在前一章節,我們通過一個實際案例討論了微服務,相信讀者對於它的演進設計脈絡已經有了一定的了解,並對於單體架構和微服務的差異有了具體的體會。不過,微服務涉及的技術範圍相當廣泛,每個主題都可以深入探討,甚至寫成一本書。因此,這章節將對微服務架構設計中常見的問題進行論述介紹,讀者可根據這些主題進行進一步的研究和實踐。
還記得前一章節提到的線上學習平台案例(第22篇)嗎?我們將業務功能拆分成多個服務。首要遇到的問題便是排查問題的複雜性。因為在單體架構中,所有功能都集中在同一個系統內,排查問題時只需要專注在這個系統的內部邏輯。但當我們採用微服務架構時,系統被拆分成多個獨立的服務,這些服務透過API或消息隊列進行交互,因此當某個功能出現異常時,定位問題的範圍不再單純。稍微列一下設計上有哪些做法
當設計一個API服務時,確保它一直正常運作是非常重要的。具體作法通常由監控工具或平台(如 Kubernetes、Load Balancer)來實現。主要會有兩部分來完成
健康檢查端點 : 服務部分,程式內部會提供一個健康檢查的端點(例如 /health)。這個端點回傳應用程式的狀態,例如 "OK" 或 "Unhealthy"。
監控框架或工具 : 監控部分外部工具會定期訪問健康檢查端點,例如常見的 Prometheus + Grafana。而框架部分 .NET 與 Spring Boot 都有簡易輕鬆增加 /health 端點的設定。例如Quarkus設置(使用quarkus-smallrye-health)會如下
// 步驟1: 加入依賴
// 在你的pom.xml文件中加入以下依賴:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-smallrye-health</artifactId>
</dependency>
// 步驟2: 建置健康檢查類
// 創建一個簡單的健康檢查類:
import org.eclipse.microprofile.health.HealthCheck;
import org.eclipse.microprofile.health.HealthCheckResponse;
import org.eclipse.microprofile.health.Liveness;
@Liveness
public class SimpleHealthCheck implements HealthCheck {
@Override
public HealthCheckResponse call() {
return HealthCheckResponse.up("Simple health check");
}
}
監控工具部分,實作面有蠻多不同方式,稍微條例較常見的方式如下
/metrics 端點提供服務指標(請求數量、回應時間、錯誤率、記憶體使用量、CPU 使用率)。定期主動向被監控的應用程式發送 HTTP 請求,結合 Alertmanager 發送警報通知。當服務數量增加時,僅依靠Health Check可能不足以全面了解系統狀況。另外若要了解全面系統狀況,請求跨多個微服務時,追踪請求流向就會變得至關重要。Distributed Tracing有幾個重要目標如下
稍微示意Grafana在Distributed Tracing具體呈現是什麼樣子
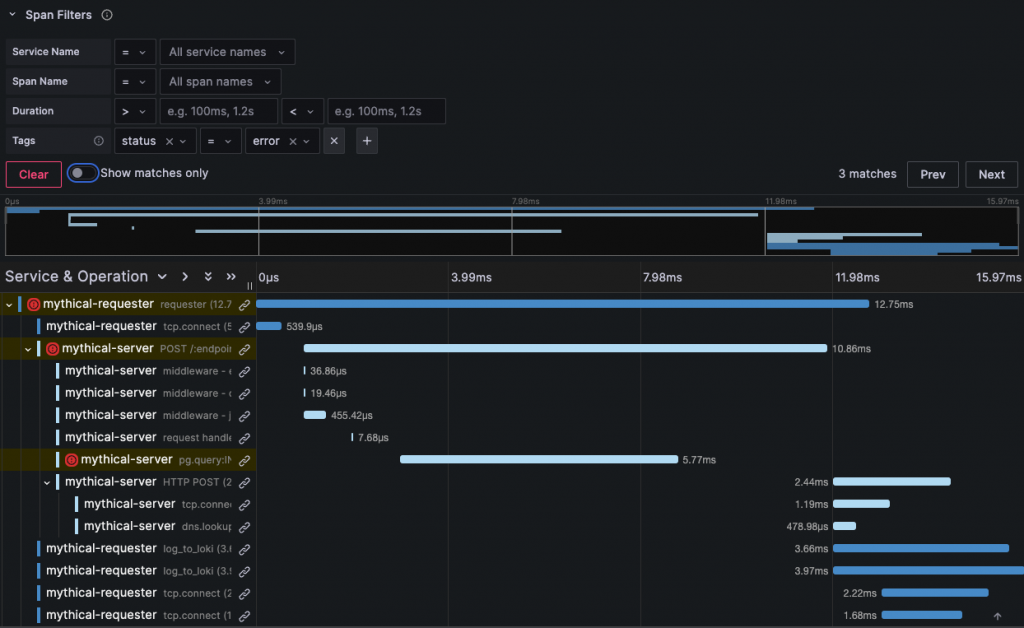
追蹤詳情如下:
紅色圓圈標記的操作可能表示發生了錯誤,包括 mythical-requester 的主要操作和 mythical-server 的 pg.queryn 操作。
實現的話,這部分較常使用的工具為OpenTelemetry ,他為一個開源的可觀測性框架,用於產生、蒐集和匯出遙測資料(包括追蹤、指標和日誌),一般會搭配Prometheus 和 Grafana一起使用。稍微解釋一下這三者的關係
