
記得 Day 12 我們談論任務相依性時,介紹了 Airflow 的感應器和觸發器。只不過在任務編排的視角上,我們是以 DAG、task 的層級在討論其關聯。但在資料的世界裡,Airflow 只是任務排程器而已,我們真正關心的是「資料如何流轉」。
我們前兩天針對資料團隊和資料治理的議題討論了一番,最後我們還是聚焦回資料的具體應用上,像是傳統的 RFM 分析吧!它是一個預先定義好規則的 ruled-based 模型,由領域專家針對顧客消費輪廓進行切分。在切分的過程中,其實就是好幾次的資料轉換 (transformation)。如果我們把邏輯弄得複雜,使用的資料源也更多種,那整個資料流轉的過程看起來就會像下面這張圖一樣恐怖。
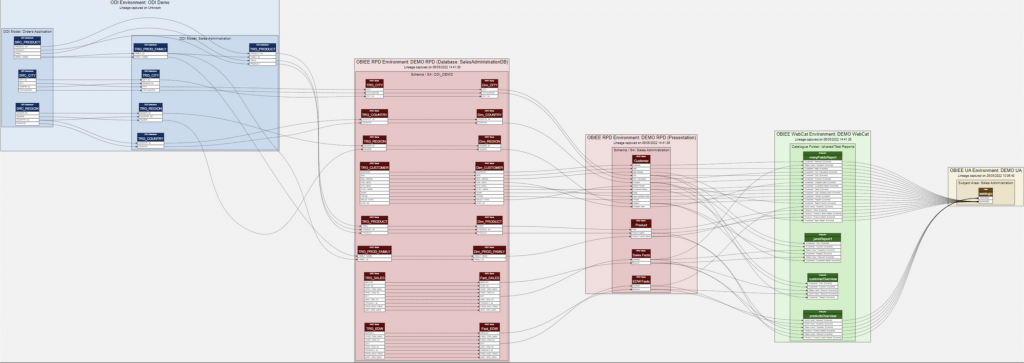
Source: https://www.rittmanmead.com/blog/2022/06/lineage-from-source-table-to/
為了提升資料可靠度,讓應用真的能提升使用者體驗,而不是停留在「我覺得數字怪怪的」的懷疑心理,我們希望從資料源到最終應用的資料繼承關係,包含資料表及資料欄位的層級都能一清二楚,這就是資料血緣 (data lineage)。
垂直血緣 (vertical lineage) 主要關注的是從業務詞彙 (business terms) 到資料 metadata 之間的關聯。例如,商務端想知道某個系統如何記載訂單金額,就需要有個詞典記載 order_amount 欄位儲存的是訂單金額,這樣的詞典稱作語意層 (semantic layer)。
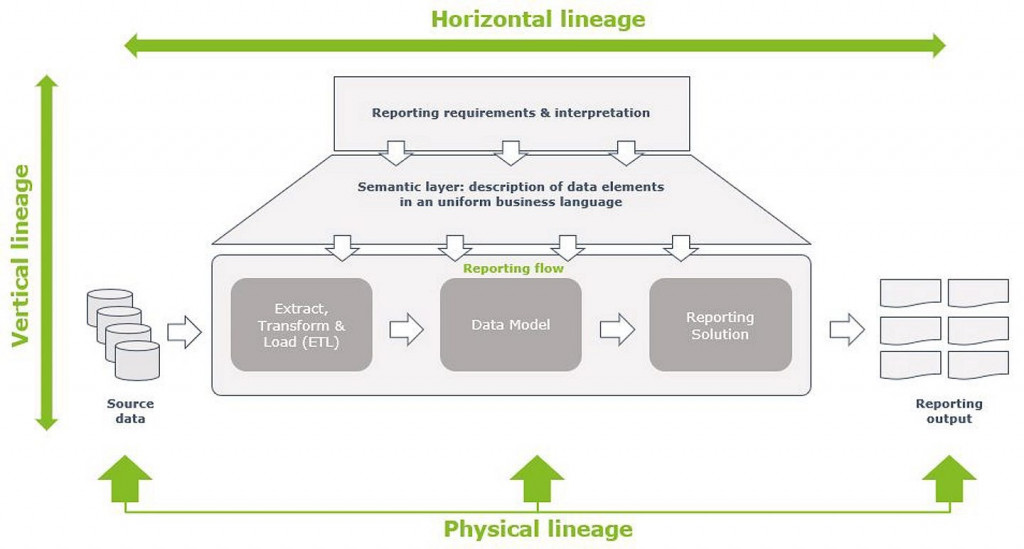
Source: https://www.deloitte.com/nl/en/Industries/financial-services/perspectives/data-lineage.html
垂直血緣有助於非技術人員理解資料表背後的結構與意涵,也讓資料平台建構方理解資料的商業意義,串起了商業端與技術端的相互理解。
水平血緣 (horizental lineage) 則更加聚焦在技術端,它記載資料在跨系統間流動的過程。例如:
訂單最近一次購買距今日數 Recency水平血緣幫助相關開發人員理解資料的來歷及處理方式,以確保資料能夠正確地被提取和使用。
談到資料血緣應該大多資料人都會提到 dbt,不過我親身使用的經驗是,如果最初在設計 data pipeline 時,用了比較多中繼暫存表,要無痛地搬進 dbt 的架構又不改動設計邏輯的條件,有失去 dbt data lineage 控制的可能。
關於倡議資料平台架構重構的經驗,還請參考我在年初寫的文章:
《社群耳朵聽聽看》社群交流筆記|說服其實沒有用?。
因此在系統不大幅重構的前提下,搜尋了以下幾種解法來生成資料血緣。
【特性】
全面性:支持多種資料來源和轉換過程。
可擴展性:能夠整合不同的工具和資料平台。
社群支持:OpenLineage 是活躍的開源專案,資源豐富且有支持。
【開發成本】
高:需要設定和維護 Airflow,整合 OpenLineage 和 Kafka,並且需要大量設定和程式碼。
【效益】
高:Open Lineage Event 是規範化的,能適應多變平台,隨需求變化擴展。
【特性】
整合性:專為 BigQuery 設計。
自動化:自動生成和更新 Data Lineage。
【開發成本】
低:主要依賴 BigQuery 內建功能,開發和設定簡單。
【效益】
中:提供良好 Data Lineage 視覺化,但僅限 BigQuery,無法支援其他平台。
【特性】
直觀:針對 SQL query 解析。
靈活:Dialect-Awareness,支援多種 SQL 資料庫,如 MySQL、Postgres 和 BigQuery 都可以。
【開發成本】
中:依賴 SQL 查詢解析,設定相對簡單。
【效益】
中:能快速生成 Data Lineage,但精確度可能不如專門工具,
資料分析師:『我想要分析顧客的回購率,請問有計算過的資料或原始資料可以使用嗎?』
因為其他工程開發任務,資料工程師沒有太快回應。
於是資料分析師就自行定義了回購率,重新做了一個 Dashboard。
爾後有一天,商務端提問了:『為什麼這個 Dashboard 的回購率,和另外一個分析產品的結果不一樣呢?』
資料分析師&資料工程師:『……』
這種血淚故事屢見不鮮。以下資料運用困境我想很多資料工作者也都碰過:
今天談的資料血緣主題中,垂直血緣能解決資料運用人員的困境 1, 2,水平血緣能解決開發人員的困境 3。透過打造資料目錄 (data catalogue) 記載這些關鍵資訊,可以幫助資料工作者能夠駕馭複雜資料系統,確保衍生資料系統衍生的是商機,而不是困擾。

