隨著近年來處理、儲存和分析數據的需求顯著增加,尤其在大數據的增長下,組織必須能快速處理並分析大量數據,以便做出明智的決策並保持競爭力。這就是OLAP計算技術的應用所在。
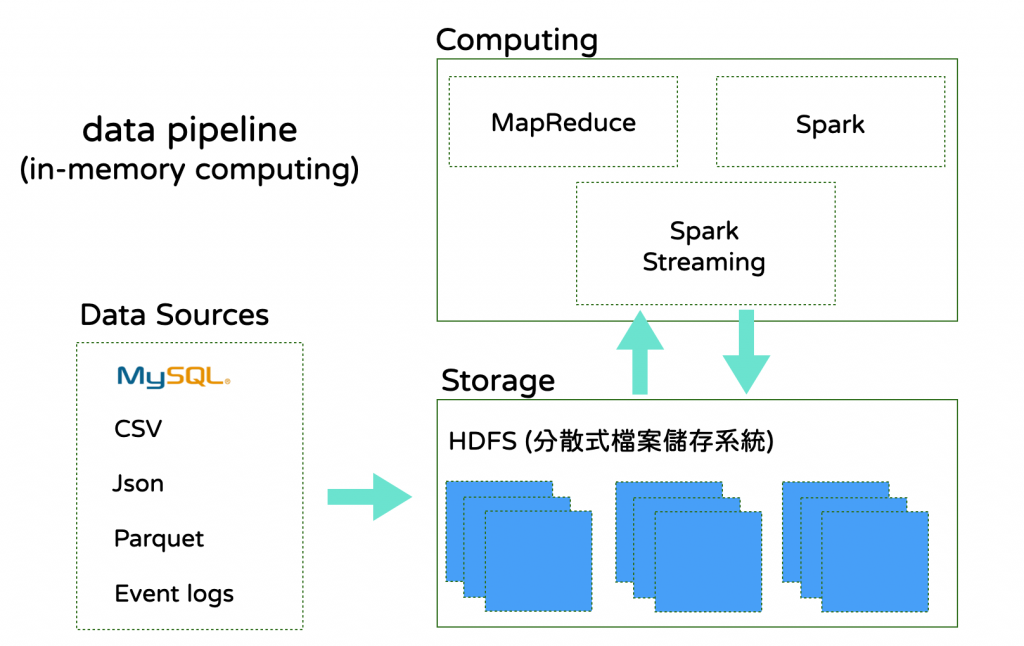
以前的記憶體容量很小,所以計算通常是透過CPU 把資料從硬碟讀進 RAM,把計算拆的很小,一支程式的執行做了部分計算以後存回硬碟,再繼續讀取、計算、儲存。
In-memory Computing 其實概念也一樣,只是能夠在隨機存取記憶體(RAM)讀取處理的資料變多了、能夠計算的複雜度更高了,甚至透過分散式儲存與計算的技術,可以用一個指令處理更大量的資料,而不是從基於磁碟的儲存中讀取數據。
有兩種常見的類型:In-memory Computing 以及 In-database Computing (也有稱為 In-database memory computing)
主要透過把需要做統計分析的大量資料,一次讀取到 RAM 中,直接做統計計算,這類型的計算對於機器的 RAM 大小有較高的要求,也會透過分散式系統來實現更大資料量的計算。
• 支援高度複雜的data pipeline 和多步驟的資料處理
• 適合處理不同來源、結構化和非結構化數據
• 能夠擴展到大量節點進行平行計算,適合處理大數據
• 需要自行管理叢集和基礎設施,運維成本高。
• 學習曲線相對較陡,使用者需要熟悉分散式處理和多種程式工具與 API。
常見的技術框架像是透過 Apache Hadoop 的 HDFS 作為大型分散式的檔案儲存系統, 並透過 Spark來做計算,當時技術剛出來時,被用來替換掉 Hadoop 的 MapReduce,讓 in-memory computing 技術發展往前推進不少,極高的提高計算效率,當時效能對比可以有10倍,甚至20倍的提升效率。
以 HDFS + Spark 來舉例其實過度簡單化了,還有很多實務問題要解,例如資料來源怎麼同步進HDFS、排程、分散式節點的管理,可以參考很多文章都有更深入的說明。
主要特色是簡單透過 SQL就能在資料庫裡面做較高複雜度的資料統計計算。
雖然叫 in-database computing ,實際運作還是讀進資料庫的memory 計算,但使用者的視角來說,是只要下一個 SQL 到資料庫裡面可以直接做計算,和傳統 OLTP 沒有差異,有一些名詞會稱為 in-database memory computing。
• 需要管理的伺服器或基礎設施相對較少
• 能進行大量資料的統計查詢並且速度極快,特別是在資料倉儲和 BI 報告中使用
• 簡單易學,使用標準 SQL 語言就能進行查詢與分析
• 不適合需要高度自定義數據處理或流式數據處理的場景
• 處理較複雜的資料流的支援度較低
其實隨著技術迭代,蠻多資料庫逐漸能支援,但最主要的選型還是會以前幾篇介紹到的 columnar database 最好,有蠻多選擇:
In-database Computing 的選擇主要就是以成本和試用程度考量了,有成熟雲端商提供的服務,可以直接啟用,也有 Open Source的版本,只是你還是需要自己架設機器,但我覺得就沒有得到 in-database computing 不需要維護太多infra 的優點。
我們當時是先選擇GCP BigQuery,原因是:
AWS Redshift 當時沒有以查詢量計價的收費模式,需要每個月直接開一台機器,費用不低,在效益不明的情況下比較難說服主管馬上投入這麼大的金額。
但後來其實踩了一個地雷是我們主要系統資料庫在 AWS 上,我需要另外花力氣把資料從 AWS 轉移到 GCP,這又是另一個故事了。
在OLAP計算架構 In-memory Computing 與 In-database Computing 的選擇思考上,我的個人觀點是:
如果你的公司在初期導入的階段,想要取得小成功,或是先做成效的驗證,那麼我會建議先採用 In-database Computing 的做法,等到取得一定成效,發現在資料處理的計算環節有更深入的需求,則可以開始思考導入 In-memory Computing的技術。
而這個技術選型其實也會決定你接下來的資料流要選擇 ETL 還是 ELT,我們明天見~

