昨天,我們學習了 Numpy 的基本運算技巧。今天,我們將把這些技巧應用到 Iris 資料集上,進行進一步的分析。Iris 資料集是一個經典的資料集,包含四個特徵(花萼長度、花萼寬度、花瓣長度、花瓣寬度)以及三種不同的花卉類型。
首先,讓我們再次載入 Iris 資料集,並將其中的特徵轉換為 Numpy 陣列:
import pandas as pd
import numpy as np
# 將特徵轉換為 Numpy 陣列
iris_data = iris_df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']].values
# 檢視資料集的前五筆資料
print(iris_data[:5])
這段程式碼會將 Iris 資料集中四個特徵的數據轉換為 Numpy 陣列,這樣我們就可以利用 Numpy 進行數學運算和分析。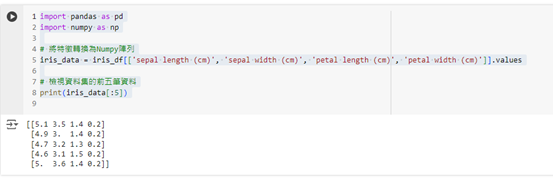
接下來,我們將計算每個特徵的統計數據,例如平均值、標準差、最大值和最小值。這些統計數據可以幫助我們更好地了解資料的分佈情況。
# 計算每個特徵的平均值
mean_values = np.mean(iris_data, axis=0)
print("每個特徵的平均值:", mean_values)
# 計算每個特徵的標準差
std_values = np.std(iris_data, axis=0)
print("每個特徵的標準差:", std_values)
# 計算每個特徵的最大值和最小值
max_values = np.max(iris_data, axis=0)
min_values = np.min(iris_data, axis=0)
print("每個特徵的最大值:", max_values)
print("每個特徵的最小值:", min_values)
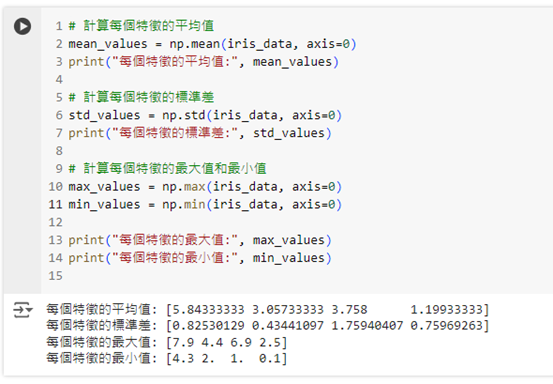
這段程式碼會幫助我們快速得到每個特徵的基本統計資訊,這些數據對我們理解資料的特性非常重要。
我們可以使用 Numpy 來計算資料集的總和與積,這些數據有助於了解整個資料集的整體趨勢。
# 計算每個特徵的總和
sum_values = np.sum(iris_data, axis=0)
print("每個特徵的總和:", sum_values)
# 計算每個特徵的積
prod_values = np.prod(iris_data, axis=0)
print("每個特徵的積:", prod_values)
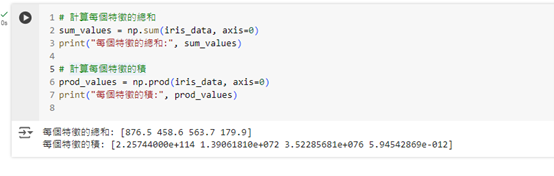
這些計算結果可以幫助我們更深入理解每個特徵之間的數值關係。
我們可以使用 Numpy 來篩選符合特定條件的資料。例如,篩選出所有花瓣長度大於 1.5 公分的資料:
# 篩選花瓣長度大於 1.5 的資料
petal_length_filter = iris_data[:, 2] > 1.5
filtered_data = iris_data[petal_length_filter]
print("花瓣長度大於 1.5 的資料:")
print(filtered_data[:5])
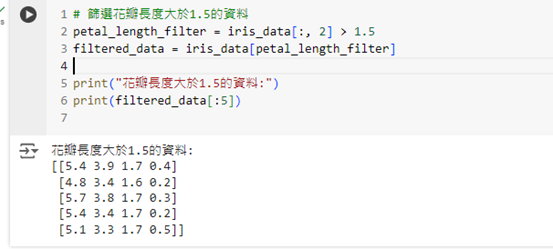
這段程式碼會篩選出所有花瓣長度大於 1.5 的資料,這有助於我們分析資料中某些特徵的分佈情況。
正規化是一個常見的資料預處理步驟,可以將不同特徵的數據範圍標準化。我們可以使用 Numpy 將資料進行正規化,將每個特徵的值縮放到 0 和 1 之間:
# 資料正規化
min_values = np.min(iris_data, axis=0)
max_values = np.max(iris_data, axis=0)
normalized_data = (iris_data - min_values) / (max_values - min_values)
print("正規化後的資料:")
print(normalized_data[:5])
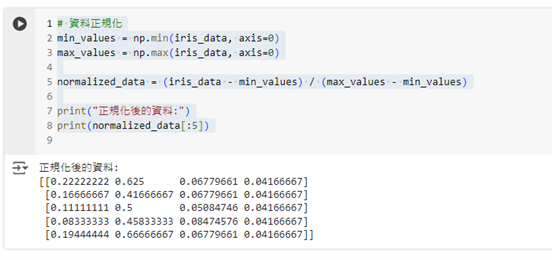
這樣處理後,所有特徵的數值範圍都會被縮放到 [0, 1] 之間,這對某些機器學習模型會有幫助。
今天我們學習了如何使用 Numpy 進行進一步的 Iris 資料分析。我們應用了 Numpy 來計算統計數據、篩選資料、進行正規化,這些操作對於我們分析和處理資料是非常重要的。
明天,我們將學習如何使用 Pandas 來進行更進階的資料操作,進一步提升我們處理和分析資料的能力。
文章有任何問題
都歡迎私訊我的IG
點我私訊

