如果你是一個數據工作者,這些問題你一定常常聽到:
Data Cube,好像沒有一個好的中文翻譯,概念就如同下圖一樣,將資料分析看成一個多維度的立方體,最常見的分析維度是『時間』、『產品』、『業務』以及『地理位置』,我很喜歡Data Cube 的概念,我們可以對他進行一些資料分析的操作:
而 Data Cube 的實現技術就是透過 Dimensional Modeling(維度建模)的技術來實現,其中包含兩個很重要的元素:『維度表』與『事實表』。
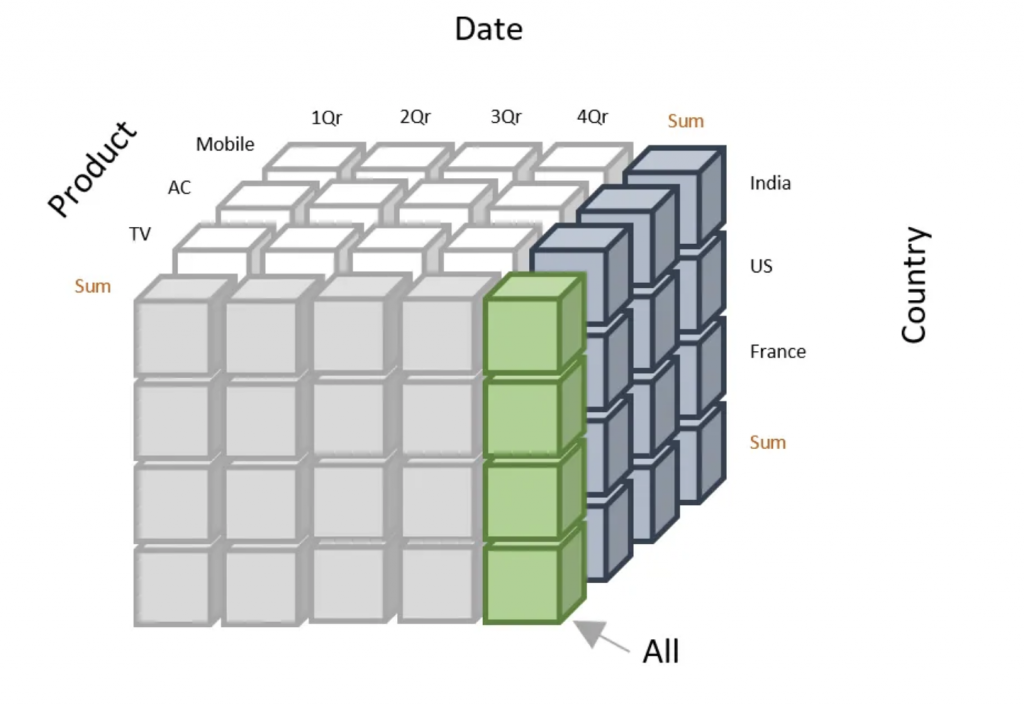
圖片來源: (https://www.javatpoint.com/data-warehouse-what-is-data-cube)
Dimensional Modeling 就是為了解決我們前面提到的問題而生,資料倉儲提供給分析使用的資料表必須具備幾個特色:
OLTP 的資料表設計會遵守資料表正規化 1NF ~ 3NF的原則,來提高資料的一致性和查詢效率;OLAP 的維度建模則是透過放寬對 3NF 的遵守,減少資料表關係的複雜度、JOIN次數,來提高資料表在分析時的直覺好理解。
事實表紀錄的是從業務或是產品角度的一個計量,可以是一個數字,也可以是一次事件,例如一次購買訂單,這一次的購買會是一筆資料,裡面包含購買的日期、購買的商品、金額等,可以理解成現實世界發生一次的事件,就會對應到事實表中的一筆資料。
事實表常見的三種資料顆粒度,事件型就是每一次發生事件就紀錄一筆,例如:用戶完成一筆訂單,週期型則是以你指定的時間區間做好事先加總計算,例如:用戶每週完成訂單數量,累積型則是計算用戶至今完成的數量,例如:用戶至註冊到現在完成多少訂單。
