有刷過題的工程師,一定都對時間複雜度不陌生,不過我卻遇過不少知道了時間複雜度這個概念,但是在日常的 Coding 中卻不知道怎麼運用的人。
我最常聽見的說法是:「產品中又不需要寫演算法,刷題和時間複雜度根本就用不上。」
然而,刷題用到的知識以及分析時間複雜度的能力在一般 Coding 真的用不到嗎?且讓我們看一個例子。
假設我們在前端實作一個簡單的功能:
印出所有商品名稱及其分類
const products = [
{ id: 1, name: 'Apple', categoryId: 1 },
{ id: 2, name: 'Carrot', categoryId: 2 },
{ id: 3, name: 'Orange', categoryId: 1 },
];
const categories = [
{ id: 1, name: 'Fruit' },
{ id: 2, name: 'Vegetable' },
];
例如以上資料,預期印出這樣的結果
Apple: Fruit
Carrot: Vegetable
Orange: Fruit
那麼該怎麼撰寫程式呢?我們先看以下這個例子
for (const product of products) {
const categoryName = categories.find((category) => category.id === product.categoryId).name;
console.log(`${product.name}: ${categoryName}`);
}
首先是走訪所有的商品,這沒有問題,但是再來獲取分類名稱的作法就有點問題了!
我們使用了 find() 這個 Array 的 Built-in Function,本質上就是走訪所有的 Categories,然後得到之中 id 與當前商品 categoryId 中一樣的元素。
也就是說,當我們走訪到每一個 Product 的時候,都會重新的走訪所有的 Categories,可以想像當 Categories 的數量越多的時候,程式所要走訪的元素就越多,複雜的程度將呈指數級的成長。
那麼這樣的寫法會怎麼樣的影響程式執行的 Performance 呢?我們就需要用「時間複雜度」分析一遍了。
所謂的時間複雜度,就是衡量一個演算法在時間效率上優劣的一種方法,我們通常用大寫的 O(讀作 Big-O)來表示。
下表就是不同類型的 Big-O,例如 O(1)、O(n)、O(n^2) 等等,括號裡的內容代表數據量為 n 的情況下,所需時間的成長趨勢,表格上面的 1,2,…,10 代表 n 的大小。

*時間複雜度趨勢表格
例如 O(1) 代表常數的成長,不論數據量 n 有多大,所需的時間都不增加,所以在 O(1) 這個 row 的數值並不會因為數據量增加而有變化。當然這邊的不會增加是以數量級來衡量的,意味著就算有時間有增加,也不會是成倍、指數的增加。
而 O(n^2) 就是指數的增長了,可以從表格及下圖中明顯看到,當 n 的大小增大時,所需要的時間增加的趨勢快了許多,碾壓下面的 O(n), O(nlog(n)) 等等。
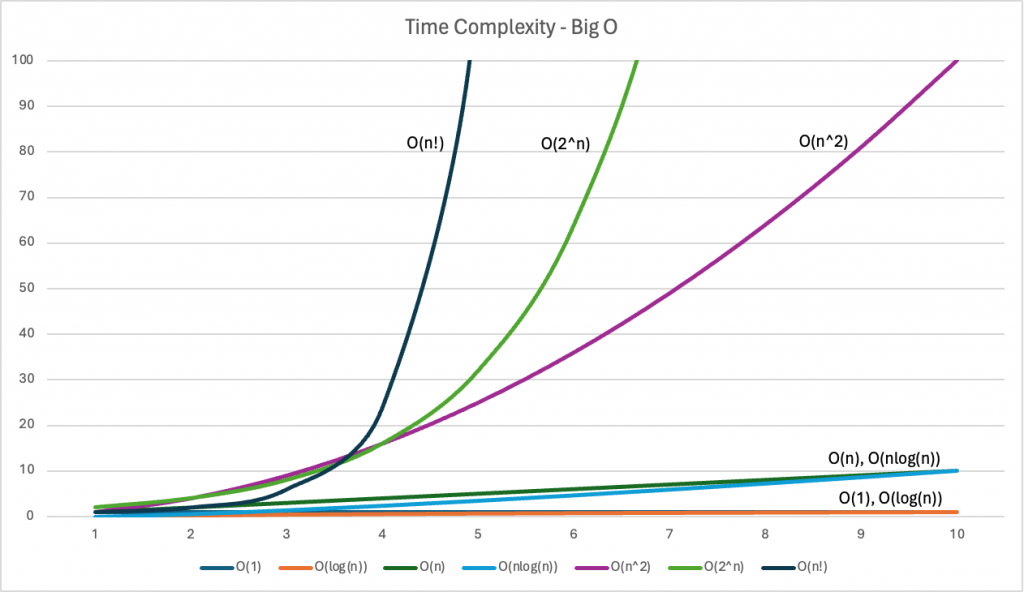
*時間複雜度趨勢圖
回到剛剛那個例子,我們在一個 for 迴圈當中呼叫了 Built-in function find(),該如何分析這個時間複雜度呢?
由於時間複雜度所評估的是資料變多造成的時間增長趨勢,我們需要先假設資料量:可以將 Products 的數量訂成 n,而 Categories 的數量為 m。
第一個 for 迴圈走訪了所有 Products,時間複雜度就是很直接的 O(n);而 find() 函式本質上也是另一個 for 迴圈,但是走訪了所有 Categories,所以時間複雜度是 O(m)。

*解析演算法時間複雜度
而我們每走訪到一個 Product,就跑一次 O(m):用其 Category ID 去反查 Category Name,也就是這整個演算法的時間複雜度是兩者的乘積 O(n) * O(m)。
我們如果假設 Products 和 Categories 的數量一樣都為 n,就可以簡化成 O(n) * O(n),等同於 O(n^2),一個指數型的增長。
當我們資料的數量不多時可能會感覺不出有什麼明顯的差異,但當數量變多時,這樣簡單的運算就可能讓你的瀏覽器速度變得極端緩慢!
實際計算看看,如果在迴圈中每跑一段 code 需要的時間是 1 µs(百萬分之一秒),當 n 的數量為 100 時,只要約 10 ms(10,000 µs)的時間便能跑完,人體幾乎感受不到。
但是當 n 的數量成長成 1,000 時,就需要 1 秒才能跑完,已經是我們能感受到的時間了;若 n 為 2,000 時,就要 4 秒、3,000 需要 9 秒,而這僅僅是一個從產品找類別的簡單演算而已。
在程式開發的初期如果因為測試的資料量少,而忽略這個問題,很可能就會在產品實際上線時發覺怎麼速度越來越慢了。這也就是為什麼工程師該知道一些時間複雜度,就算我們並不會實際撰寫高深的演算法,還是需要知道我們所使用的 function 會對整個產品的效能造成什麼影響。
接下來讓我們來聊聊在全端開發常用的資料結構,什麼時候使用它們,又如何分析他們的時間複雜度。


 iThome鐵人賽
iThome鐵人賽