OpenTelemetry 蒐集和標準化來自應用程式的遙測資料,然後傳送到 Prometheus 進行儲存和查詢。Grafana 然後連接到 Prometheus,使用其資料建立視覺化儀表板。簡單呈現如下圖
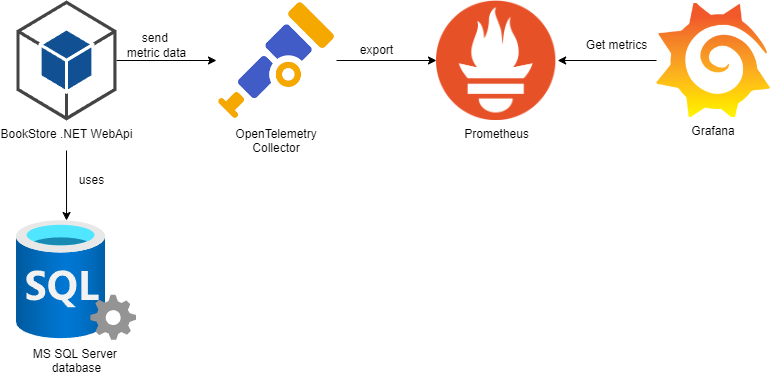
用程式(WebApi)產生遙測資料,OpenTelemetry 負責收集和標準化這些資料後送給Prometheus 作為時間序列資料庫儲存和管理。而Grafana 提供了友善的使用者介面來視覺化呈現這些資料。
基本上OpenTelemetry 算是一個成熟的框架解決方案,它不僅僅是一個工具,而且提供一套完整的架構來處理可觀測性(Observability)的問題。如
因為時間不多…這邊請AI幫我產一個 Quarkus範例
import io.opentelemetry.api.GlobalOpenTelemetry;
import io.opentelemetry.api.metrics.LongCounter;
import io.opentelemetry.api.metrics.Meter;
import io.opentelemetry.api.trace.Span;
import io.opentelemetry.api.trace.Tracer;
import io.opentelemetry.context.Scope;
import javax.inject.Inject;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
// 定義一個 RESTful 資源,路徑為 "/example"
@Path("/example")
public class ExampleResource {
// 注入 OpenTelemetry 的 Tracer 實例
@Inject
Tracer tracer;
// 宣告一個長整數計數器,用於記錄請求次數
private final LongCounter requestCounter;
// 建構子
public ExampleResource() {
// 取得 OpenTelemetry 的 Meter 實例
Meter meter = GlobalOpenTelemetry.getMeter("io.example");
// 建立一個長整數計數器
requestCounter = meter
.counterBuilder("requests") // 計數器名稱
.setDescription("計算請求次數") // 設定描述
.setUnit("次") // 設定單位
.build(); // 建立計數器
}
// 定義一個 GET 方法端點
@GET
@Produces(MediaType.TEXT_PLAIN) // 指定回應的媒體類型為純文字
public String exampleEndpoint() {
// 建立一個新的 span
Span span = tracer.spanBuilder("example-operation").startSpan();
// 使用 try-with-resources 確保 span 在方法結束時正確關閉
try (Scope scope = span.makeCurrent()) {
// 增加請求計數
requestCounter.add(1);
// 為 span 添加一個自定義屬性
span.setAttribute("custom.attribute", "某個值");
// 模擬一些處理時間
simulateWork();
return "你好, OpenTelemetry!";
} finally {
// 確保 span 被正確結束
span.end();
}
}
// 模擬工作負載的私有方法
private void simulateWork() {
try {
// 模擬處理時間為 100 毫秒
Thread.sleep(100);
