Kubernetes 的部署邏輯 (⁎⁍̴̛ᴗ⁍̴̛⁎)
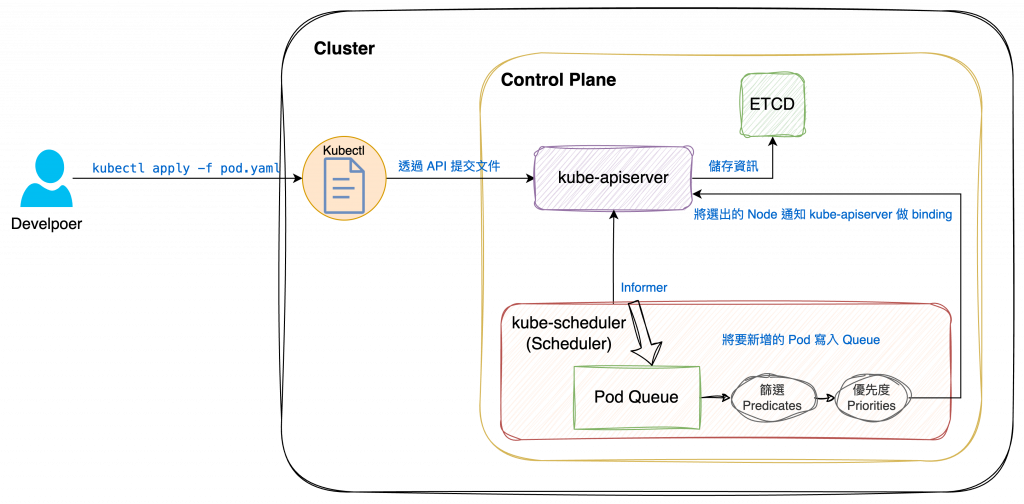
當使用者透過 kubectl 在 Kubernetes Cluster 中建立 Pod 時,要將 Pod 部署在哪一個 Node 上會經過不少判斷邏輯,負責執行篩選的元件就是 Scheduler。
Scheduler 會透過監測機制(Watch)來發現 Cluster 中已經建立,但尚未調度到 Node 上的 Pod,並會判斷部署相關設定和現有資源,選擇最適合的 Node 來運行。
- 如果 scheduler 發生異常或無法作業,Pod 會停留在 pending 狀態
- 已經建立的 Pod 不可修改 Node,需刪除並在其他 Node 重啟
kube-scheduler 是 Kubernetes 預設的 Scheduler,屬於 Control Plane 的一部分,在設計上允許自訂。
(可自行編寫一個組件去替換原有的 kube-scheduler )
運作機制:
由於 Containter/Pod 本身的需求不同,kube-scheduler 會過濾掉不滿足條件的 Node,其中滿足使用條件的 Node 稱為 feasible nodes,再從中擇優去運行 Pod。雖然也可以使用 API 為 Pod 指定要運行的 Node(*註1),但實務上並不常這樣應用,多半是特殊情況。
如何透過 API 指定 Pod 要部署的 Node
curl --header "Content-Type:application/json" --request POST --data '{"apiVerison":"v1","kind":"Binding","metadata":{"name":"nginx"},"target":{"apiVersion":"v1","kind":"Node","name":"<nodeName>"}}' http://$SERVER/api/v1/namespaces/<space_name>/pods/$PODNAME/binding
yaml format
apiVerison: v1
kind: Binding
metadata:
name: nginx
target:
apiVersion: v1
kind: Node
name: <nodeName>
