Pandas 模組在資料科學與 AI 研究中非常重要,特別是對於結構化的資料,它提供了處理資料的方法,如表格和數據集。接下來會針對幾個與 AI 相關的小節,簡單介紹 Pandas。
(需要先在終端機輸入 pip install pandas)
Pandas Series 是一種類似一維陣列的資料結構,可以透過 list、dict 或是 numpy array 建立。它是 DataFrame 的基本單位,適合用來表示單一列的數據,比如一個 AI 模型中的特徵數據。


使用 Numpy 的 ndarray 來創建 Series,對於處理數據流很有幫助,尤其當我們有數據表時,每一個欄位或特徵都可以當作一個 Series 來看。
Pandas DataFrame 是一種二維資料結構,由多個 Series 組成。每個欄位都有對應的列標籤(索引)與欄標籤(欄位名稱),所以 DataFrame 很適合用來儲存和操作大型資料集。

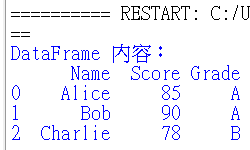
使用一個字典來創建 DataFrame,每個鍵(key)對應一個欄位名稱、每個值(value)對應該欄位的數據,這個方式適合用來處理結構化資料。
Pandas 提供了許多資料分析的工具,比如數學運算、邏輯運算和資料清理功能。在 AI 研究中經常需要處理缺失資料(NaN),進行數據篩選,以及應用統計分析。


使用 Pandas 的 Series 進行基本的加法運算,並進行邏輯運算來篩選符合條件的數據。
我們經常需要將數據從外部檔案讀入程式或將數據存回檔案,Pandas 也有適合的工具來讀取和寫入 CSV、Excel 等格式的檔案。

pd.read_csv 讓我們能比較容易的讀取 CSV 格式的檔案,並轉成 DataFrame。它也可以快速分析和處理大量的數據,而在 AI 領域中,數據集通常以這種格式存在。
資料可視化對於 AI 研究也非常重要,Pandas 提供了許多簡單的繪圖方法,能幫我們直觀的理解數據。
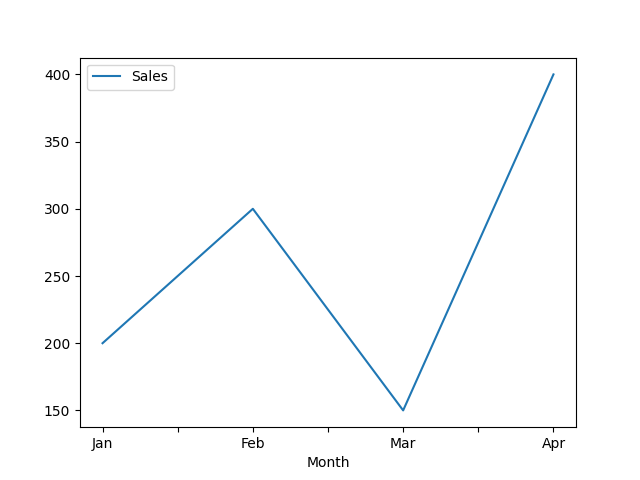

這裡使用 pd.DataFrame 進行資料的可視化,而折線圖能幫助我們分析時間序列資料,這對於預測模型非常有幫助。
之前訓練 AI 模型時,都會在程式開始的地方看到 import Pandas,終於學到這個看過很多次的程式碼了><
無論是對資料的預處理、分析,還是視覺化,Pandas 都提供了簡單且容易使用的工具。可以利用它快速建構、整理數據,進而更專注於 AI 模型的訓練和優化。
今天先學到 Pandas 的基本操作和應用,明天會做小專題來進行比較複雜的應用~

