Kubernetes 最重要的資源之一是負責管理容器的 Pod。作為應用程序的最小部署單元,理解 Pod 的運作方式對於掌握 Kubernetes 的各種特性至關重要。接下來,我們將從 Pod 開始,深入了解其核心概念及特性。
在 Kubernetes 中,Pod 是應用程序或其組件的最小部署單元。這意味著無論是單個容器應用還是多個協作容器,它們都封裝在一個 Pod 中。Pod 是 Kubernetes 直接管理的最小實體,而非單個容器。
Pod 可以看作是運行在同一個執行環境中的一組容器,它們共享相同的資源和網路配置。這為容器的協作運行和管理提供了便利。
在大多數情況下,一個 Pod 包含單個容器。這種情況適合運行簡單的應用,例如 Node.js Web 服務器或 MySQL 資料庫。即使 Pod 內只有一個容器,它仍然能夠享受 Kubernetes 的完整功能特性,包括:
Pod 會提供容器所需的所有資源,如 CPU、記憶體、網路和存儲卷。這使單容器 Pod 成為 Kubernetes 中簡單且強大的部署單元。
有些應用需要多個容器協同工作,這時候多容器 Pod 就非常適用。多容器 Pod 典型的設計模式是運行彼此緊密協作的應用組件,例如主應用和輔助服務。這些容器之間需要共享網路和存儲環境,並且經常需要直接通信。Pod 提供了一個自然的協作環境,確保這些容器能夠高效地運行。
例如,假設有一個主應用容器,負責處理請求;同時還有一個輔助容器,負責監控日誌或管理緩存。這些容器可以在同一個 Pod 中運行,並且共享相同的資源,從而確保它們之間的協同工作
在 Kubernetes 中,每個 Pod 都有自己唯一的 IP 地址,並且 Pod 內的所有容器共享這個 IP 地址和網路命名空間(Network Namespace)。這使得 Pod 內的容器能夠通過 localhost 進行通信,就像它們運行在同一個機器上的同一個網路介面中一樣。
Pod 的網路特性包括:
共享 IP 地址:Pod 內的所有容器共享同一個 IP 地址,這使得它們之間的通信可以直接通過 localhost 進行,而無需通過外部網路。
共享端口空間:Pod 內的容器共享相同的端口空間。這意味著,一個容器在 localhost:8080 上運行服務時,其他容器也可以直接通過該地址訪問。例如,如果一個容器在 localhost:8080 上暴露了一個 Web 服務,其他容器可以直接通過該地址訪問該服務,無需任何額外的網路配置。
儘管 Pod 內的容器共享網路空間,Pod 與 Pod 之間的網路是隔離的。這意味著一個 Pod 無法通過 localhost 訪問另一個 Pod。要實現跨 Pod 的通信,必須使用 Pod 的 IP 地址或通過 Kubernetes 的 Service 資源來進行。
這種設計保證了 Pod 內容器的緊密耦合和 Pod 之間的鬆散耦合,從而提高了應用程序的靈活性和安全性。例如,在多層微服務架構中,每個服務可以在自己的 Pod 中運行,而它們之間的通信通過明確的網路策略進行控制。這樣既提供了容器間的高效協作,又增強了整個系統的可維護性與安全性。
在 Kubernetes 中,Pod 內的容器可以共享一個或多個 存儲卷(Volumes)。這些存儲卷可以來自多種存儲後端,例如本地磁碟、NFS(網路檔案系統)或雲端存儲。Pod 內的多個容器可以同時掛載這些存儲卷,從而實現數據共享和持久化。
持久化存儲:存儲卷允許容器持久化數據,即使容器重啟,數據依然保留不變。這對於需要保存狀態的應用程序(如資料庫)非常重要。
數據共享:多個容器可以同時掛載同一個存儲卷,共享數據。例如,一個容器負責生成數據,另一個容器負責處理這些數據。它們可以通過共享的 Volume 協作,無需依賴外部通信機制。
Kubernetes 支持多種類型的存儲卷,每種存儲卷都有其特定的使用場景:
