
相較於 Tensorboard 與 Weight&Biases,MLflow 更著重於「公司內部的多人專案」的實驗管理上,主要讓工程師自己建立屬於公司內部的 MLflow 伺服器。MLflow 著重在三個面向:專案、數據追蹤、模型,它可以使中小型團隊在免費的情況下輕鬆管理每個專案、實驗與模型,MLflow 一樣有可視化的參數比較,也有搜索模型的功能,可以協助團隊在眾多的實驗底下,找出評估指標最優秀的模型。
如下圖所示:Experiments 可以是團隊正在進行的專案,中間區域是該專案底下的各種實驗,可以紀錄實驗日期、實驗者、模型指標…等等,可以透過 “Sort” 找出評估指標最好的模型。
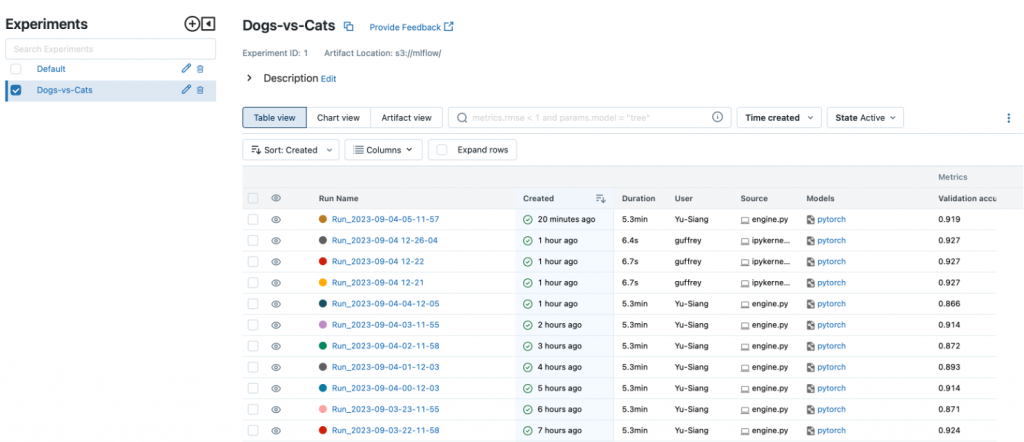
圖片:Mlflow ui 介面
往下點擊每個實驗,可以觀察到紀錄的參數,從Metrics往下點擊可以可視化數值,在Artifacts可以儲存本次實驗的環境需求與模型,方便之後復刻(追蹤)結果與模型部署。