} catch (InterruptedException e) {
// 如果線程被中斷,重新設置中斷狀態
Thread.currentThread().interrupt();
}
}
}
requestCounter:這是一個長整數計數器(LongCounter),用於計算對 "/example" 端點的請求次數。每次有請求進入 exampleEndpoint 方法時,這個計數器就會增加 1。這個 metric 可以幫助監控 API 的使用頻率和負載情況。
完成了分散式追蹤的介紹後,還有另一個至關重要的可觀測性工具需要關注,那就是集中式日誌管理(Centralized Logging)。雖然分散式追蹤能夠幫助我們在多個微服務間追蹤請求的整個生命週期,了解應用程序的性能和依賴關係,但實際的運行狀態、錯誤以及系統行為的細節通常需要從日誌中查看。
在一個分散式微服務架構下運行時,每個服務都會產生自己的日誌資料。如果我們沒有將這些日誌進行集中管理,開發者就必須登錄到每個服務的節點上來查看各自的日誌。常見的解決方案有
ELK Stack : 由 Elasticsearch、Logstash 和 Kibana 組成
流程上,Logstash 從應用程式、系統或其他數據源收集日誌。將收集到的資料進行處理並傳輸到 Elasticsearch。Elasticsearch 存儲和索引這些日誌,提供高效的檢索功能。最後使用 Kibana 進行可視化和分析,通過查詢和儀表板來檢視系統狀況。
不知道我有沒有記錯,印象Logstash 普遍評價不好用,好像偏向使用Fluent Bit…有記錯請指正我一下
Elasticsearch 的檢索能力非常強大,但索引成本高,簡單來說Elasticsearch 需要對每一條日誌進行全面索引,以實現快速和靈活的查詢。所以當日誌資料量非常龐大時,索引的構建和維護會消耗大量的存儲和計算資源。如果系統並不需要進行複雜的全文檢索,而是只需要基於元資料或標籤來進行檢索(例如:只查找與某個服務、某個 Pod 相關的日誌)那Loki會是比較好的選擇。
稍微用網路的架構圖示意實際Loki架構如下
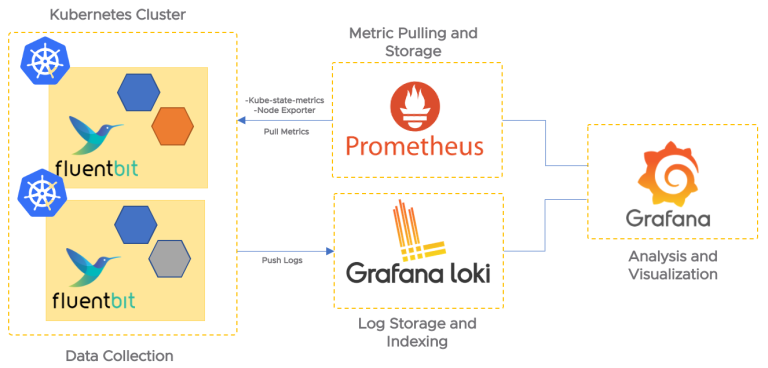
K8s 叢集透過Fluentbit collect將log push到Loki,同時,Prometheus 負責拉取叢集的效能指標。最後,藉由 Grafana 儀表板整合呈現這些日誌和指標,方便營運團隊進行系統監控和問題排查。
講完集中式日誌管理,還有一個重要觀念為Service Mesh,用於更精細的流量管理和安全控制。簡單來說,大型的微服務架構中,各個服務之間的請求流量會變得非常龐大,手動管理這些請求的流向和控制會變得越來越困難(ex:使用配置文件的方式來記錄各個服務的地址)。Service Mesh此時就用來處理,去解決項目如下列
服務間的溝通 : 確保每個服務之間的請求能夠順暢傳輸。
流量管理 : 自動化處理流量管理,確保微服務架構的穩定性和高效運行。 (由Service Discovery, Load Balancing, Traffic Routing三個關鍵功能達成)。
安全性 : 確保所有的服務之間的通信都是加密且可靠的。
整合 : 與日誌管理和分散式追蹤工具的整合。
一樣稍微以現有網路上的架構圖去描述,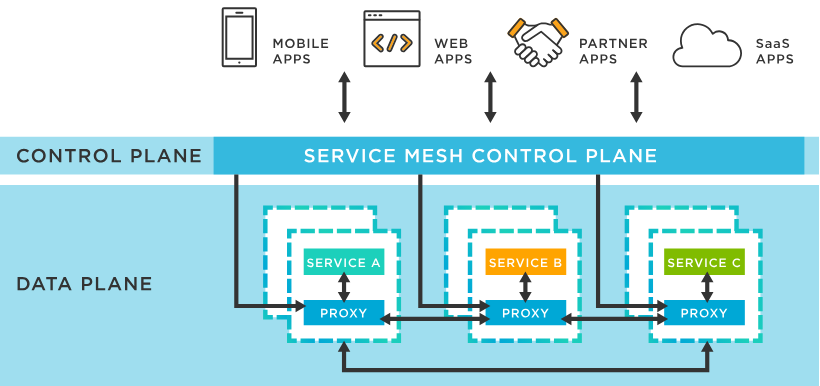
圖中將 Service Mesh 分為兩個主要層次:控制層(Control Plane) 和 資料層(Data Plane)。控制層負責設定和管理網路配置、路由規則與安全策略,並將這些規則下發給資料層中的代理(Proxy)。
資料層部分由每個服務旁邊的 sidecar proxy 組成,負責處理所有進出服務的流量,執行負載平衡、安全加密(如 mTLS)、流量路由等功能。這樣的架構確保了服務之間的通信安全、穩定,並且方便管理和監控。


 iThome鐵人賽
iThome鐵人賽