雖然上次已經自己找問題,修改完善了。但如果不搞清楚 AI 會寫錯的原因,那麽接下來請 AI 產出的測試,一樣還是可能有問題,AI 還幫我「幻想了」應該存在的組件,直接用於測試中。
所以 AI 產測試的癥結點在哪?
比較可能的原因,是 AI 模型的訓練資料集,是來自開發團隊收集而來的大數據,也就是大家寫好的程式碼來訓練,所以如果 AI 會以此做「推論」,推論說指令沒提到的部分,應該也會跟大家一樣的作法。
於是乎,AI 擅自為你「腦補」了測試的其他部分。
到底 AI 是幻想了什麼呢?
以下是某次使用 AI 生成的測試項目,其中一部分的測試程式碼。AI 覺得我的程式碼中「應該」要有一個 role 是 backspaceButton 的按鈕,來做到「退後」(也就是大家所熟知的往前刪除一格),但…實際上根本沒有這個組件。所以測試跑到此處時,就發生了「找不到該 role 」組件的錯誤。
//...
const backspaceButton = screen.getByRole('backspaceButton');
fireEvent.click(backspaceButton);
那該怎麼辦呢? 其實也沒什麼,大概有 2 種選擇,向 AI 妥協或是自己另起爐灶:
我自己是選 1,既然 AI 都給我建議了,看了也沒什麼問題,那我就回頭補上,補完修改之後大概長這樣,把 role 給加在按鈕組件上
<Button onClick={handleBackspace} role="backspaceButton">
//...
</Button>
再跑一下測試,嗯,通過了,那就先這樣吧。畢竟這部分先不追求「完美」,只求可以快速生成有效且可靠的測試就行,寫法的優化可以等重構之後,到時候說不定會有新的想法,屆時再說。
可以看到說,我們測試都是以「整體」使用者會操作的行為來測試,而不是測「單一組件」的預期行為。
你可能會想說,啊這樣不就有些狀況沒測到? 比方說 handleOK 這個組件內其中一個方法。
const handleOk = () => {
const amount = parseFloat(currentAmount);
if (!isNaN(amount)) {
if (isEditingAmount) {
setPendingAmount(amount);
setIsEditingAmount(false);
setShowCategorySelector(true);
} else {
setPendingAmount(amount);
setShowCategorySelector(true);
}
}
setCurrentAmount("0");
};
有一個 if (2 種可能),嵌套內又有一個 if(2 種可能),總共會有 3 種可能(因為外層的 if 沒有 else),如下表所示意
| isNaN(amount) / false | isNaN(amount) / true | |
|---|---|---|
| isEditingAmount / true | 1 | 3 |
| isEditingAmount / false | 2 | 3 |
如果是針對這個方法做測試,「合格」的測試就要測到以上 3 種情境,都有做到個別測試。
但不這麼做,為什麼?因為這不是程式的主要邏輯,只是「實作細節」而已,哪天重構掉這部分的程式碼,測試就完全沒用了!
測以上這部分的程式沒什麼意義,目前的 Side Project 更適合「由上而下」來做測試。
先前由 AI 生成的測試,也都是「由上而下」做測試的方法,「上」是指最大的範圍,是整個 App 行為層級的大範圍。測了使用者會操作的行為,並測試預期該出現的結果。
而選擇這種「由上而下」的測試寫法,是我們「極速產測試」的前提條件。希望可以快速且可靠,而且「重構之後還不必改寫」,那麽就得從需求面著手,不以程式細節來寫測試。這樣說或許有點抽象,拿上次提到 AI 沒有幫我們寫到的測試來試試。
首先是比較簡單的,我想要知道「新增多筆帳目」,是不是真的會出現在畫面上? 給了 AI 指令:
幫我新增一個測試,用來測試多筆帳目金額會如預期渲染。
AI 馬上為我生成了測試,測試項目是測了 3 筆記帳金額都有如期記帳。
it('renders multiple account amounts correctly', () => {
render(<App />);
// Add first amount
fireEvent.click(screen.getByText('1'));
fireEvent.click(screen.getByText('0'));
fireEvent.click(screen.getByText('OK'));
fireEvent.click(screen.getByText('飲食'));
// Add second amount
fireEvent.click(screen.getByText('2'));
fireEvent.click(screen.getByText('0'));
fireEvent.click(screen.getByText('OK'));
fireEvent.click(screen.getByText('日用品'));
// Check if both amounts are rendered
expect(screen.getByText('$10')).toBeInTheDocument();
expect(screen.getByText('$20')).toBeInTheDocument();
// Check if the total amount is correct
expect(screen.getByText('$30')).toBeInTheDocument();
});
跑了一下測試,發現測試沒通過… 🤔 原來又是之前遇到的問題,沒有在選完種類之後,再次按下 OK。一樣請 AI 修正一下就行了,沒什麼大問題。
另外一個是「雙擊編輯」帳目金額,選了 claude-3.5 模型並輸入以下指令:
參考 @AccountingApp.tsx
幫我新增一個測試,用來測試「雙擊」以編輯帳目金額。
首先是輸入 $10 娛樂的帳目,接著編輯成 $20 飲食
一樣也是咻咻咻很快就產出測試了,雖然看起來蠻有搞頭的,但看到驗測的 getByText() 寫法…嗯,應該不太對,果真如此!