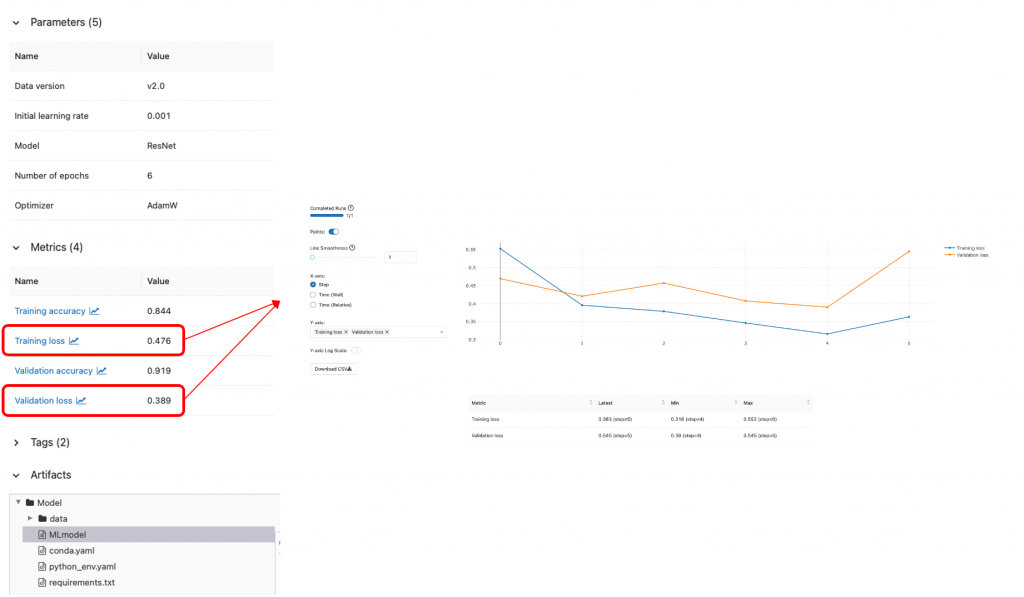
圖片:Mlflow 實驗紀錄
** 注意如果要使用MLflow儲存模型(Artifacts)建議串接資料伺服器(s3, minIO….)
如何在Python開發環境使用,以及程式碼需要如何撰寫:
工具安裝:
pip install mlflow
本地端啟動:
在終端機輸入:mlflow ui
程式碼撰寫:(以一個簡易的資料做示範)
import os
from random import random, randint
import mlflow
from mlflow import log_metric, log_param, log_params, log_artifacts
mlflow.set_tracking_uri("http://127.0.0.1:5000")
if __name__ == "__main__":
# Log a parameter (key-value pair)
log_param("config_value", randint(0, 100))
# Log a dictionary of parameters
log_params({"param1": randint(0, 100), "param2": randint(0, 100)})
# Log a metric; metrics can be updated throughout the run
log_metric("accuracy", random() / 2.0)
log_metric("accuracy", random() + 0.1)
log_metric("accuracy", random() + 0.2)
# Log an artifact (output file)
if not os.path.exists("outputs"):
os.makedirs("outputs")
with open("outputs/test.txt", "w") as f:
f.write("hello world!")
log_artifacts("outputs")
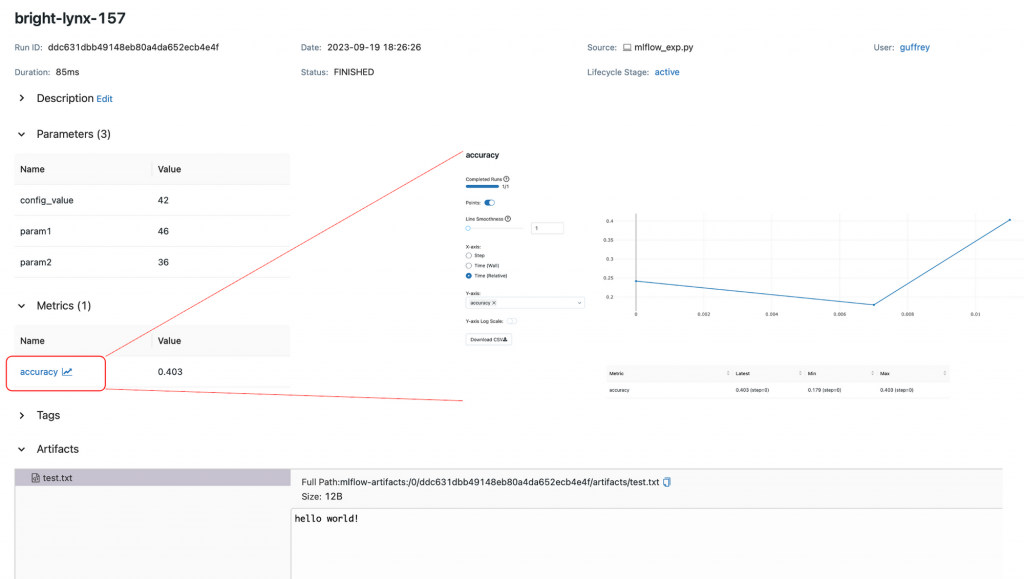
圖:MLflow 範例
參考文獻
1.初探mlflow-tracking-保持ml實驗的可追溯性與可重現性-
2.Weights & Biases — ML 實驗數據追蹤
(撰稿工程師:顧祥龍)
完整內容 >> https://bit.ly/4huT5Li
Line 官方帳號,看最新技術文章:https://user137910.pse.is/aif2024ironman
