講了四天的課,我們來做個簡單的實作
我們更改微軟上傳在Huggingface的microsoft/DialoGPT-medium範例,來建立簡單的AI聊天室。
首先,我們先載入torch, transformers,才能使用Huggingface模型
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
接著,我們使用AutoModelForCausalLM及AutoTokenizer來載入模型及標記器
model_name = "microsoft/DialoGPT-medium" # 微軟的官方DialoGPT,另外有small及large可選擇
tokenizer = AutoTokenizer.from_pretrained(model_name) # 載入tokenizer
model = AutoModelForCausalLM.from_pretrained(model_name) # 載入模型
那我們就可以將自己的輸入進行標記化(Tokenization)
chat_history_ids = None
user_input = input("You: ") # 輸入你要跟GPT講的話
# 將你的話進行tokenization
new_user_input_ids = tokenizer.encode(user_input + tokenizer.eos_token, return_tensors='pt')
# 將你的輸入與上一輪GPT的回覆串接
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if chat_history_ids is not None else new_user_input_ids
這裡簡單來說一下標記化,標記化是語言模型一個必要的動作,
因為字詞是離散的資料,模型是看不懂的。
所以標記化就是將句子裡的各個字詞轉換為數字,
這樣才能將句子轉換成詞嵌入(Embedding)或其他的處理。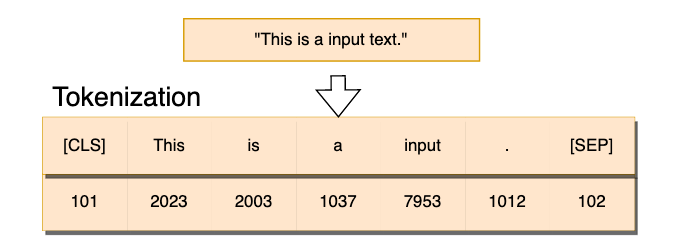
簡單來說tokenizer就是一個字典,而字典裡給予每個字詞不同的標號。
當有一個句子進入tokenizer,它就將句子裡的每個字詞轉換為對應的編號。
那最後,我們使用.generate()來依據使用者的回覆取得GPT的輸出。
chat_history_ids = model.generate(
bot_input_ids, # GPT上輪的回覆+你要講的話
max_length=1000, # 最大輸入字串長度
pad_token_id=tokenizer.eos_token_id, # padding token
no_repeat_ngram_size=3, # 控制生成字串不要重複
do_sample=True, # 讓GPT以機率的方式去採樣輸出
top_k=100, # 取前100的機率去採樣
top_p=0.7, # 生成隨機性設定
temperature=0.8 # 生成一致性設定
)
一些參數的含義我都有用註解說明了,詳細說明可以看這裡:GenerationConfig
在往後的章節,我們會詳細討論do_sample、top_k、top_p及temperature對LLMs的影響。
若你有香噴噴的顯卡,可以加入.to(device)來提升模型的推理(Inference)能力
以下是完整的程式碼dialogpt_chatroom.py:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def main():
# 若有顯卡,可安裝cuda並將模型加入顯卡已提升推理速度
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 載入DialoGPT及tokenizer
model_name = "microsoft/DialoGPT-medium" # 微軟的官方DialoGPT,另外有small及large可選擇
tokenizer = AutoTokenizer.from_pretrained(model_name) # 載入tokenizer
model = AutoModelForCausalLM.from_pretrained(model_name).to(device) # 載入模型
# 初始化對話紀錄
chat_history_ids = None
print("Welcome to the DialoGPT Chatroom!")
print("Type 'Bye' to exit the conversation.")
# 設立一個無窮迴圈,開始與GPT對話
while True:
# 輸入你要跟GPT講的話
user_input = input("You: ")
if "bye" in user_input.lower(): # 如果輸入bye就結束對話。設立截止條件
print("Goodbye!")
break
# 將你的話進行tokenization
new_user_input_ids = tokenizer.encode(user_input + tokenizer.eos_token, return_tensors='pt').to(device)
# 將你的輸入與上一輪GPT的回覆串接
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if chat_history_ids is not None else new_user_input_ids
# 讓GPT產生回覆
chat_history_ids = model.generate(
bot_input_ids.to(device), # GPT上輪的回覆+你要講的話
max_length=1000, # 最大輸入字串長度
pad_token_id=tokenizer.eos_token_id, # padding token
no_repeat_ngram_size=3, # 控制生成字串不要重複
do_sample=True, # 讓GPT以機率的方式去採樣輸出
top_k=100, # 取前100的機率去採樣
top_p=0.7, # 生成隨機性設定
temperature=0.8 # 生成一致性設定
)
# 因為GPT的輸出為一串token(數字),須使用tokenizer解碼
response = tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)
print(f"Bot: {response}") # 將GPT的回覆輸出
if __name__ == "__main__":
main()
然後我們利用pip下載必要的模組(torch, transformers)
pip install torch transformers
再運行整個python檔即可將DialoGPT跑起來囉~
python dialogpt_chatroom.py
以下是與microsoft/DialoGPT-small對話的結果。
You: HI! Who are you?
Bot: I am a man of mystery.
You: Does money buy happiness?
Bot: It does for me.
You: What is the best way to buy happiness ?
Bot: Money is the only way.
You: This is so difficult !
Bot: I don't know, I've never tried it.
註:如果需要讓DialoGPT回覆的更為精準,可以使用torch.cat()來加長對話歷史。
Reference.
Huggingface model-microsoft/DialoGPT-medium
How to Build an Interactive Chat-Generation Model using DialoGPT and PyTorch*
Huggingface-microsoft/DialoGPT-medium

