接下來幾講,我們來聊聊產品週期的最後一環:維護(Maintenance)。
當我們興高采烈的把開發完畢的服務交付給客戶,也一項一項的將驗收項目打勾,是否便能夠開開心心的結束這回合?
當然不,如果你有幫客戶架設伺服器,就得面對實際上線後會發生的事;就算是客戶自己維運,也總該簽維護合約來修修 Bug、提供技術支援吧?
縱使上線不久就已經把系統調整得很穩定了,難保不會在幾個月後出現意料之外的 Bug,打了你一個措手不及,因為連當初 Code 是怎麼寫的都忘了,根本不知道 Bug 是在哪裡發生的。
如果我們沒有在開發階段就好好思考上線後,要是出了問題該怎麼知道發生什麼事、又要如何處理,就可能要付出很大的代價了。
維護的第一階段,就是「知道發生什麼事」,當我們被客戶通知有個 Bug 產生時,根據回報狀況,我們可以透過服務的 Log(日誌)來獲取更詳細的資訊。因此要印什麼 Log 就是為了將來的維護需要考慮的事情。
首先是 Log 的分級,大部分的日誌系統都會依據重要程度將 Log 分級。大致可由不重要到重要分成 Debug、Info、Warning、Error。
Debug 不必多說,就是當工程師在開發產品的時候印出一些幫助除錯的資訊,而 Info 之後的等級則一般會在正式上線後也印出來。
我通常會將一些「成功」的資訊記錄下來,例如後端和 Database 建立連線成功、前後端建立 WebSocket 成功,又或是 Background Job 啟動成功、完畢後正常結束,諸如此類的資訊,讓我們在事後 Debug 的時能知道服務某個時刻的狀態是什麼。
但在 Warning 這個級別的 Log,我就用得不多了。因為通常我只有在錯誤發生的時候才會去撈 Log 來看看發生了什麼事情,當有警告的 Log 產出時,意味著雖然有些風險的感覺,但系統還是能正常運行。
除非在之後我們要談的監控和告警上,有特別的 Warning 需要通知,我才會在程式開發時埋上這種等級的 Log。
最後則是日誌的重中之重:Error Log。當我們查看 Log 時,主要會看的就是到底出了什麼錯,讓我們的服務有 Bug,或甚至是整個系統壞掉了。
為了達到這個目的,在開發的階段就需要慎重對待每個可能發生錯誤的地方,而羅列所有可能的 Error Codes 並將其嵌入在 Log 中,就是一個不錯的方式。
首先我會先將這些錯誤分類,根據不同的產品需求,可以有不同的分類方式,但目標就是透過這些分類能快速的找到問題。
例如連線錯誤,像是後端和資料庫建立連線失敗、WebSocket 連線失敗;或是系統錯誤,例如硬碟壞了、記憶體滿了;又或者使用者的相關錯誤,例如前端 Request 帶的參數錯誤等非 2xx 開頭的 HTTP Status Code。
最後無法分類的,則可以統一用最大的 try-catch 包住,印出非預期的錯誤。
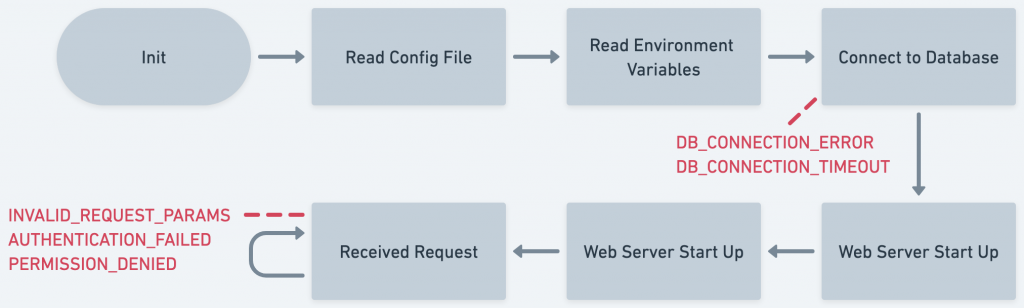
*系統啟動流程,及部分 Error Codes 範例
這些 Error Codes 長的樣子可能如下:
Connection Errors
DB_CONNECTION_ERROR
DB_CONNECTION_TIMEOUT
System Errors
DISK_FAILURE
OUT_OF_MEMORY_ERROR
CPU_OVERLOAD
User Errors
INVALID_REQUEST_PARAMS
AUTHENTICATION_FAILED
PERMISSION_DENIED
有了這些預先定義的 Error Codes,除了能夠更簡單 Locate 錯誤發生在程式碼的哪裡,我們也能夠從 Log Files 之中統計中得到更多資訊,例如哪些類別的錯誤發生頻率最高等等。
在列舉這些 Error Codes 時,其實也是在思考系統哪邊可能出錯,並補上 try-catch 的過程,我們可通過把一整個系統啟動時會做的各種事情,來幫助思考。就像是上面的啟動範例圖,每一個動作都可以衍伸出至少一種 Error Code。
有了不同等級的 Log,以及自定義的 Error Codes,就能在錯誤發生時更好找到原因。但是在資訊量很大的 Log Files 中,要能快速的搜索到我們要的內容,其實有一點麻煩。
如果我們的服務建立在一台 Linux Server 上,將 Log 導入 syslog 或任意的檔案當中,最簡單的方法就是直接讀檔。
我們可以透過 less、tail、grep 等指令來查看和過濾部分的 Log,進而快一點限縮問題的範圍。不過用單純的指令在實務上讀檔案其實很慢,因為這樣的搜尋時間複雜度是線性 O(n)(其中 n 指的是檔案的大小);並且也不太容易做複雜的搜尋,例如看 Log 時其實最需要用到的時間區間搜尋。
所以,當我們除了查看之外還要分析的同時,也可以引入一些查閱 Log 的服務。例如最知名的 ELK,現稱 Elastic Stack,又或是 Fluentd、Grafana Loki 等服務。
這些服務和原生的 Linux 指令最大的差異就是「預處理」,Elastic Stack 中的 Elasticsearch 本質是一個搜尋引擎,會將 Log 中的內容做索引。而將 Log 處理過後儲存,就可以將搜尋的時間複雜度大幅降低,也能更好的基於時間區間搜索,甚至是各種自定義的 Filters。
那麼我們是不是就該引入這些 Log 的查看及分析服務呢?可能還是得看我們實際的使用頻率和需求了,因為要搭建一座 Elastic Stack 所需要的硬體規格其實不小,而用一些雲端的服務又要額外付費,假如我們使用的機會不多,其實還不如定義好 Error Codes,用原生的指令搜尋就好。


 iThome鐵人賽
iThome鐵人賽