本節的問題有兩個︰
要學 PromQL 的原因可能有:
總地來說,就是因為你的公司或朋友正在用 Prometheus 來監控,所以你得跟著學會用。這是一個很實際的原因。
其他好像沒有什麼重要原因了。硬要說的話就是你未來的公司或朋友也是用 Prometheus 來監控。
然後這是個沒什麼炫耀價值的技能。不管是面試工作或跟朋友聊天時,證明你很會寫 PromQL 並不會讓你顯得更厲害。去學 Python 或 SQL 還可以跟別人說我會用 Excel 之外的資料分析工具。
那既然大家都學好 SQL 了,為什麼 Prometheus 不支援 SQL 呢?
因為 Prometheus 所存的資結構不同於一般我們熟悉的關聯式資料庫。它存的是一些指標(比方 CPU 使用率、記憶體使用率、股價等)隨時間改變的數值,而不是表格資料。
當然我們可以把這些指標類比到關聯式資料庫裡,以時間戳記為鍵值。但這樣的做法在常見的使用情境下並沒有比較方便,反而會增加理解上的複雜度。
例如:
cpu_usage
+---------------------+-----------------+
| timestamp | value |
+---------------------+-----------------+
| 2021-01-01 00:00:00 | 1 |
| 2021-01-01 00:00:05 | 2 |
| 2021-01-01 00:00:10 | 2 |
+---------------------+-----------------+
cpu_total
+---------------------+-----------------+
| timestamp | value |
+---------------------+-----------------+
| 2021-01-01 00:00:00 | 4 |
| 2021-01-01 00:00:05 | 4 |
| 2021-01-01 00:00:10 | 4 |
+---------------------+-----------------+
假設我想查 CPU 使用率的相對 5 秒前的變化。我們可以用 SQL 寫
SELECT now.timestamp, (now.value - prev.value) / (now.timestamp - prev.timestamp) / total.value AS cpu_usage_rate_change
FROM cpu_usage as now
JOIN cpu_usage as prev on now.timestamp - 5 = prev.timestamp
JOIN cpu_total as total on now.timestamp = total.timestamp
然而 PromQL 我們只要寫
rate(cpu_usage[5s]) / cpu_total
語法直接拿時間序列(可以想成離散信號或是無窮陣列的有限項)計算,表達了我們要的意思。不需要自己寫 JOIN 和拆裝時間序列。因為大家會在監控系統上查的東很固定,所以 Prometheus 發明了簡單的 PromQL 來表達這些查詢,這樣既方便又能引導使用者用寫出容易優化的查詢。
簡言之
本節的問題有兩個︰
Prometheus 設計上主要是和以下系統互動:
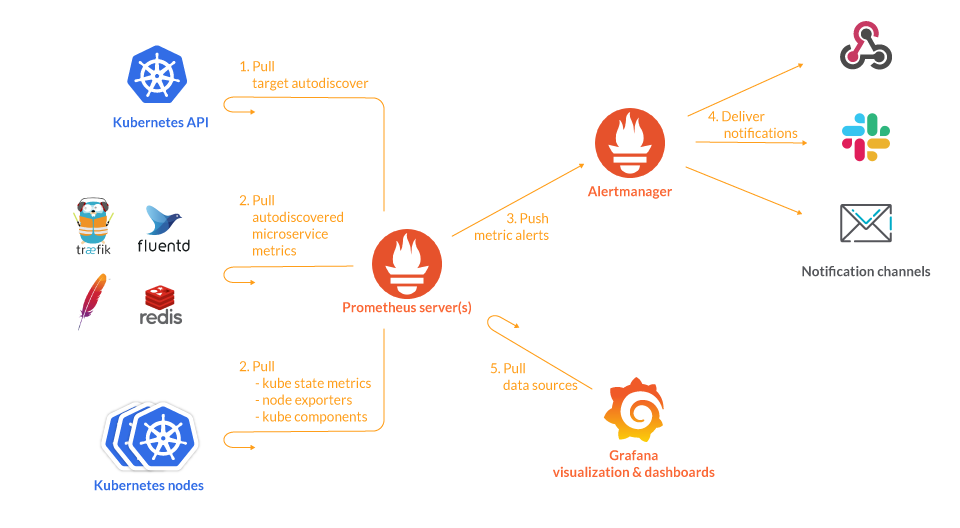
圖片來源:https://sysdig.com/blog/kubernetes-monitoring-prometheus/
這部份大概就是功能整合,支不支援而己,沒什麼效能問題。因為流量不大,也不會要求即時性。
Prometheus 透過 http 端口拉取標的的指標。這個設計是為了讓眾多標的可以不負青推送資料、也就不用維持網路連線和分散式分配推送時機。所以相對簡單可控。
如果標的數量太多,IO 總有硬體限制,就是要水平擴展。
警報規則引擎要不斷檢查指標資料有沒有觸發警報。
警報規則數可以造成效能問題(如果監控人員用腳本工具產生很多規則的話)。
另一個問題是如果做了水平擴展,部署多臺 Prometheus 來分擔負載,那這些 Prometheus 之間要怎麼共享資料和規則檢查資源呢?
