GROQ ( Graph-Relational Object Queries ) 語法是 Sanity 自己開發的 open-source 查詢語法。
儘管 Sanity 也支援 GraphQL ,但是用他們原生支援的不僅在速度上有優勢,在文件支援上也比較完整。
Vision 頁面提供了 GROQ 查詢語法的測試環境,一般來說預設都是會有這個頁面的。
Vision 頁面是來自於 @sanity/vision 這個 npm package,安裝的地方就在 sanity.config.ts 中:
import {defineConfig} from 'sanity'
import {structureTool} from 'sanity/structure'
import {visionTool} from '@sanity/vision'
import {schemaTypes} from './schemaTypes'
export default defineConfig({
// ...
plugins: [structureTool(), visionTool()], // 頁面 plugin
// ...
})
有這個 plugin 後就會有 Vision 這個頁面了。
也可以看到前面有 structureTool() 這個 plugin,猜到了吧!沒錯!就是前面幾篇一直在用的 Structure 頁面。
這邊就先列出一些比較基礎的用法跟本專案會用到的語法。
第一個是語法的基礎:
* // 檢索出所有資料
*[] // 同樣是檢索出所有資料,但是沒有任何的搜尋條件
*[_type == "blogPost"] // 檢索出所有型別是 blogPost 的資料
可以看出 * 是代表全部的資料內容,
而 [] 則是可以設定查詢條件
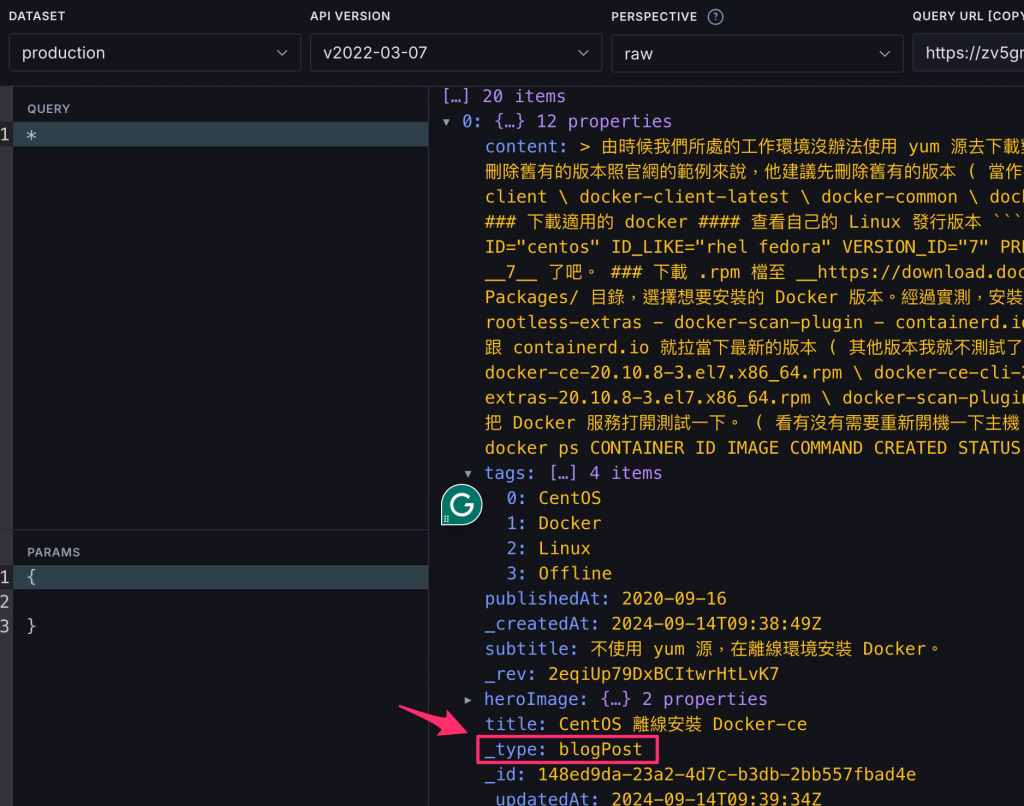
所以可以看到 *[_type == "blogPost"],就是把所有 _type 是 blogPost 的查詢出來。
在查詢中還可以選取要看出來的欄位:
*[_type == "blogPost"]{title, slug, publishedAt}
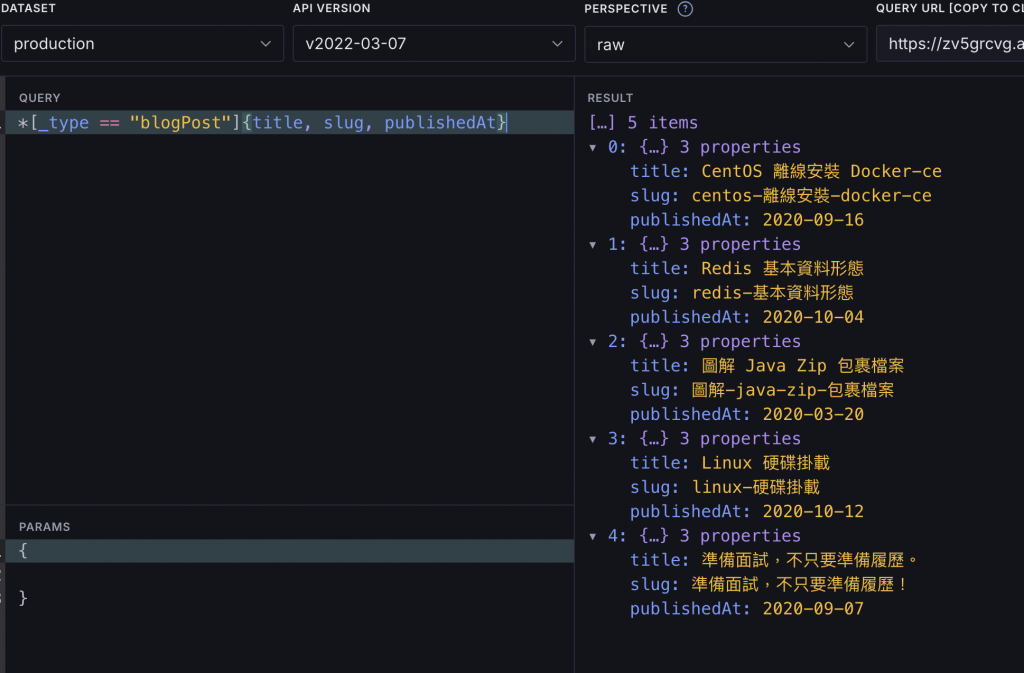
這樣就只限制 title, slug, publishedAt 三個欄位了。
( 做過欄位選取後也比較好解釋下一階段的介紹 )
要做邏輯運算也是可以的:
