
在昨天的文章中,描述了機器學習開發專案的流程,大致可分成三個部分:
其中各部分的設計、設備配置需求並不相同,因此在組合出一個實用 MLOps 系統時,就需要考慮到不同功能如何串接以及選擇適當的部署設備。此外,為了快速部署的需求,多數的功能或服務是部署在 Docker 容器中,讀者可以根據需求做調整。接下來,本文將以功能串接為主、設備考量為輔,帶領讀者了解各流程中 MLOps 系統的設計思路。
試想一下,如果沒有 MLOps 系統,開發團隊如何做模型開發?我們或許會在各自的電腦中,建立一個開發環境,然後各自將原始資料導入後,製作不同的訓練資料、模型,並將這些程式碼、資料、模型、甚至比較表格以檔案命名的方式區分版本,最後儲存在團隊的共同資料夾裡。如果要將這個流程優化,那麼,就需要改善我們的開發環境,利用前面提到的套件,滿足最初提到的基本功能需求。
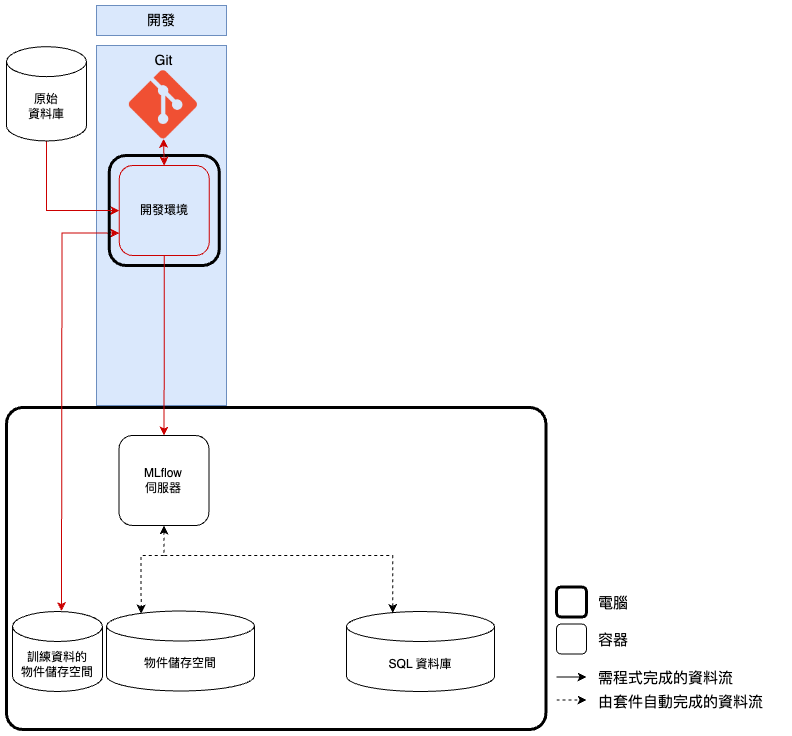
既然我們的目標是改善 開發環境,那麼開發時的功能設計(如下圖)便會圍繞著它做串接,而且通常可以延用原本的 GPU 開發環境 ,只需再串接 MLOps 系統的功能即可。依照模型開發的步驟,首先會希望原始資料可以透過 原始資料庫 統一管理,這個資料庫可以是一個外部服務,比如客戶的數據庫,然後將 開發環境 與其串接以取得原始資料。接著,會在 開發環境 做資料前處理,並將處理好的訓練資料透過 DVC 管理不同版本,DVC 會將各版本訓練資料儲存到 訓練資料的物件儲存空間 ,比如 MinIO 、 Amazon S3 、 Google Cloud Storage,以供團隊成員調用。
再下來我們會在 開發環境 執行模型開發,並將開發結果串接到 MLflow 伺服器 統一管理, MLflow 伺服器 會自動將模型檔、環境檔等「檔案」儲存到 物件儲存空間 ,將超參數、模型分數等「訊息」儲存在 SQL 資料庫 ,比如 Postgres 、 MySQL。最後,將模型開發的程式碼透過 Git 做版本控制,甚至上傳到 GitHub/GitLab 平台做共同管理。如此,便是依照專案流程完成了套件功能的串接。
完整內容 >> https://bit.ly/3zpUBwY
Line 官方帳號,看最新技術文章:https://user137910.pse.is/aif2024ironman
撰稿工程師:許睦辰