emptyDir:這是 Pod 啟動時自動創建的空目錄,當 Pod 被銷毀時,數據也隨之消失。因此,emptyDir 適用於臨時存儲需求,例如緩存或臨時文件。
hostPath:將主機文件系統中的目錄掛載到 Pod 內的容器中,這通常用於需要訪問主機資源的場景。例如,監控應用可能需要從主機讀取日誌文件。
PersistentVolume(PV):結合 PersistentVolumeClaim(PVC) 使用,提供持久化存儲。這類存儲通常來自外部存儲系統,如 NFS、Ceph 或雲端存儲(如 AWS EBS)。PV 提供持久性,即使 Pod 被銷毀,數據仍然會保留在存儲中。
以上是 Kubernetes 中一些常見的 Volume 類型,我們將在後續章節中深入討論各類型的具體用途和配置。
在 Pod 內,容器之間可以通過多種方式進行通信和協作:
localhost 網路通信:由於 Pod 內的容器共享相同的網路命名空間,它們可以通過 localhost 和相應的端口進行通信。例如,一個容器可以在 localhost:8080 上運行 Web 服務,另一個容器可以通過該地址直接訪問這個服務。
共享文件系統進行數據交換:Pod 內的容器可以通過共享的存儲卷進行數據交換。例如,一個容器將日誌寫入共享的 Volume,另一個容器可以即時讀取這些日誌,並進行處理或轉發。這種方式無需通過網路即可實現高效的數據共享。
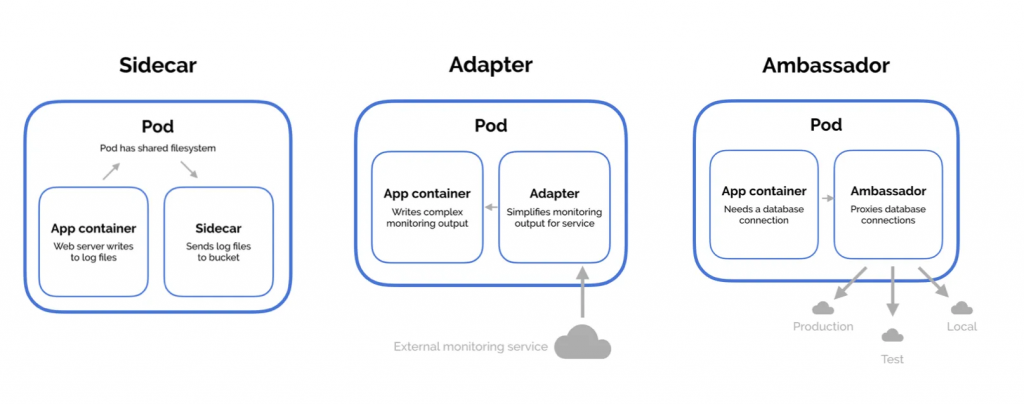
在前面的章節中,我們提到 Pod 中的多個容器常常扮演協作的角色。這種協作使得應用程序的架構更加靈活和複雜,能夠實現不同的應用場景。常見的容器協作模式包括:
這些協作模式使 Kubernetes 能夠靈活支持不同類型的應用程序架構。應用設計者可以根據具體需求選擇合適的模式,從而提高應用程序的可維護性、擴展性和穩定性。
Pod 的生命周期由多個階段(Phases)組成,每個階段代表了 Pod 在 Kubernetes 集群中的不同狀態。理解這些階段有助於診斷 Pod 啟動或運行過程中的問題,從而進行有效的排查和故障處理。
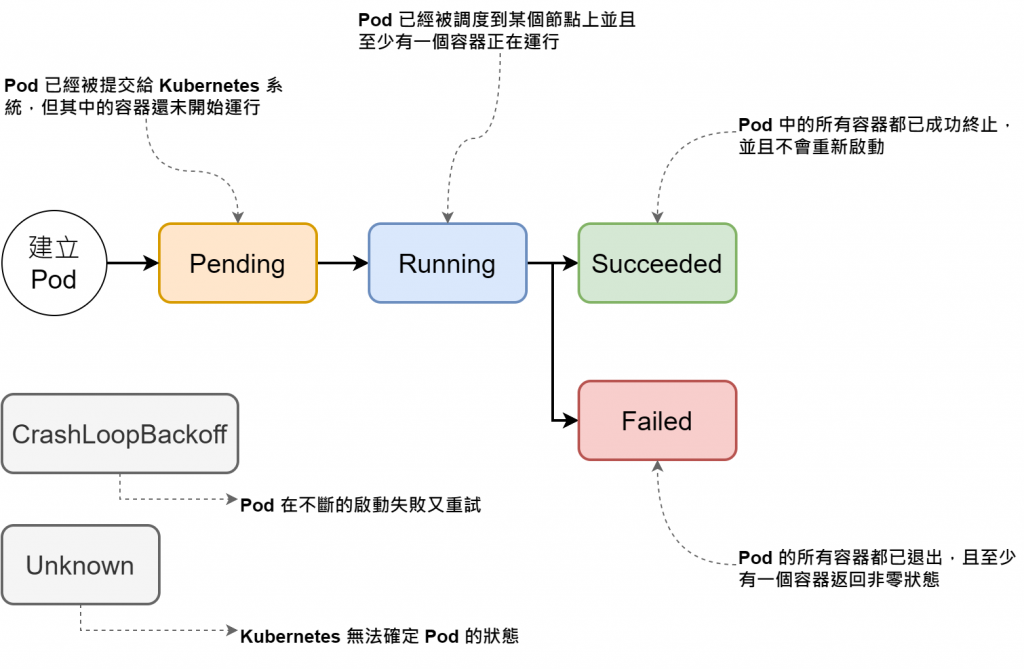
在 Kubernetes 中,Pod 的狀態可以分為以下幾個主要階段:
Always 或 OnFailure 時,Pod 的容器無法穩定啟動。簡單來說, Pod 一直「起不來」,可能需要檢查容器日誌來排查問題。除了 Pod 的整體階段外,Pod 內的每個容器也會有自己的狀態,這些狀態可以幫助診斷容器的具體問題。主要的容器狀態包括:
Waiting:容器尚未開始運行,通常在容器正在等待某些資源或依賴時出現。等待狀態下的容器可能正在等待鏡像下載或資源分配。
Running:容器已經在節點上運行,這意味著容器處於活動狀態並且正常工作。
Terminated:容器已經完成運行並且已終止,無論是正常退出還是由於錯誤導致的退出。這個狀態下,可以查看容器的退出代碼來確定是正常完成還是發生了故障。
理解 Pod 和容器的各種狀態,可以幫助快速排查 Kubernetes 集群中的問題,並確保應用程序的穩定運行。
Kubernetes 提供了健康檢查探針來監控 Pod 內容器的健康狀況,這些探針能夠幫助 Kubernetes 決定何時重啟容器、何時從服務中移除 Pod 或何時允許流量進入 Pod。目前支援三種探針:
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 3
periodSeconds: 5
startupProbe:
exec:
command:
- "cat"
- "/tmp/ready"
initialDelaySeconds: 10
