昨天介紹了差分隱私的概念,🫵🏻 今天來討論它在apple中的具體應用,觀察這個技術怎麼保護用戶數據。
整理這些:
https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
https://machinelearning.apple.com/research/scenes-differential-privacy
[ Apple Differential Privacy ] &
[ Learning Iconic Scenes with Differential Privacy ]
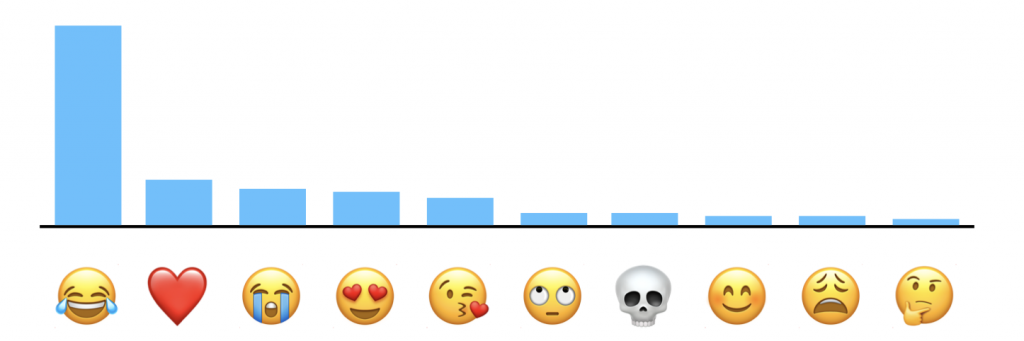
當然還有許多應用,總之,這些例子都展示了Apple如何利用差分隱私技術,在日常使用的產品功能中,收集大規模的行為數據,卻又避免洩露個人隱私。
本地差分隱私(Local Differential Privacy, LDP):Apple採用本地差分隱私的方式,隨機噪聲會在數據還在用戶設備上時就被添加,Apple便會收到已經處理過的數據,無法反推出用戶的具體數據內容。
隱私預算(Privacy Budget):用來衡量不同數據操作的「隱私成本」,當數據的收集或分析超出預設的隱私預算時,系統會限制數據的使用,進一步降低識別個體的風險。
加密與增強安全性:將差分隱私與其他現代加密技術結合使用,進一步加強數據傳輸和儲存的安全性,減少數據洩露的風險。
Apple強調其差分隱私技術的應用是透明且可控的,用戶可以選擇是否參與這些數據收集計畫,當用戶選擇不參與,他們的數據將不會被包含在差分隱私統計中。
在用戶數據的使用和隱私保護方面的「公開政策」,讓用戶能清楚了解他們的數據是如何被處理和保護的。
文中表明他們如何保護全球數億用戶的數據隱私,並強調「差分隱私」是他們解決隱私保護與分析大數據的核心技術之一。
🕯️ 再來看看,Apple是如何利用差分隱私技術來處理「視覺數據」(如圖像情景)的學習。
傳統的機器學習(特別是在處理視覺數據時)往往需要從大量用戶數據中學習,例如:學習場景分類、圖像理解等模型通常會用從多處設備獲取的圖像數據進行訓練,這會導致潛在的隱私風險,因為用戶的個人圖像可能會洩露或被不當使用。
因此,如何在保護用戶隱私的情況下,仍然能夠有效地進行機器學習,是這項研究的核心挑戰。
本地學習:Apple採用一種分布式學習的方法,👽 聯邦學習(Federated Learning)。
這種方法允許在用戶設備訓練模型,並將模型的參數(而非用戶數據)上傳至伺服器,實現大規模模型的協同學習,而不必分享具體的圖像數據。
噪聲注入機制:在本地學習過程中,採取差分隱私的噪聲注入技術,在提取數據特徵時注入隨機噪聲,這樣每個設備回傳的數據是無法識別單一個體的,但整體數據集仍然可以用來訓練模型。
Apple在應用差分隱私時處理數據的工作流程大概是這樣的,並使用了「Leader-Helper」架構來保護數據。
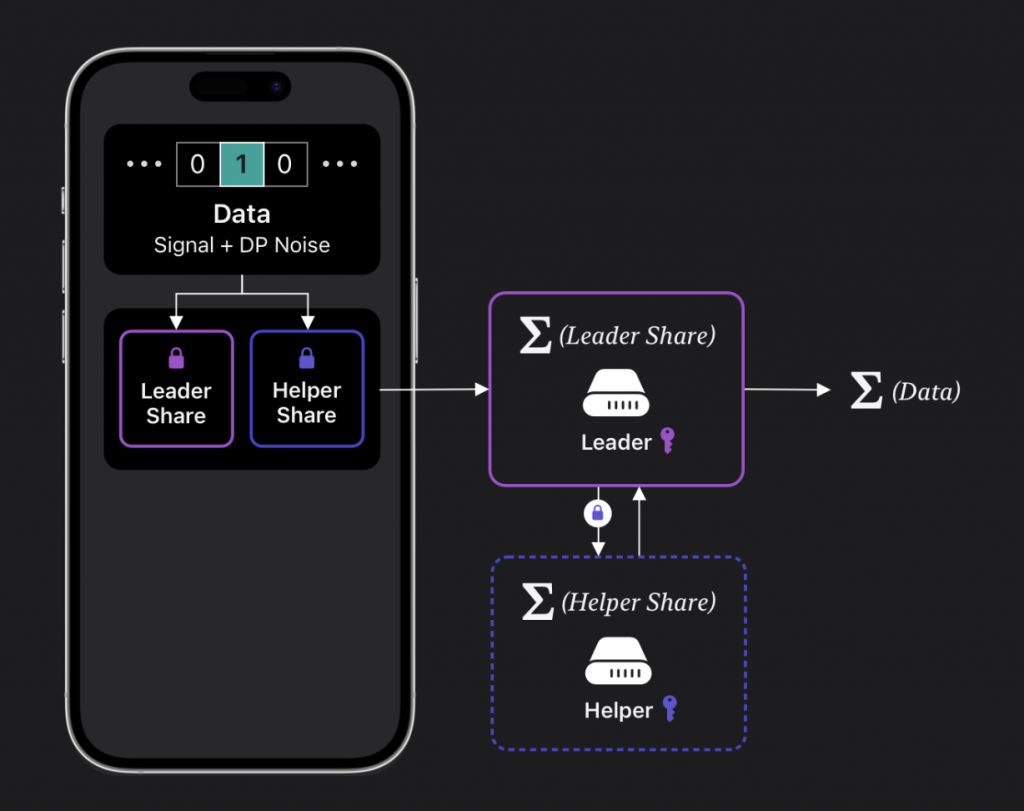
圖中的手機代表用戶設備。
數據包含:信號(原始數據)和差分隱私噪聲(DP Noise),而用戶的數據被分割為兩部分:“Leader Share”和 “Helper Share”,這兩部分的數據會被分別加密,以防止其中任何一部分能夠單獨識別出原始數據。
Leader Share 會被發送到 Leader 伺服器,而 Helper Share 則會發送到 Helper 伺服器。
(這種分割技術確保單一伺服器無法獨立還原完整數據)
文中提到,apple在特定場景下(例如智能手機的相機應用中)成功實現了基於差分隱私的視覺學習模型,這些模型能夠提供高質量的場景識別功能,同時保護用戶數據的隱私,雖然引入了一定的噪聲,理論上會降低模型準確度,但實驗結果顯示,這些模型仍能在一定程度上維持較高的性能,因為研究者仔細設計了噪聲的引入量,確保數據的效用性不被過多削弱。


 iThome鐵人賽
iThome鐵人賽