什麼是開發完成?在小組織營運中,身上總是同時有三五個專案在跑,雖然 dbt 重構是蠻大的一道題目,也不可能讓他永無止盡地做下去,必須有個清楚的 ending 才行。
在這樣的情況下,我們用了幾個東西來評估,其一是 dbt labs 自己開發出的 dbt_project_evaluator 工具(文件),透過 package 導入後即可使用。
這個工具可以幫助你評估模型、文件與測試、整個架構是否有符合 dbt 一開始建立的 best practices。
文件中有蠻詳細的介紹,我就挑一些我覺得比較重要的環節來介紹:
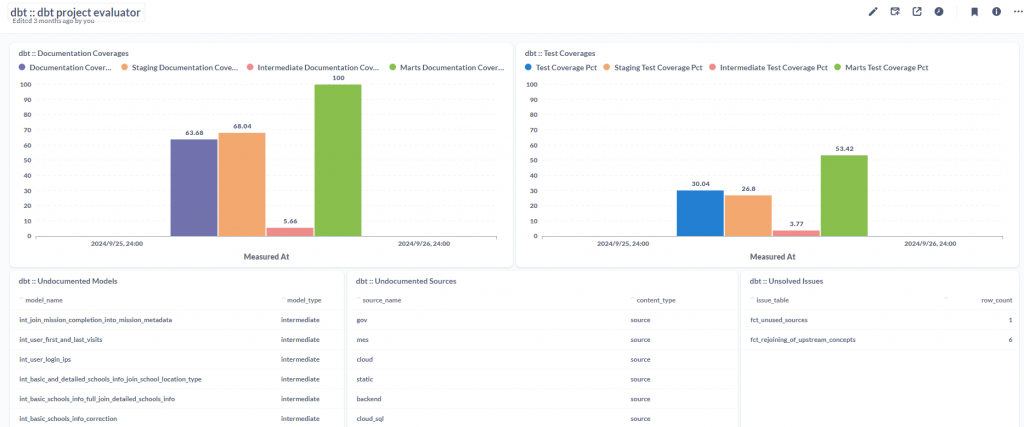
關於文件與測試的部分,我用它來確認 staging, intermediate, marts 的各層級中,文件與測試的覆蓋率,實話實說,我原先希望全部都達到百分之百的,但考量人力的 CP 值,可以參考前面這篇,我們目前只把 marts 的部分做好做滿,其他則是另開專案再行補上。
關於架構的部分,也就是先前提的 staging, intermediate, marts 的層級,他做了一些檢查來確保你有按照這個架構來開發:
fct_hard_coded_references - 未使用 ref 而直接使用 dateset.table 來取用(文件)fct_direct_join_to_source, fct_marts_or_intermediate_dependent_on_source - 不應該直接操作 source table,需要透過 staging 轉換fct_duplicate_sources - source 與 staging model 應一一對應fct_staging_dependent_on_marts_or_intermediate, fct_staging_dependent_on_staging - staging model 不是取用 source 而是取用其他 staging models,或是 marts modelsfct_model_naming_conventions - model 名稱有 stg, int, dim, fct 的前綴其他就不一一舉例,經過這個評估後,每個原則他都會建立一張資料表,可以看資料表中有哪些違反原則的內容需要去調整。
