
昨天我們用了網購服務的新創團隊,來解釋資料庫正規化後可能遇到的資料運用瓶頸。橫空出世的資料工程師透過另建一個資料庫整合來自各服務的資料,記載歷來變化並提供決策輔助時,資料的寬度(來自各服務的資料內容多樣性)與深度(每筆資料的任何變異都儲存)就會成為系統設計上的考驗。此時,資料庫設計的目標就會變成:
看起來,這另建的資料庫就只做了 JOIN 和 GROUP BY,沒什麼特別的呀?請別誤會,記載歷來變化是線上分析處理系統 (Online Analytical Processing, OLAP) 相當關鍵的一個能力!昨天的例子無法顯現這個特質,讓我從生活中挖掘看看。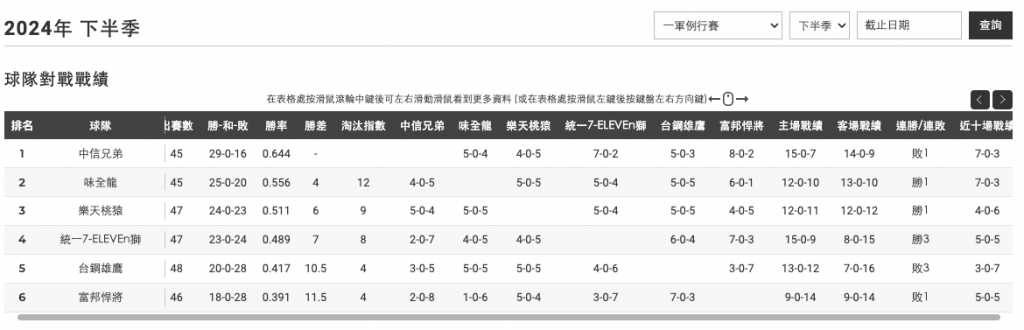
圖/2024 年下半季戰績,擷取自中華職棒官方網站 https://www.cpbl.com.tw/standings/season。
有沒有發現右上角橘色框框寫著『截止日期』?這就是用來查詢球隊戰績歷來變化的,非常適合從 OLAP 架構下取得。
我猜想這個歷史戰績走勢的功能,原始資料是從這張賽程比分資料而來。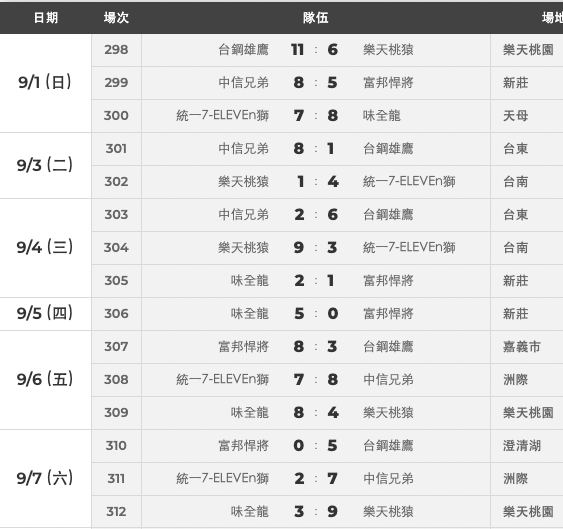
圖/2024 年 9 月賽程,擷取自中華職棒官方網站 https://www.cpbl.com.tw/schedule。
透過昨天所談到的正規化原理,我們可以把賽程比分拆成:
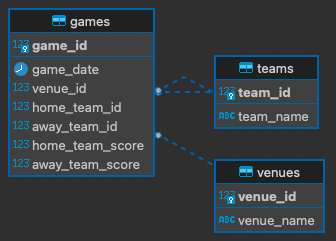
這就是一個線上事務處理系統 (Online Transaction Processing, OLTP),負責處理日常賽事資訊的即時更新操作。事實上,棒球比賽進行當中,每一球發生時都是一個事件,而這些事件都需要即時寫入資料庫,或是找到資料庫裡對應的資料進行修改,當比賽數愈多 (如 MLB 每天有 15 場比賽),加入投球時間限制 (20 秒以內要出手),這個資料庫就越頻繁被讀寫,本質就像是在處理即時發生的交易一樣。
反觀上述的「觀察球隊整體戰績歷來變化」屬於決策分析層級,所需的資料是彙整過後的、含有歷史情況。那我們要怎麼把 OLTP 裏的資料,送進 OLAP 呢?