Predicates :條件,kube-scheduler 會對 Node 進行篩選,可以理解為過濾條件。
nodeName,若有指定要部署的 Node 則過濾掉名稱不符者nodeSelector 相符。Taints屬性的 Node 上。Priorities:優先度,kube-scheduler 會對預選階段篩選出的 Node 進行評分,根據優先級來選擇最合適的節點。
NodeAffinity,相符的 Node 加分(優先度提高)。上述只列出比較常見的規則,詳細內容可參考官方文件:Scheduling, Preemption and Eviction
Scheduler 在 Cluster 中找到所有的 feasible nodes,然後根據一連串的運算判斷出最適合運行的 Node,最後終於選定要部署的 Node,就會將這個結果發送給 kube-apiserver。
這個行為就稱為綁定。
最後,當 Pod 部署完成後會由 kubelet 持續監控 Pod 狀態,並回報給 kube-apiserver。
如果 Pod 屬於 Service 的一部分,則會由 kube-proxy 更新 Node 轉送規則,才得以將服務對外提供。
(續上圖,從 kube-apiserver 收到 Node 資訊開始)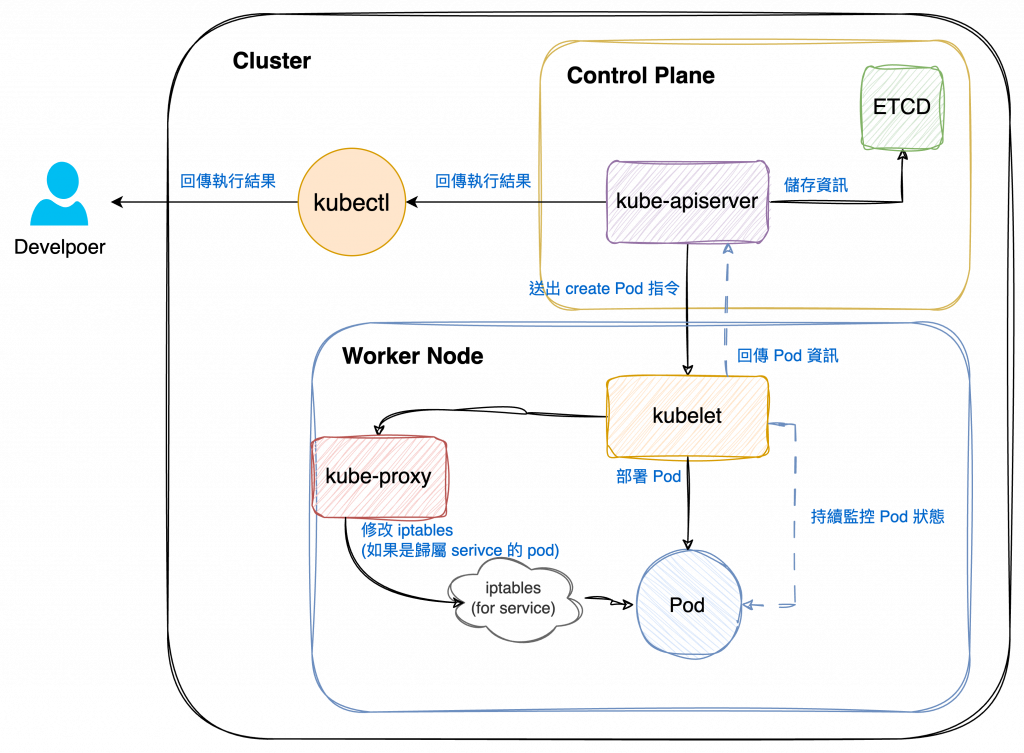
Scheduler 做決策時需要考慮各項因素,除了資源需求、策略限制,還要考慮 Cluster 的整體平衡。有時可能會見到邏輯衝突的判斷標準,但它們在 Kubernetes 中的權重可能不相同,反之,也可以透過修改這些權重,調整出符合實際情況需要的部署策略。
*註1
nodeName 指定 Pod 要運行的 Node設定方式如下:
apiVersion: v1
kind: Pod
metadata:
namespace: <namespace-name>
name: <pod-name>
spec:
nodeName: <要指定的 Node 名稱>
containers:
- name: nginx-pod
image: nginx:1.11.9
使用這個設定需要特別留意,一旦指定了
nodeName,就等於不做 Scheduler 的調度策略, Kubernetes 會直接嘗試將 Pod 部署在指定的 Node 上。
此時一旦 Node 資源不足,就很容易出現out of CPU或者out of Memory錯誤。

