昨天在介紹 Netflix 的 Marken——他們的數據標註平台時,有提到兩種資料標註的場景,例如後製想要改變所有影片中出現的手套的顏色,或是想要找到正在喝酒的 James 的畫面。不過,他們是怎麼找到這些畫面的呢?總不可能是人工註解每一幀,為每一個畫面提供註釋吧。
這當然不可能,我們有提到 Marken 的其中一個註釋來源是機器學習演算法,換句話說,他們有一些模型在專門標記資料,這些標記完的資料再透過 data pipelines 匯入 Marken。那這些機器學習演算法背後的原理是什麼呢?讓我們今天一起來認識他吧!
我們在一開始介紹機器學習的生命週期時,有提過高品質和一致的標籤對於開發模型是非常重要的。而傳統的標註流程有幾個問題和痛點
以上三點顯示人工資料標記的困難,非常需要 Netflix 想出一套解決辦法。
今天的案例:Establishing shot
Establishing shot 是電影或電視劇中的一個鏡頭,通常用來展示場景的全貌或背景,確立故事發生的時間、地點或環境,為接下來的情節做鋪墊。
本篇文章會以標註出這個場景為範例,介紹 Netflix 是如何建構出 Video Annotator 的。
首先,為了讓模型能夠理解影片內容,Netflix 使用 video understanding 這個技術,其目的是讓機器學習模型可以辨識影片中的視覺影像、概念或是發生的事件,這是後續其他應用的基礎,例如有助於搜尋影片、個人化推薦,或是製作行銷素材。
Video understanding 的基本概念是運用影片的二元分類模型,將一定長度的影片輸入模型後,模型會回傳特定標籤的機率(介於 0 到 1 之間)。
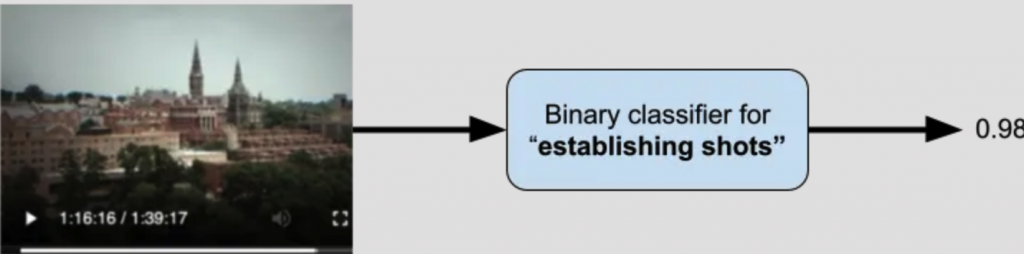
圖片來源:[1]
奠基於此概念,video understanding 其實就是非常多影片的二元分類器所組合而成,每個分類器都是互相獨立的,且可以依情況自由地增添模型,增加彈性,也提供更多種類的標籤。如下圖所示,每段影片會經過多個影片分類器,像是第一段影片可以被視為 establishing shot,同時也是在白天(day)發生的場景。這些多元的標籤,讓 Netflix 的內部使用者可以更靈活地找到自己需要的內容。
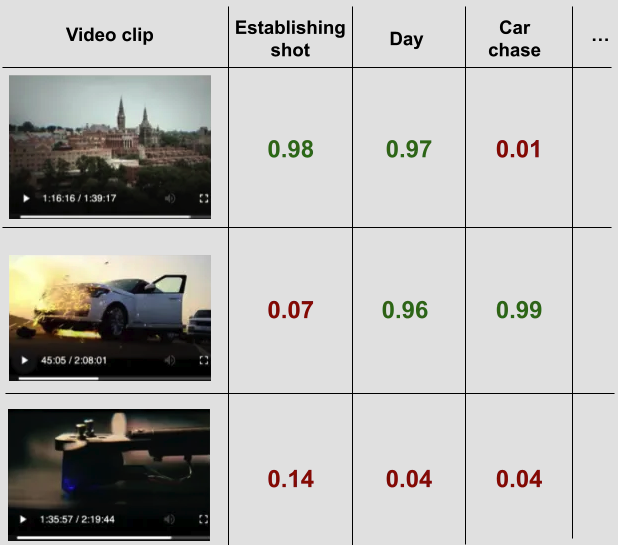
圖片來源:[1]