可以使用 && 來做邏輯判斷:
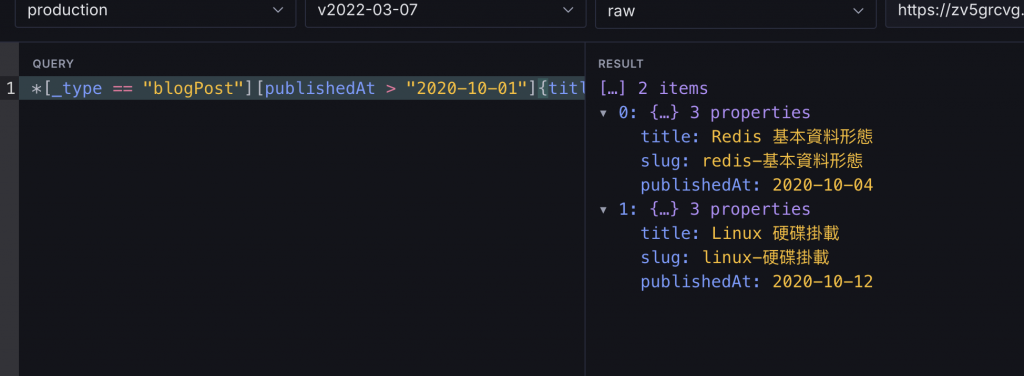
*[_type == "blogPost" && publishedAt > "2020-10-01"]{title, slug, publishedAt}
也可以 pass 給下一個 [] 做邏輯判斷:
*[_type == "blogPost"][publishedAt > "2020-10-01"]{title, slug, publishedAt}
兩種都可以得到一樣的結果:
到這邊可以先停一下,先來了解一下 GROQ 語法的特性。
其實就是一步一步把結果往後傳
以這個語法為例:
*[_type == "blogPost"][publishedAt > "2020-10-01"]{title, slug, publishedAt}
先是 * 把的結果 pass 給 [_type == "blogPost"] 過濾,再 pass 給 [publishedAt > "2020-10-01"] 過濾,最後再給 {title, slug, publishedAt} 做欄位選取。
最後還有個比較常用的涵式,defined 可以檢查屬性是否有定義,有點像是檢查 slug != null,只是用法是 defined(slug)。
*[_type == "blogPost"][defined(slug)]{title, slug, publishedAt}
這樣就可以保障取得到的 slug 一定有值了。
只要掌握這些邏輯,對 Sanity 常用的查詢就已經瞭解得差不多了。
當要查詢圖片的時候可能就想到要把圖片的欄位查詢出來,寫出像是這樣的:
*[_type == "blogPost"]{title, slug, publishedAt, heroImage}
查出來的結果是:

也是可以用吧 ( 之後再教怎麼使用 ),但是他其實是另一個型別的參照而已,要直接使用的話並沒有那麼方便。
如果要將另一個被參照的資料細節列出來,可以使用 → 符號。
以 image 類型來說的話,用法是這樣 heroImage { asset -> },寫出來則會是這樣的:
*[_type == "blogPost"]{title, slug, publishedAt, heroImage { asset -> } }
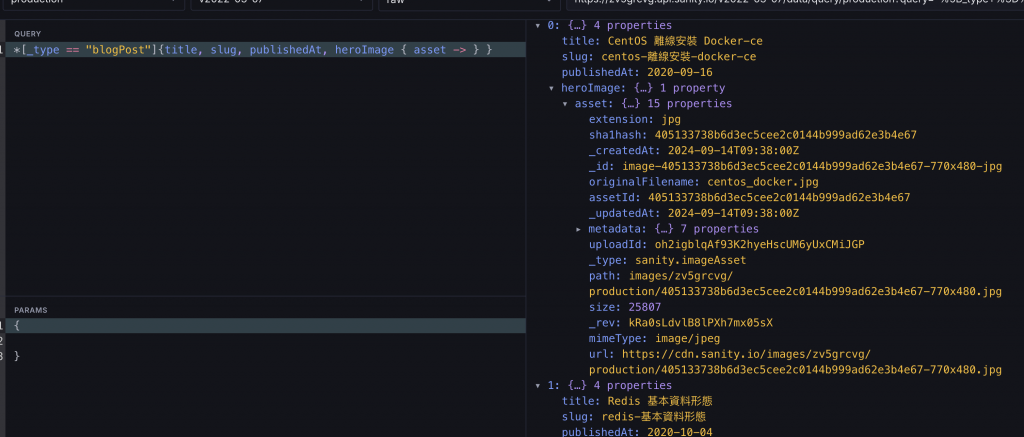
這麼一來全部的細節都出來了。

