點我下載:song_rank3.csv
# data/song_rank3.csv
setwd('/Users/carplee/Desktop/IT python')
r3 = read.csv('data/song_rank3.csv', encoding = 'utf-8')
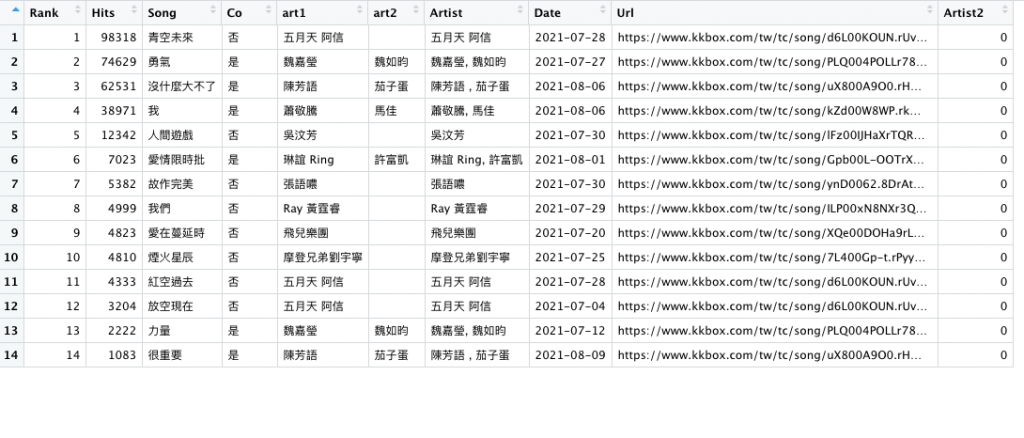
r3
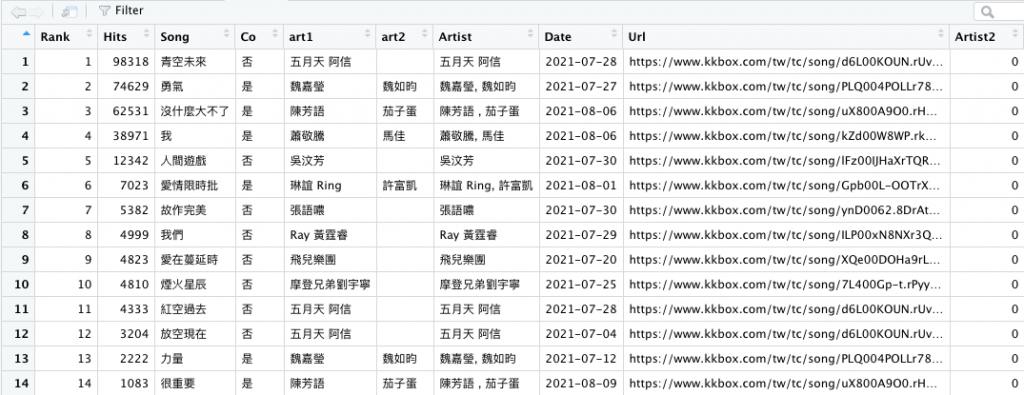
colnames(r3)
[1] "Rank" "Hits" "Song" "Co" "art1" "art2" "Artist" "Date" "Url"
[10] "Artist2"
grep('Artist', colnames(r3))
[1] 7 10 # 第7欄 共10欄
install.packages('dplyr')
library(dplyr)
r3 = r3 %>% mutate(new=0, .after=7)
r3
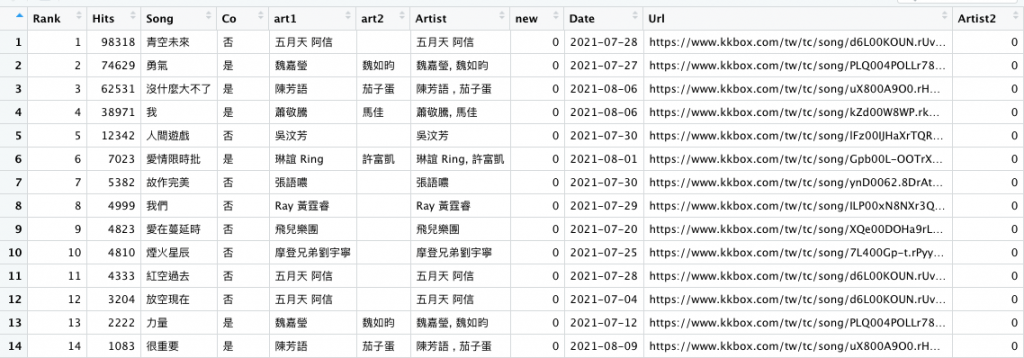
x = grep('Artist', colnames(r3))[1]
r3 = r3 %>% mutate(new2=0, .after=x)
