昨天花了一些時間來執行DCGAN的最佳化,在文章撰寫時我就在執行程式了,寫完文章後發現程式還沒跑完,還好當初有意識到所以將DCGAN最佳化分為兩天來介紹。睡醒之後發現程式跑完了,今天就來分析一下程式結果以及分享一下這類型模型的最佳化通常有甚麼大方向可以注意。
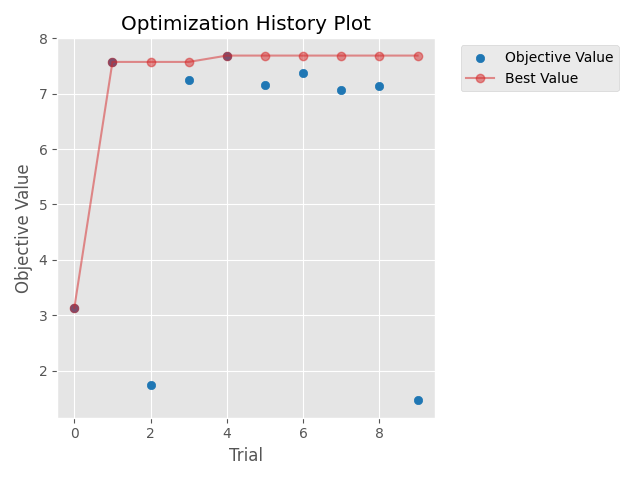
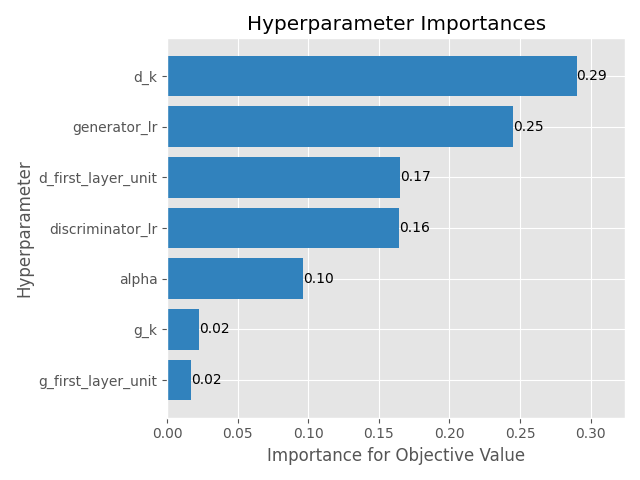
昨天第7步驟以及第8步驟的結果如下:
| 超參數名稱 | 最佳超參數值 |
|---|---|
| 生成器學習率 | 0.00093 |
| 判別器學習率 | 0.00089 |
| 生成器第一層卷積層的神經元數量 | 64 |
| 判別器第一層卷積層的神經元數量 | 256 |
| 生成器卷積核大小 | 5 |
| 判別器卷積核大小 | 2 |
| 判別器LaekyReLU斜率 | 0.15 |
| 最佳適應值 | 7.688874050974846 |
結果看起來並不優秀,不過大概有幾個原因:
在實務應用上,需要注意若不確定最佳化程式是否有問題可以先使用較低迭代次數,與較低訓練次數,先以時間消耗少的方式完整跑過程式,沒問題之後再使用完整的設定來執行程式。
對於生成對抗網路,以及相關的最佳化模型,雖然截至目前為止,最佳化的方式五花八門目前並沒有一個完整的定論。
在NeurIPS 2023(論文連結)上有一篇研究是使用精確度(precision)與召回度(recall)的散度進行平衡以最佳化的方式,根據論文的說明,目前最先進的模型主要都是依賴最佳化啟發式方法,例如FID距離。
該論文提供了一種新的訓練方式,透過最佳化我們定義的精確度和召回率之間的權衡比率,來讓已有的生成對抗網路模型性能更進一步最佳化。
在IEEE Transactions on Neural Networks and Learning Systems期刊(論文連結)上也有一篇研究使用一個「輔助模型」來幫助生成器進行最佳化,詳細內容該論文都有介紹,若各位有興趣也不妨參考看看該論文所提出的方法~
今天分享了昨天程式的執行結果,也分享了一些這方面目前研究的趨勢與成果。
明天開始要來進入另一個最佳化的應用了,與Optuna/TPE這種直接適用於超參數最佳化的演算法不同,MealPy是包含了許多啟發式演算法的模組,使用啟發式演算法進行最佳化也是一種選擇,明天開始我會來介紹MealPy的一些基本功能與API。


 iThome鐵人賽
iThome鐵人賽