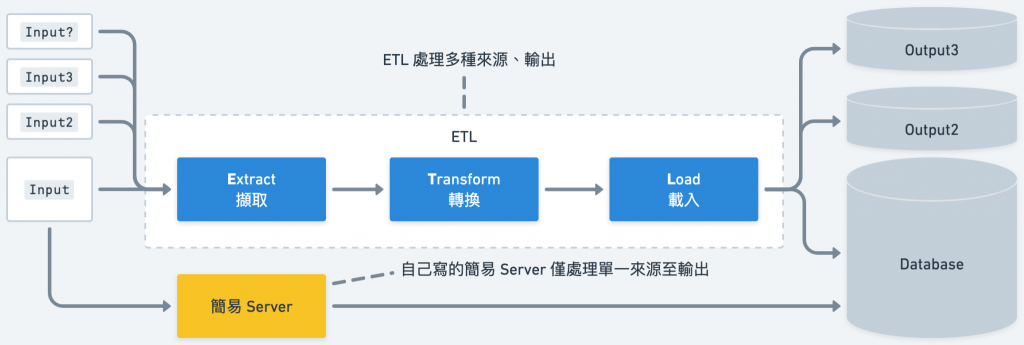
*ETL 及簡易 Server 範例
功能強大,但代價是其他成本
但,如果我們要開發的是一個中小型的產品,資料量沒有這麼龐大,在資料源透過簡單的 HTTP Request-Response 可能就已經綽綽有餘。如果因為想使用 Kafka 的「強大」功能,認為 Kafka 能幫我持久的保存資料,而且部署在不同主機上,不怕一台機器壞掉造成資料丟失,最終選用這個 Service,那可能就是惡夢的開始。
原本只是想收點資料簡單做些處理,突然間要管理的機器就多了好多台,為了在機器壞掉時或網路中斷時出現資料不一致的情況,通常至少要部署三個節點。多了機器,監控的設定總要做吧?因此要維護的機器和相關的 Configurations 就成倍地增加,目的卻僅僅是處理簡單的資料傳遞。
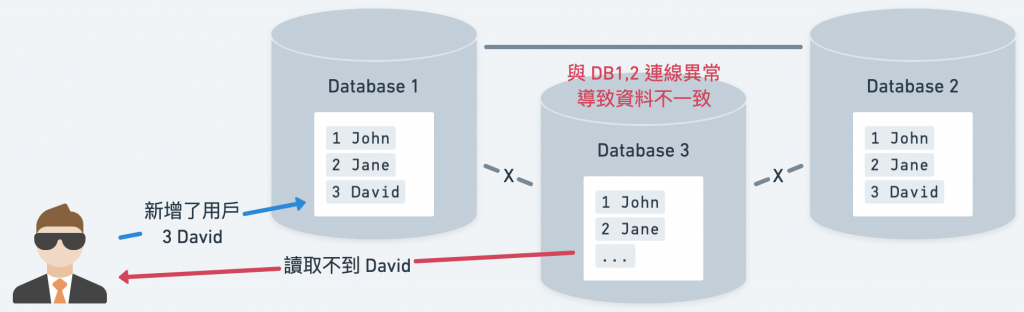
*維護多台資料庫,就需要考慮資料不一致的可能性
能否簡單點呢?
可以的,如果小團隊的我們本身就只有維護一台伺服器,就沒有這個問題。
但你可能就會問,只有一台伺服器,資料遺失怎麼辦呢?服務暫時無法使用又怎麼辦呢?
考量需求面,找出如何做最簡單
就資料遺失這一點來討論,備份是常規操作,我們如果可以允許短時間的資料遺失,每隔一段時間就透過 Cron Job 等方式自動上傳備份就已經足夠,又或是使用 RAID 來避免硬碟壞掉造成的損失。
而關於服務無法使用的問題,在僅有一台伺服器或是一座資料庫時,就會有 SPOF (Single Point Of Failure,單點故障) 的可能性。
一樣從需求出發,看看我們有和客戶簽署 SLA(服務品質的合約,通常會定義可用性,如一年中服務的正常運作的時間)嗎?如果沒有,而且能夠接受一年內有幾天服務是斷線的,那麼使用單機加上監控機制就是「簡單」的做法。
小團隊一旦踏上分散式的歷程,複雜度就會呈指數的上升,我們需要開始思考 Cluster 中某個節點壞掉、網路斷掉的一切後續處理,例如資料是否該保持一致,如果是的話就會犧牲掉系統的可用性,反之,客戶能接受看到不同步的資料嗎?
只要可以 Scale Up(單純增加硬體,如 CPU、RAM 的規格),我就傾向於不 Scale Out(增加機器數量),因為保持簡單,可以省去很多、很多麻煩。
避免因為沒那麼必要的功能,選擇一個很複雜的技術,殺雞真的焉用牛刀,讓服務保持「簡單」,少留一些技術債。


 iThome鐵人賽
iThome鐵人賽