不過也有一些項目我在實作中覺得可以參考看看即可,像是:
fct_too_many_joins - model 中有過多(預設為 7)的 join:雖然看起來很醜,有時候上游的資料就是有些狀況,才需要透過非常手段解決,當然如果這是普遍狀況,實在是太不健康了,但我們有少數幾張表遇到這樣的情況,沒有另外再去修正fct_model_fanout - 超過 n (預設為 3)個直接的下游表:有些表非常熱門,像是使用者的資料表,所有的紀錄都需要去 join 使用者的資訊,即會成為該表的下游;或是平台的內容資料等,也許把 n 調高是一個作法,不過我傾向自己思考目前的 lineage 是否合理且必要,沒有依賴這個項目來做評估。大家可以依照自己的需求來去做使用,而在 dbt cloud 中,它可以在評估完後呈現出儀表板,挺精緻的。
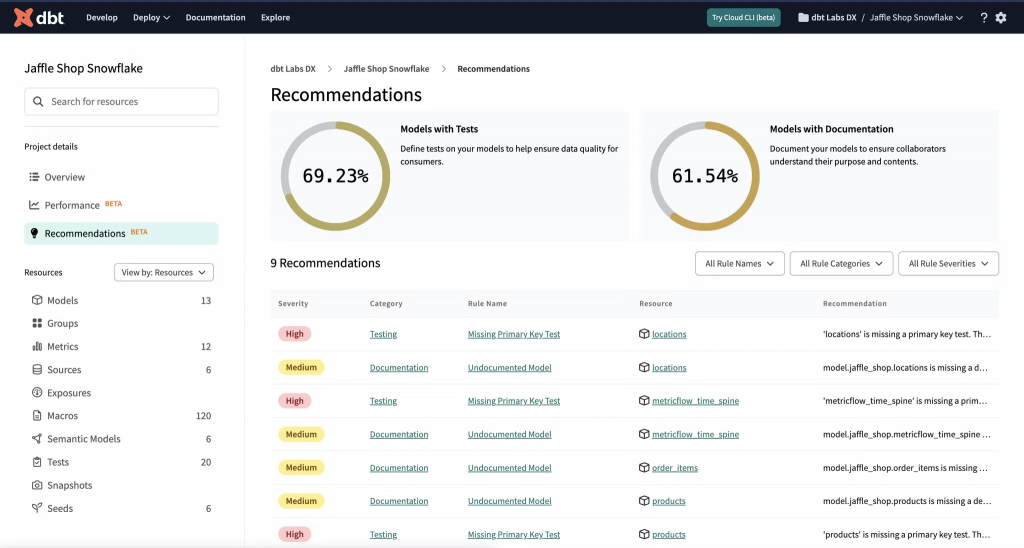
在 dbt core 運行完畢後,我們只會有一張張資料表,顯示每個項目(rule)的檢查結果,於是我只能自己在 metabase 去依樣畫葫蘆,順帶把上面我覺得不需要的 rule 剔除掉,來去呈現出來,幸好 SQL 可說是這份工作中最單純的事了,不用花太多時間。
可以自己客製化調整,挺好的。
關於文件與測試的覆蓋率,另外順道提一個開發中有用過的工具:dbt-coverage。
只要 pip install 一下就可以直接用 command line 使用,蠻輕薄短小的。
它可以呈現出每張資料表中文件跟測試的覆蓋率,可以加上一些 filter 來專注關注於剛開發完的部分,或是調整參數,把結果輸出成 json file 做後續的運用。
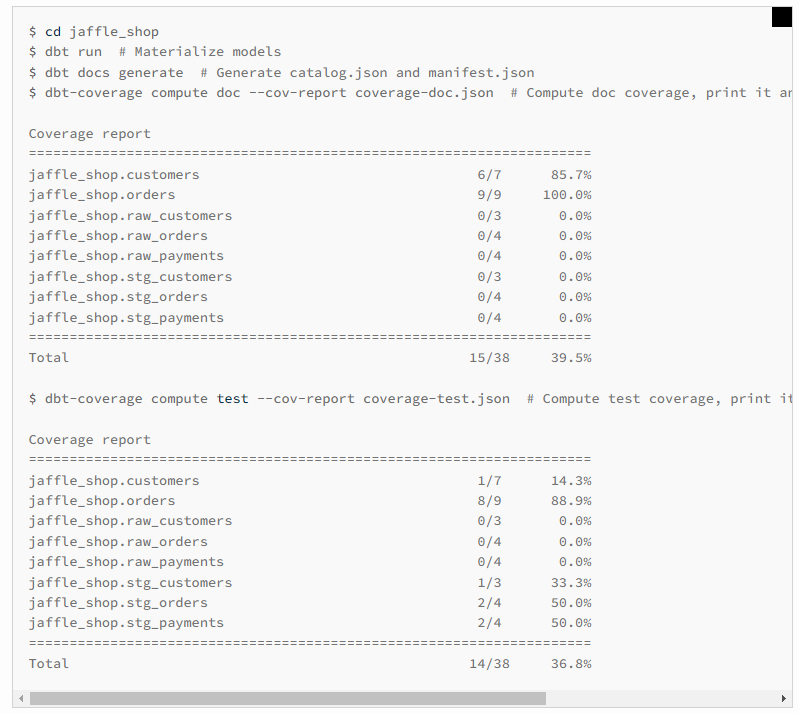
另外 compare 的功能也蠻不賴的,我覺得它的簡便,或許蠻適合安排進 CICD 流程的,來去確認每隻 PR 是否有健全的覆蓋率。
另外還有一個不錯的副作用(?),過程中蠻常遇到開發者 yaml file 中欄位有錯字,沒有檢查到,在經過這樣的比較後就可以更及時的發現 XD

很適合大家在開發中的 dbt 專案中玩玩~