WITH game_detail AS (
SELECT
g.*,
v.venue_name,
th.team_name AS home_team_name,
ta.team_name AS away_team_name,
CASE
WHEN home_team_score > away_team_score THEN 'win'
WHEN home_team_score < away_team_score THEN 'lose'
ELSE 'draw'
END AS home_result,
CASE
WHEN home_team_score < away_team_score THEN 'win'
WHEN home_team_score > away_team_score THEN 'lose'
ELSE 'draw'
END AS away_result
FROM
games AS g
LEFT JOIN
venues AS v
ON
g.venue_id = v.venue_id
LEFT JOIN
teams AS th
ON
g.home_team_id = th.team_id
LEFT JOIN
teams AS ta
ON
g.away_team_id = ta.team_id
WHERE
g.game_date <= ${CUTOFF_DATE}
),
注意到了嗎?我們想要的截止日期,就是在這段 query 裏面透過 CUTOFF_DATE實現!
home_summary AS (
SELECT
home_team_id,
home_team_name,
COUNT(*) AS total_games,
SUM(CASE WHEN home_result = 'win' THEN 1 ELSE 0 END) AS total_wins,
SUM(CASE WHEN home_result = 'lose' THEN 1 ELSE 0 END) AS total_losses,
SUM(CASE WHEN home_result = 'draw' THEN 1 ELSE 0 END) AS total_draws,
SUM(home_team_score) AS total_run_scored,
SUM(away_team_score) AS total_run_allowed
FROM
game_detail
GROUP BY
home_team_id,
home_team_name
),
away_summary AS (
SELECT
away_team_id,
away_team_name,
COUNT(*) AS total_games,
SUM(CASE WHEN away_result = 'win' THEN 1 ELSE 0 END) AS total_wins,
SUM(CASE WHEN away_result = 'lose' THEN 1 ELSE 0 END) AS total_losses,
SUM(CASE WHEN away_result = 'draw' THEN 1 ELSE 0 END) AS total_draws,
SUM(away_team_score) AS total_run_scored,
SUM(home_team_score) AS total_run_allowed
FROM
game_detail
GROUP BY
away_team_id,
away_team_name
),
stadings AS (
SELECT
COALESCE(h.home_team_name, a.away_team_name) AS team_name,
COALESCE(h.total_games, 0) + COALESCE(a.total_games, 0) AS total_games,
COALESCE(h.total_wins, 0) + COALESCE(a.total_wins, 0) AS total_wins,
COALESCE(h.total_losses, 0) + COALESCE(a.total_losses, 0) AS total_losses,
COALESCE(h.total_draws, 0) + COALESCE(a.total_draws, 0) AS total_draws,
CONCAT(COALESCE(h.total_wins, 0), '-', COALESCE(h.total_draws, 0), '-', COALESCE(h.total_losses, 0)) AS home_record,
CONCAT(COALESCE(a.total_wins, 0), '-', COALESCE(a.total_draws, 0), '-', COALESCE(a.total_losses, 0)) AS away_record