事實表多數具備可以被加總的欄位,例如: 購買數量,有時候也會具備不可加總的欄位,這時候事實表的操作可能會是 Count。
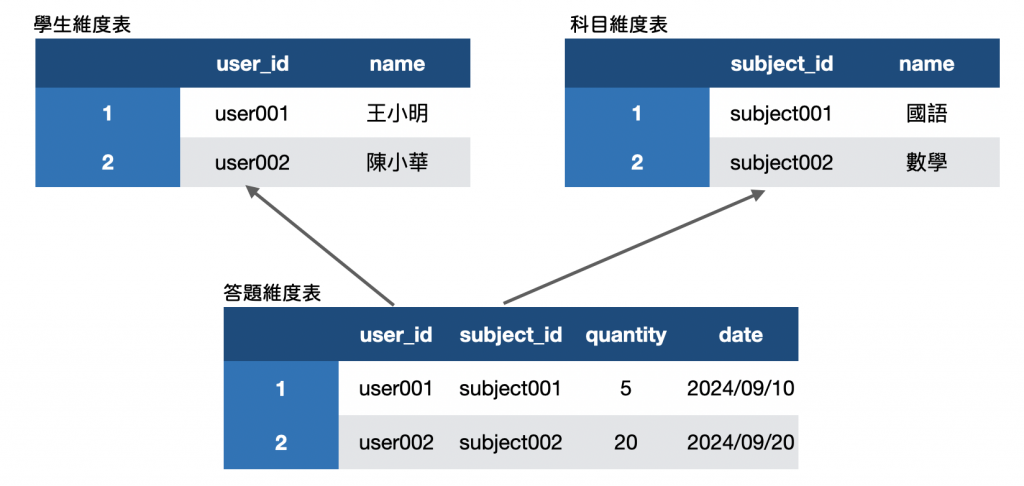
用來描述該事實發生時的情境,可以用5W來理解,做了什麼事、什麼時候發生、誰做了這件事、在哪裡做了這件事、為什麼做這件事,例如:王小明在2024/9/10 完成了國小三年級國語的題目5題。
維度表通常有非常多的欄位,就算超過30個都不意外,目的就是要減少在分析時需要理解的資料複雜度,所以會盡可能扁平化的設計。
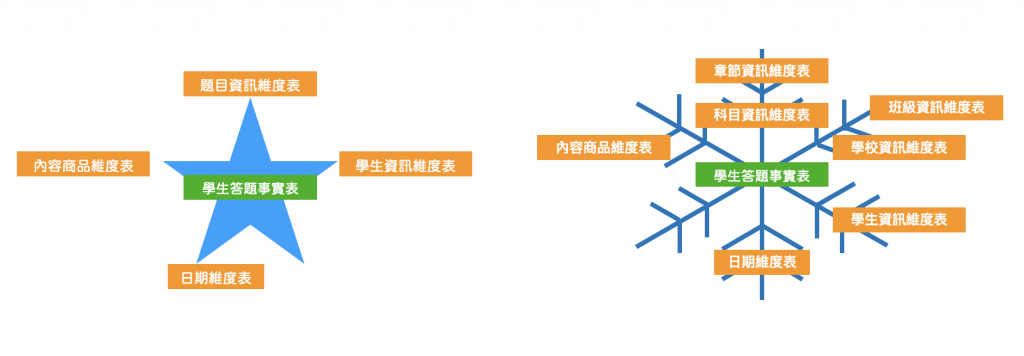
在Star Schema中,事實表位於中央,維度表環繞在周圍,幾乎一次JOIN 就能得到所需要的資訊,看起來像是星星的形狀。
事實表一樣位於中央,維度表環繞周圍,與Star Schema不同的地方是可能會有多層的維度表,長得像是雪花一樣。
在進行維度表與事實表的設計時,會遇到很多模擬兩可的問題,例如:產品的定價究竟是屬於維度表還是事實表?
因此你需要好好的和業務、產品經理相處、訪談他們,你需要了解大量的情境、了解你公司的產品、了解你的公司業務和銷售目標,才能滿足資料倉儲的設計目的:『讓業務、PM群願意接受資料倉儲系統,並用於資料分析、支援決策』。
接下來我們會用一個例子說明事實表與維度表的設計與常見的問題。


 iThome鐵人賽
iThome鐵人賽