periodSeconds: 10
在 Kubernetes 中,Pod 可以設置資源請求(Resource Requests)和資源限制(Resource Limits)來管理容器對 CPU 和內存的使用。這些設置確保集群資源的合理分配並防止單個 Pod 過度消耗資源。
resources:
requests:
memory: "256Mi"
cpu: "500m"
resources:
limits:
memory: "512Mi"
cpu: "1"
當 Kubernetes 調度器選擇節點來運行 Pod 時,它會考慮資源請求,以確保節點有足夠的資源來滿足 Pod 的最低需求。而資源限制則在 Pod 運行時生效,以防止 Pod 消耗過多資源。
這些機制確保了 Kubernetes 集群資源的合理分配,防止資源爭奪並保證集群穩定性。
Pod 的重啟策略(Restart Policy)定義了 Kubernetes 在容器失敗或退出後應如何處理。這是保持應用高可用性的關鍵機制之一。Pod 的重啟策略有三種選擇:
restartPolicy: Always
restartPolicy: OnFailure
restartPolicy: Never
標籤是 Kubernetes 中的一種鍵值對,用來標識和組織 Pod 及其他資源。標籤是附加在 Pod 等資源上的元數據,用於描述資源的屬性,例如應用名稱、環境、版本等。標籤非常靈活,允許用戶按照需求進行自由標註。
app: web-server 或 env: production。app.kubernetes.io/name),但這不是必需的。metadata:
labels:
app: my-app
tier: backend
version: v1
選擇器用來查找和選擇符合特定標籤條件的 Pod 或其他資源。這是 Kubernetes 中控制器(如 ReplicaSet、Deployment 和 Service)管理 Pod 的主要方式。
spec:
selector:
matchLabels:
app: my-app
tier: backend
親和性規則用於影響 Pod 在叢集中如何調度到節點上。這些規則允許你指定 Pod 與其他 Pod 之間的調度關係,以優化性能和可靠性。親和性規則分為硬性規則(必須遵守)和軟性規則(優先考慮,但可忽略)。
nodeSelector,但更靈活。requiredDuringSchedulingIgnoredDuringExecution(硬性規則)或 preferredDuringSchedulingIgnoredDuringExecution(軟性規則)。affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
labelSelector:
matchLabels:
app: my-app
topologyKey: "kubernetes.io/hostname"
反親和性規則用來防止某些 Pod 被調度到同一節點上,這在高可用性場景中特別有用。例如,可以使用 Pod Anti-affinity 確保同一應用的多個副本不會運行在同一節點上,以避免單點故障。
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
labelSelector:
matchLabels:
app: my-app
topologyKey: "kubernetes.io/hostname"
親和性和反親和性提供了靈活的調度策略,使 Kubernetes 集群更好地管理資源分配、性能和可靠性。
從 Pod 出發,現在我們對 Kubernetes 的特性有了一個基本的理解。在接下來的章節中,我們將深入探討這些特性,並通過實際操作來體驗這些特性的應用。