FROM
home_summary AS h
FULL JOIN
away_summary AS a
ON
h.home_team_id = a.away_team_id
)
SELECT
ROW_NUMBER() OVER (ORDER BY total_wins DESC, total_losses ASC) AS rank,
team_name,
total_games,
CONCAT(total_wins, '-', total_losses, '-', total_draws) AS record,
RIGHT(CAST(ROUND(total_wins::DECIMAL / (total_wins::DECIMAL + total_losses::DECIMAL), 3) AS TEXT), 4) AS win_pctg,
home_record,
away_record,
DATE(${CUTOFF_DATE}) AS cutoff_date
FROM
stadings;
也就是說,根據球迷查看時所選擇的截止日期,計算累計戰績分佈時就會只使用截止日期以前的比賽結果計算。但,讓我們思考一下,這個 query 要在什麼時候運行?
我們不需要在收到查詢的當下,進到 OLTP 即時計算。假設今天剛好是戰績快要底定,決定哪些隊伍可以進入季後賽的日子,網站湧入大量球迷查詢戰績,結果導致 OLTP 不堪負荷,反而讓聯盟工作人員無法針對新的賽程比分寫入。
較理想的做法是,在 OLAP 裡面建立一張名為 standings_snapshot 的表 ⮕
CREATE TABLE standings_snapshot (
rank INT,
team_name VARCHAR(50),
total_games INT,
record VARCHAR(10),
win_pctg VARCHAR(5),
home_record VARCHAR(10),
away_record VARCHAR(10),
cutoff_date DATE
) PARTITION BY RANGE (cutoff_date);
CREATE TABLE standings_snapshot_aug_2024 PARTITION OF standings_snapshot
FOR VALUES FROM ('2024-08-01') TO ('2024-08-15');
CREATE TABLE standings_snapshot_sep_2024 PARTITION OF standings_snapshot
FOR VALUES FROM ('2024-08-16') TO ('2024-08-31');
待該日所有比賽結束後,在午夜針對該日以前所有資料計算一次累計戰績分佈並寫入 standing_snapshot。如此一來有幾個好處:
PARTITION,可以直取所需資料,不用大量掃描原始資料再計算。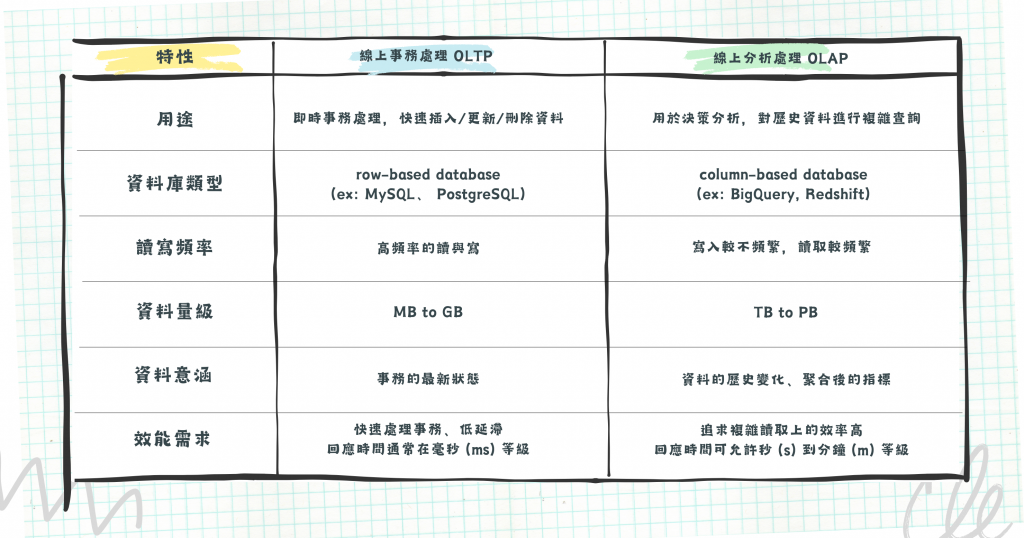
OLTP 系統(例如賽事比分、逐球事件資料庫)是為了記錄和追蹤即時的情況,確保資料的精準性與完整性;而 OLAP 系統(例如累計戰績表)則是通過分析和彙總這些資料,提供更深入的見解,讓使用者一眼就能看出哪隊在這個賽季表現最好,歷來的趨勢又是如何。
本質上,兩種系統所選用的資料庫也有所差異。OLTP 系統關注的是每筆事務能否被完整更新且具有一致性,而 row-based database (如 MySQL、 PostgreSQL) 將每一筆完整的資料存放在一起,非常適合頻繁地插入/更新/刪除操作,是 OLTP 的好選擇。
OLAP 系統則是為了決策分析而設計,時常需要針對特定欄位進行聚合統計算出指標,而 column-based database (如 BigQuery、Redshift) 將同一欄位的資料存放在一起,這樣的結構使得在做 GROUP BY 時效率很高,只需要讀取相關欄位即可,因此為 OLAP 的好選擇。
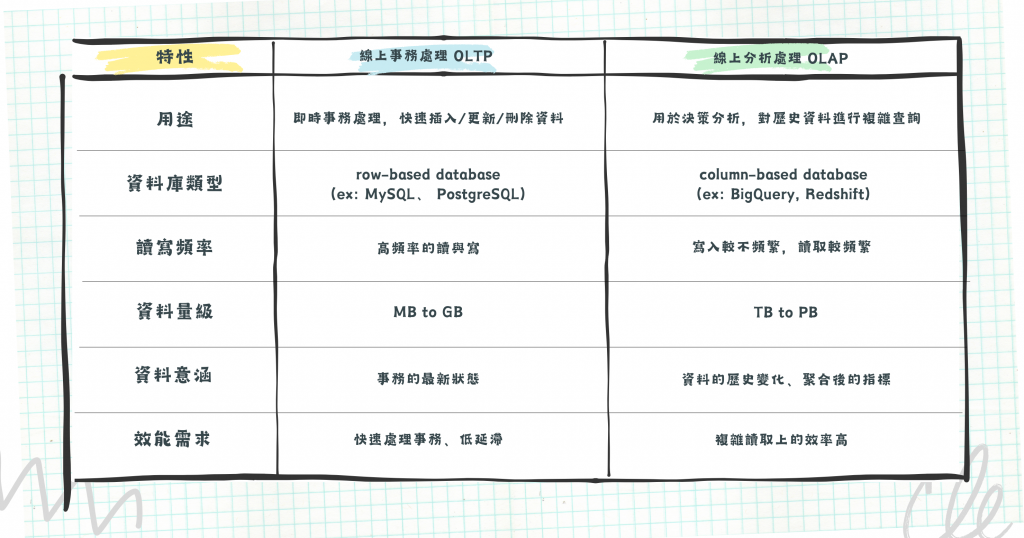
圖/OLTP 與 OLAP 比較。簡書廷製。
今天的故事有提到『待該日所有比賽結束後,在午夜針對該日以前所有資料計算一次累計戰績分布』這個動作,它就是耳熟能詳的資料管線 (data pipeline) 在做的事!詳情我們明天聊!
當然,舉這個例子只是幫助讀者從生活上的小案例理解巨量資料的應用情境,事實上我並無法得知職棒官網背後的資料處理方式,以上說明都是我身為一介資料工程師的推論而已。
再次強調,我舉的例子或許資料量都很小,以目前資料庫的效能絕對是一片蛋糕,可能根本不需要分別建立 OLTP 和 OLAP 系統。能在擁有巨量資料的團隊服務其實很幸運,也才有機會親自釐清 OLTP 和 OLAP 的差異。

