上一篇用比較精簡的方式介紹了一個好的資料表的設計,接著來聊聊 MySQL 的系統結構以及如何做SQL 查詢的優化。
如果你對於電腦的執行有些了解,你已經知道記憶體和硬碟的差異。
記憶體的容量不大,但是讀取速度非常快,而硬碟的容量很大,讀取速度比記憶體來得慢,資料庫需要儲存非常大量的資料,而這些資料大多數會以硬碟頁的形式被存放在硬碟中,最理想的情況當然是把所有資料都存在記憶體,這樣讀取速度最快,但成本非常高。
所以為了加快查詢速度,我們會從中抽取少量的資料,讓我們能讀取到記憶體中,幫助我們快速去對應硬碟的資料,也就是建立索引 (Index),以及透過B+ Tree這樣的結構來儲存索引,幫助我們提高搜尋的效率。
如果你做過效能優化,應該對於索引不陌生,遇到查詢效能比較慢,通常會去看一下有沒有建索引,然後就加個索引。
索引和資料的關係簡單說,索引就像是一本書的目錄,資料就是書的內容,透過目錄可以幫助你更快找到你需要的內容在什麼位置,讓你不需要看過所有書的一字一句才能找到目標內容。
索引是一個概念,目的是幫助你更快找到資料,而實現方式有非常多種,核心理念就是有效率的排序&搜尋,就是資訊科系大二的必修硬課『資料結構』,可以透過 Hash Table、Ordered Array,以及接下來重點介紹的 B+ Tree。
B+ Tree 是從傳統二元樹的資料結構發展而來,二元樹很簡單,每一個節點有兩個子節點,不斷往下生長,但他並不適合資料庫使用,因為我們還需要額外的**pointer (指標)**指向真正在硬碟的資料頁。
註記: pointer(指標) 是一個值,用來儲存記憶體位址,概念像是門牌號碼,透過這個值可以讓程式直接從記憶體位址抓到上面儲存的資料。
為了解決資料庫的問題,因此誕生了 B+ Tree,他有幾個特色:
如果你在MySQL 資料庫裡面選擇一個欄位建立 index ,他就會幫你建出這樣的一棵 B+ Tree,再透過 Tree Traversal 演算法來幫助你的搜尋更有效率,找到指定位址以後,再到硬碟裡去抓出你要的資料內容,演算法的細節就不再贅述。
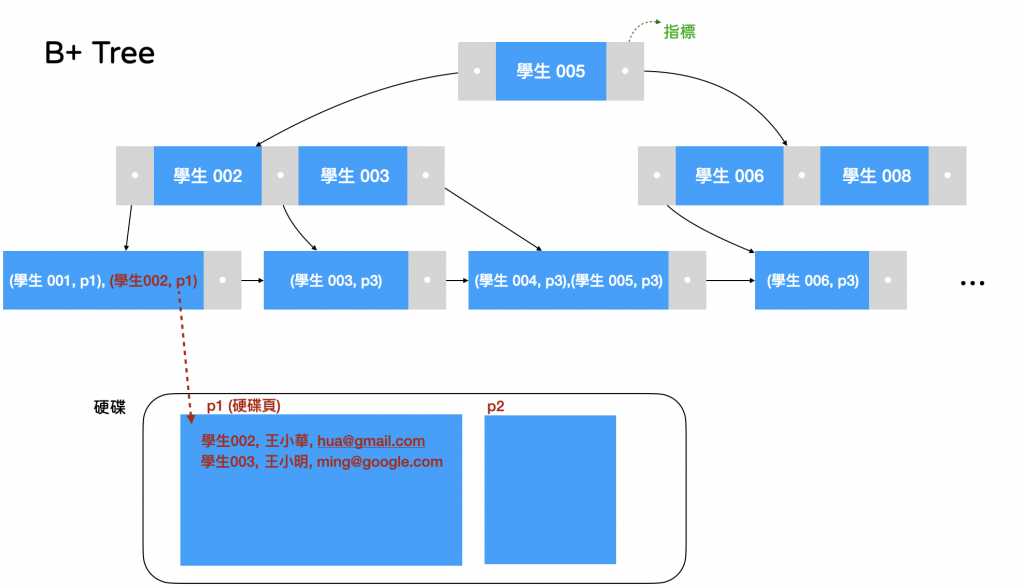
看完了 Index 在MySQL 裡的儲存結構,你應該明白為什麼這樣的結構可以幫助你加速搜尋效率了,原本十萬筆的資料,你需要從第一筆搜尋到第十萬筆,要比對10萬次,但有了 B+ Tree,只需要 5次就能快速鎖定範圍、縮小範圍後再循序找到目標。
因此在有效率的SQL 撰寫上,最重要的關鍵就是在 WHERE 記得盡可能的使用到已建立 index 的欄位。
建完索引以後也不是一勞永逸,其實隨著使用時間還是會產生一些問題,這邊舉一個例子:資料庫的日常使用一定會不斷的刪除資料、新增資料,時間一久,可能會導致你的 index 估算失誤,這時候如果你的資料表有多個索引,他可能會選擇估算效率比較好,但其實效率比較差的索引。
資料庫在執行一個查詢之前,會先透過區分度做估算,也就是你的index 有多少不同的值,不同的值越多,區分度就會越高,代表你可以更有效率找到你要的資料,最大區分度的例子就是 id ,每個值都不同。
所以當資料庫使用一段時間,尤其又針對某個特定範圍值刪除,新增某個範圍值的時候,會導致你某個範圍的資料數量特別多,導致他的估算失準。
改善的方式也很簡單,讓MySQL 依據你現有的資料重新去做一次估算就可以了。
analyze table <table_name>;
這篇文章主要希望讓大家能透過 MySQL 關聯式資料庫系統底層的設計,更了解在資料結構演算法中針對『排序』、『搜尋』的應用,以及提升 SQL 查詢效能的超級心法『WHERE一定要用到index』,而MySQL 的實戰還有非常非常多有趣的問題,如果有興趣的也很鼓勵大家去深入閱讀:
中山大學資管系黃三益教授的《資料庫的核心理論與實務》
下一篇我們就會進入 OLAP的設計範圍了,我們明天見。