Prometheus 提供 PromQL 讀取 API。這有兩點限制:
計算能力方面,Prometheus 提供 recording rules 試圖減低計算上的延遲。
用法是使用者找到需要大量計算而變慢的面版,手動定義出一些計算時用到的中間指標。然後 Prometheus 就會按設定的頻率算出這些中間指標的值。這樣查詢時就可以直接使用算好的中間指標。
圖片來源:https://training.promlabs.com/lessons/recording-rules
上述 recoding rules 還是治標不治本。所以有些公司開發了一些產品,來解決 Prometheus 的問題。
無論 Thanos、Mirmir、OpenTSDB,他們都是要解決資料儲存的問題。做法都是把 Prometheus 的資料寫入他們的資料庫。就好像把手機的照片備份到雲端一樣,Prometheus 是手機,這些產品是大容量圖片資料庫。
這些產品都是解決 Prometheus 的資料儲存效能問題。算是 Prometheus 的下游,同時也都需要另外部署儲存系統。
而 VictoriaMetrics 就比較像是有更多功能整合和客服的商業方案。
本節的問題有三個:
先來說說 OpenTelemetry 和 OpenMetrics 是什麼。
OpenTelemetry 是一個可觀測性框架,訂出泛用於 Log、Metrics、Tracing 的資料傳送流程和方式。目標是讓不同的程式語言和框架上寫出程式碼可以互相溝通,資料可以透過中間件不斷傳遞轉換。
圖源https://observiq.com/blog/how-to-install-and-configure-an-opentelemetry-collector
圖源https://logz.io/learn/opentelemetry-guide/
上面兩張圖是不同人介紹 OpenTelemetry 的內容。有趣的是他們把 Prometheus 放在資料傳送鏈的不同地方。第一張圖把 Prometheus 放在最後一個收集資料的地方,第二張圖把 Prometheus 放在最前面的地方。
因為 Prometheus 在指標層面做了不只一件事。
也就是說,Prometheus 既是資料收集器,也是資料儲存器。是能以一扺三的元老程式。
至於 OpenMetrics,它一個指標的通用格式。某種程度上是將 Prometheus 的指標格式化為一個標準。就好像 GQL 之於 neo4j,Prometheus 的競爭對手甚至更少。OpenMetrics 把從前新軟體宣稱的「Prometheus 相容,學習成本低」概念,落實成「符合 OpenMetrics 標準」鼓勵更多人來接。
總地來說 Prometheus 大家已經很熟,並未脫離框架,嚴然是框架參考它。對小量使用者來說部署又方便,對大量使用者來說效能還夠用,也就繼續用。
就如多數資料庫,Prometheus 的效能瓶頸通常在資料寫入。雖然做為時間序列資料庫,其實只要把資料寫進記憶體,積多時再打成一包寫進檔案系統,好像很容易。但麻煩的是,Prometheus 的資料得用 http 拉來,http 的傳輸自然會流量限制。
一般正常使用場景下(單一地點、數千個標的、各數千項指標),Prometheus 都能順利每數十秒輪詢一遍。但如果跨地區、標的數量增加或是輪詢頻率增加,就會有問題。
這時官方認可的解法是,部署多臺 Prometheus 來分擔負載,然後讓這些 Prometheus 互相拉取第二手資料,來處理警報規則。互接的方式可以是主從式或是對等式,第二手資料雖然數量沒有變少,還有時間延遲,但沒有 http 成本,所以可以接受。
https://prometheus.io/docs/prometheus/latest/federation/
若要做到監控系統的極致垂直效能優化,大概是實體化檢視表。
由監控人員先定出監控面版上的查詢,然後分析查詢有用到哪些指標、每次時間增加時需要哪些數據才能算出面版上改變。其他沒用到的指標數據就不用存了、也不用拉了、甚至最一開始那些標的就不用提供這些指標了。
這樣或許可以改善流量問題,但會增加維護成本。因為每次要改變面版,都要重新分析查詢,重新設定指標,不能回去查過去的資料。雖然我曾聽說 Elastic 要提供這樣的服務,但往往都是做在 OpenTelemetry 的 backend 之後,而不是一路打通到 datasource。大概是因為拉資料的流程必須維持單純,不應太複雜化吧。
Prometheus 垂直整合的效益主要是體現在部署和維護方便上,而不是效能上。
Prometheus 和 PromQL 跟 Kubernetes 結合得好,有很多人用。資料檢索方面如有效能考量,有其他工具可以幫助。
下篇我們要來看,Prometheus / OpenMetrics 的資料型態。