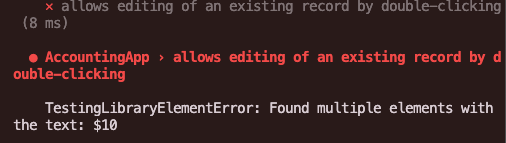
AI 又忘記我的 App 裡面會有「2 個」金額的顯示,同樣的這部分再微調一下應該就行了。另外看了一下流程,編輯那邊沒有「歸零」,所以金額會不對。
看了一下測試,應該要是沒問題才對了,為什麼又錯了呢 🤔…
既然測試沒問題,那回頭檢查一下程式邏輯,不是測試就是程式,反正也就這兩種可能而已。這才發現原來編輯那塊寫錯了 😅,在每次帳目編輯之後,都會再次把「當下輸入的金額」再次加總進 total 值。
const handleSelectCategory = (category: string) => {
if (pendingAmount !== null) {
//...
setTotal(history.reduce((sum, item) => sum + item.amount, 0) + pendingAmount);
setPendingAmount(null);
}
setShowCategorySelector(false);
};
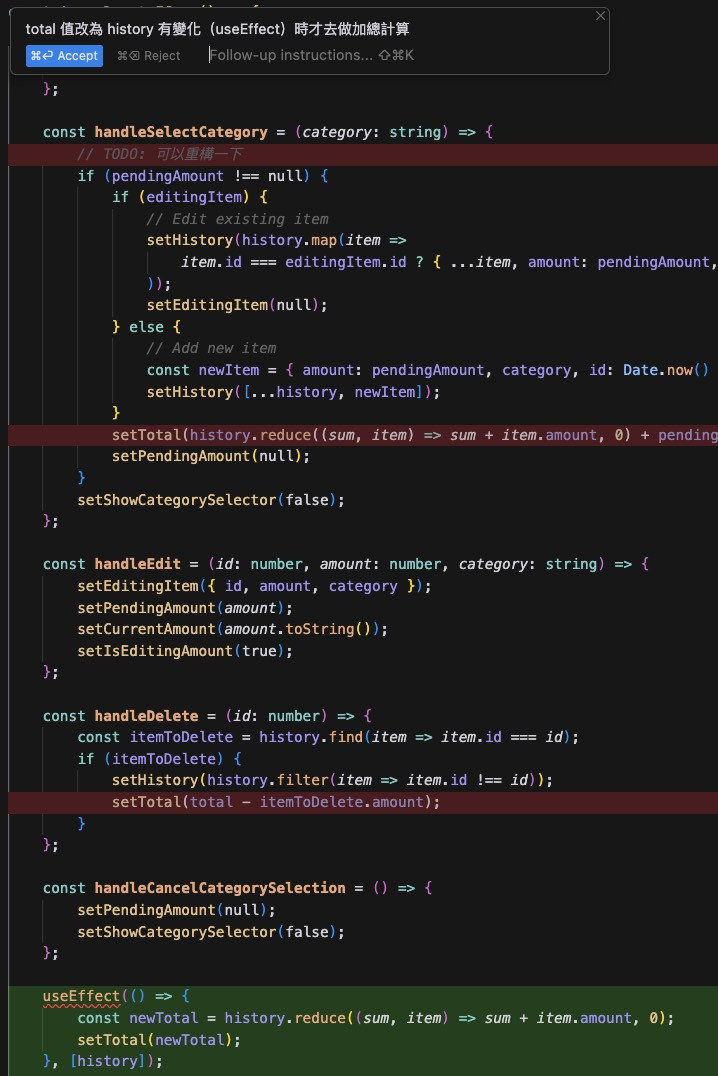
那這樣的話,最快速的作法,是把 total 的值放到 useEffect 裡面做計算。於是輸入以下指令,請 AI 幫忙修改:
total 值改為 history 有變化(useEffect)時才去做加總計算
稍後了一會兒,AI 如期幫我修改完成,再次跑了測試,測試如期通過。

呼…,只是加 2 個測試,比想像中還要累,但有把測試寫好就是開心,今天就先寫到這邊囉~ 🥳
首先是指令的精準度,我只跟 AI 說「參考 OOXX 這個檔案的程式碼,請幫我生成測試」,AI 就咻咻咻地產生一拖拉庫的測項。
可能是因為此 Project 的主題比較常見,AI 算是猜得滿準的,所以測試項目「有猜到」我想要測的,可以說是生成的精準度頗高,比預期還要好。
其次是「組件行為」的精準度,這部分精準度還好,行為模式和流程有「猜出來」,但使用的方法與驗證項目,這些「細節」則有失精準。
這有點像是:AI 寫了一個乍看頗有道理,但細看根本是在胡說八道的句子。(有用過 AI 的讀者,應該是心有戚戚焉)
在程式碼亦是如此,需要肉眼一行行檢查,檢核 AI 給的程式碼到底寫了什麼,寫法與相應的測試項目,到底「有沒有測到」該測的東西。(有可能 AI 生成的測試項目只是剛好矇對,而沒有測到實際該測的商業邏輯)
總結一下,那這樣說來,AI 提供的測試不是很準確,那我們該用嗎?
我的答案還是「用!」,不用動腦就可以秒產測項,只需要檢查與修改,這樣還是比從零開始寫要輕鬆許多呢。