r3
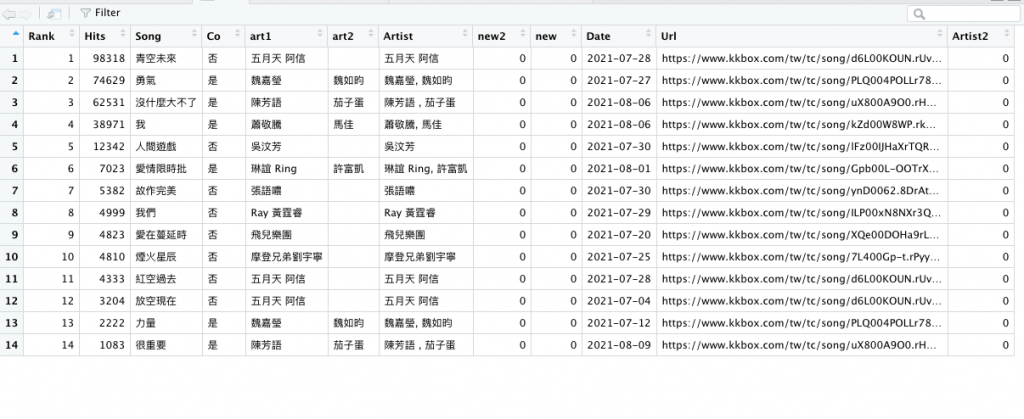
colnames(r3)
[1] "Rank" "Hits" "Song" "Co" "art1" "art2" "Artist" "new2" "new"
[10] "Date" "Url" "Artist2"
grep("new",colnames(r3))
#grep("new2",colnames(r3))
[1] 8 9
grep("new",colnames(r3), value = TRUE)
grep("^a", c('abcde','dea','def')) #a...
grep("e$", c('abcde','dea','def')) #...e
grep("new$",colnames(r3))
index = grep("new$",colnames(r3))
r3 = r3[,-index]
r3
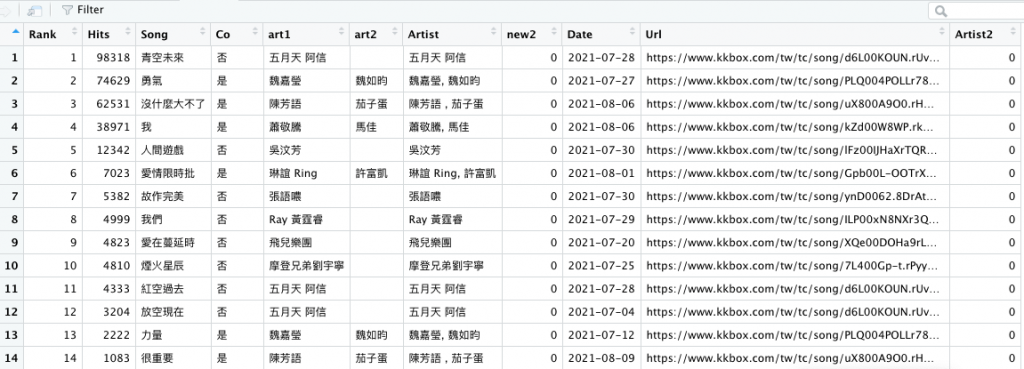
index2 = grep('^new2$', colnames(r3))
r3 = r3[,-index2]
r3


 iThome鐵人賽
iThome鐵人賽