requests 模組是 Python 中用來發送 HTTP 請求的工具,能夠從網頁上下載資料。因為 requests 是第三方模組,所以需要在終端機先下載此模組(輸入紅框處指令):

requests.get() :print(response.text):response.text 會回傳伺服器回應的內容(即 HTML 原始碼),並將其轉換為 Python 字串。print(response.status_code):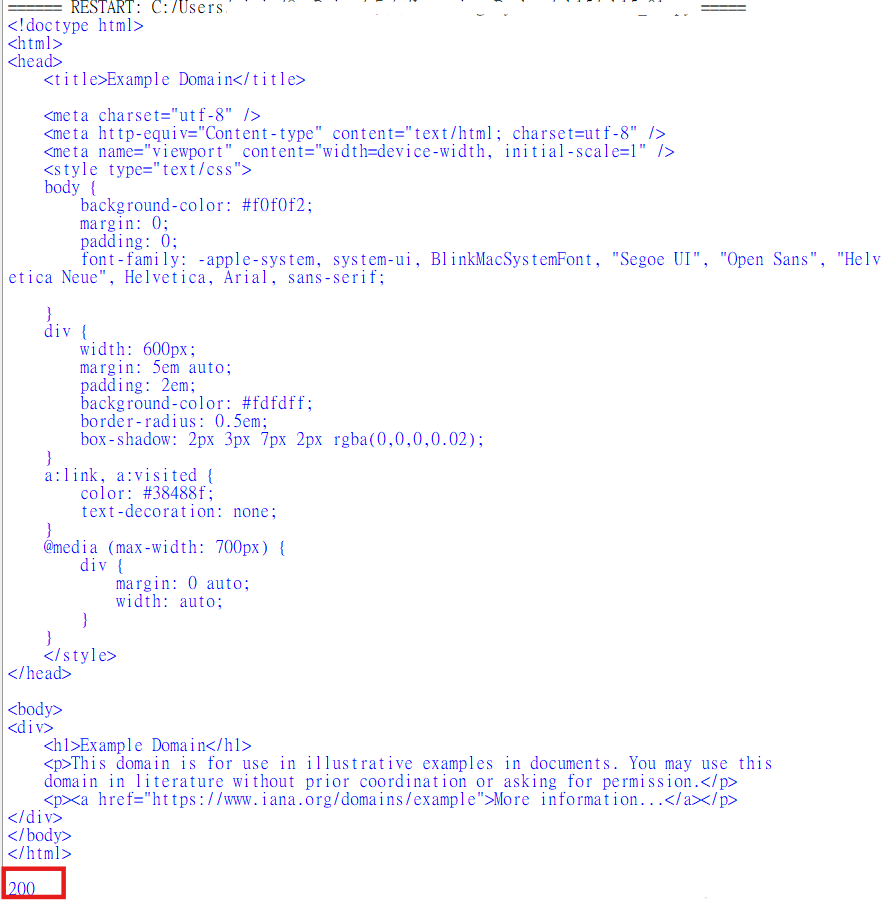
狀態碼 200:表示請求成功,伺服器正常回應。(輸出圖的紅框處)
狀態碼 404:表示網頁不存在,伺服器找不到資源。
狀態碼 500:表示伺服器內部錯誤。
在爬蟲中,伺服器可能會阻止我們的請求,因此需要進行異常處理,避免程式中斷。這時可以使用 try-except 來處理網頁下載失敗的情況。

try:
try 區塊要放的是可能會出錯的程式碼,如果在執行的過程中遇到錯誤,Python 會跳到對應的 except 區塊來處理該錯誤。
response.raise_for_status():
這裡是用來確保請求是成功的,raise_for_status()會檢查 response 物件中的 HTTP 狀態碼。如果狀態碼顯示有錯誤(如 404 或 500),它會丟出一個 HTTPError 例外,然後轉到 except 區塊。
requests.exceptions.RequestException:
泛指所有例外類別,包括了所有與 HTTP 請求有關的錯誤,如網路超時、找不到網頁、無法連接伺服器等。
as e:將捕捉到的例外(錯誤)訊息儲存在變數 e 中,方便後續處理。

BeautifulSoup 被用來解析 HTML 文件的 Python 資料庫,可以提取 HTML 中的內容。

建立 BeautifulSoup 物件:
先用 requests 取得網頁內容,再用 BeautifulSoup 解析。而 html.parser 是內建的解析器,適合解析 HTML。
soup.title.text:
用來尋找 title 標籤,並透過 .text 提取出標籤中的文本(通常是網頁的標題)。
soup.find('title'):
find() 方法用來尋找 HTML 中第一個符合的標籤,這裡要找的也是 title 標籤(與 soup.title 的效果相同)。
soup.find_all('a'):
find_all() 方法用來尋找 HTML 中所有符合的標籤,這裡會返回所有的 a 標籤(即網頁中的超連結)。

- Example Domain 是 example.com 頁面的標題(由 title 標籤定義)。
- 當
print(soup.title.text)輸出 Example Domain,代表成功請求了 example.com 網頁並解析了 HTML,但因為該頁面沒有超連結,所以輸出結果不會看到任何超連結。
有時候我們只需要抓取網頁中某些特定的部分,比如某個區塊的文字或圖片。可以使用 BeautifulSoup 的 select() 方法來選擇指定的 HTML 元素。

選取所有段落 (p 標籤):soup.select('p'):select() 方法能使用 CSS 選擇器來選擇 HTML 元素。這裡的 'p' 是一個 CSS 選擇器,它選擇所有的 p 標籤(通常代表段落)。
選擇所有書籍的標題:soup.select('h3'):這裡使用了 CSS 選擇器 'h3',表示選擇所有 h3 標籤。title.get_text():和段落的操作一樣,使用 get_text() 來提取每個書籍標題的純文字並印出來。
抓取所有書籍封面的圖片連結:soup.select('img'):CSS 選擇器 'img' 用來選取所有的 img 標籤(通常代表網頁中的圖片)。img.get('src'):每個 img 標籤都會有一個 src 屬性,這個屬性指定了圖片的來源 URL,我們需要提取並印出每個圖片的連結。

之前我對網頁背後的運作方式完全不熟悉,只知道網頁能顯示漂亮的文字和圖片,但不知道如何透過程式來抓取這些資料。一開始還覺得爬蟲有點「黑客」的感覺,像是要侵入網頁一樣(其實完全不是這回事!)。
我先從最基礎的學起,了解到爬蟲的第一步是發送 HTTP 請求,這個部分用到了 requests,簡單明瞭,但一開始還是有點困惑為什麼要這樣做。後來發現,原來每次我們瀏覽網頁時,瀏覽器就在背後自動幫我們發送請求並接收回應,而爬蟲則是我們用程式去模擬這個過程。
接下來學到用 BeautifulSoup 來解析 HTML。這個過程像是在整理一堆亂七八糟的文件,然後再用 CSS 選擇器來精準地找到我想要的資訊,真的大幅增加了找資料的速度!
因為今天接觸到比較難的東西,所以需要一點時間消化~明天會繼續學習爬蟲比較進階的部分,然後搭配小專題,把這兩天所學的爬蟲技巧實際運用看看><