基於 video understanding 的概念,Netflix 提出一個稱為 Video Annotator (VA) 的工具。VA 其實就是由許多影片分類器所組合而成,並且利用大型視覺語言模型的零樣本(zero-shot)能力和主動學習(active learning)技術,幫助他們標記所需的資料,提升效率並降低成本。
此外,VA 可以無縫地整合進資料註釋的過程中,讓用戶在部署前可以先驗證模型,也可以快速地部署新的模型,以及監控這些模型的表現。如果發現有任何需要調整的 edge cases,只需要增加幾個範例,就可以快速部署一個新版本模型。
那要怎麼建立出 VA 中的這些影片分類器呢?我們以建立 establishing shot 分類器為例,介紹主要的三個步驟:
首先,使用者會先利用大型視覺語言模型,找出哪些是符合他心中設想的標籤。舉例來說,他們想要得到一個 establishing shot 分類器,但是大型視覺語言模型不一定知道哪些畫面符合這個標籤。因此,使用者可以先利用大型視覺語言模型本來的 text-to-video 搜尋能力,搜尋「wide shots of building」這個關鍵字,透過大型視覺語言模型的影片和文字 encoders,將相關畫面提取出來。
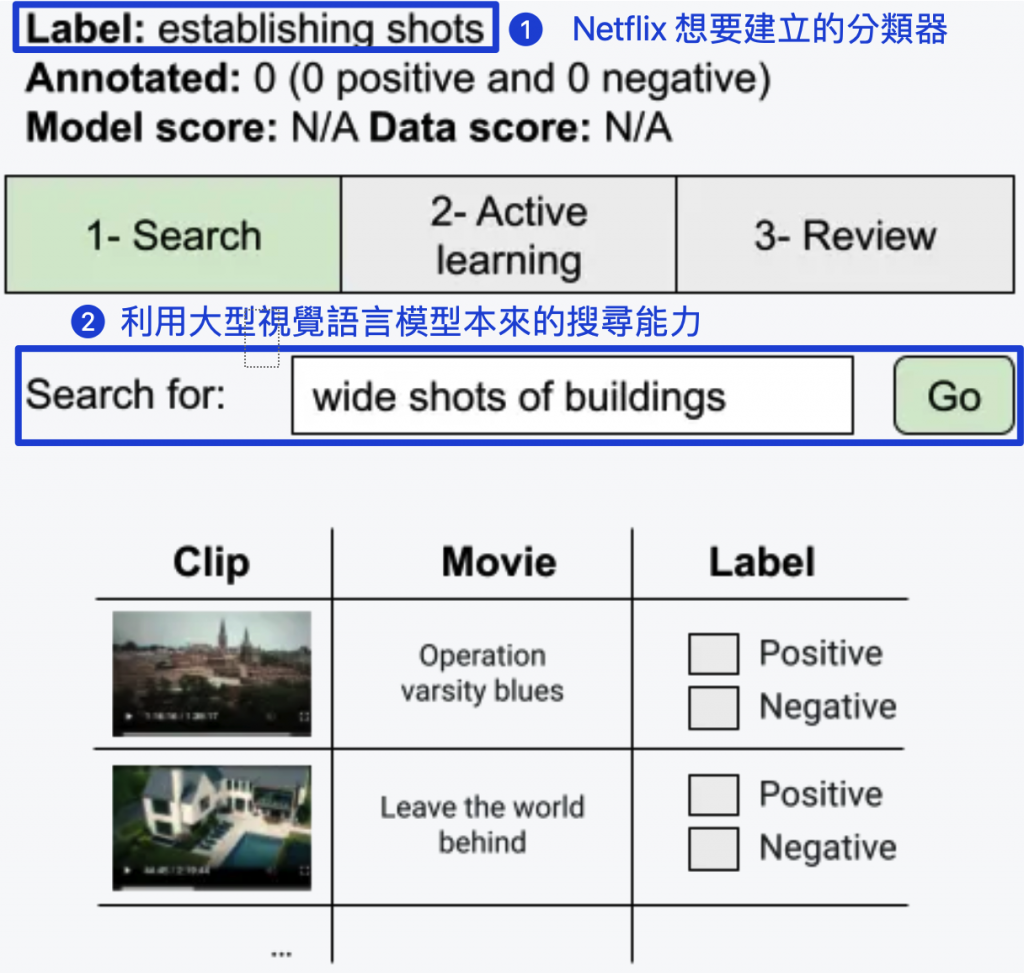
圖片來源:[1]
經過多次搜尋,使用者可以告訴 VA 他心中設想所有關於「establishing shot」的場景為何,幫助 VA 學習。
在搜尋到所有符合的「establishing shot」的畫面後,VA 會建立一個輕量的二元分類器,再將資料庫中的所有影片片段進行評分,並且呈現一些範例,以供進一步的註解和修改。
VA 會提供四種範例:
Netflix 的使用者會對這些範例進行評分,並且根據這些內容建構新的分類器,反覆重複多次,以達到最符合需求的表現。
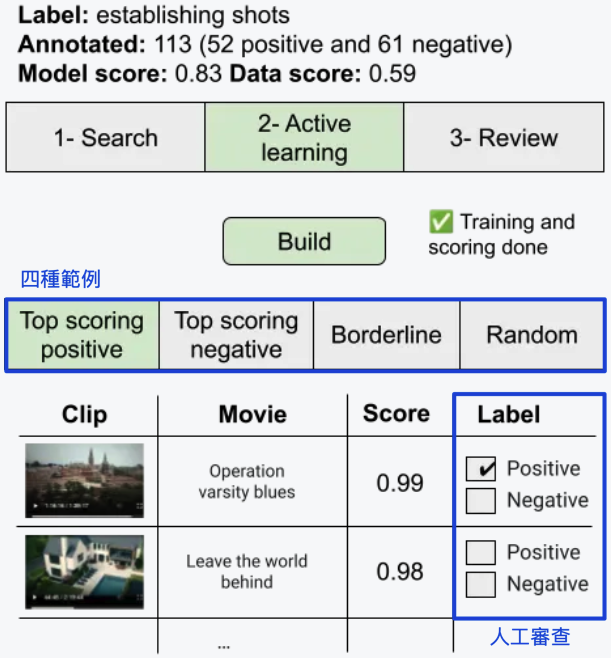
圖片來源:[1]
最後,VA 會向使用者呈現所有已註解的影片片段,如果有發現任何問題,使用者可以回去步驟 1 或步驟 2 進行修正,反覆過程以完善模型。
最後來看看模型表現吧!
VA 對 56 種標籤進行標注,處理了 50 萬個畫面,平均 precision 提升 8.3%,證明 VA 的效能。VA 結合大型視覺語言模型的技術,降低標註成本,又提高效率,並且可以透過持續的標註過程,快速修正模型,為 Netflix 帶來不少助益。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Supplements


 iThome鐵人賽
iThome鐵人賽