在台灣多數採用 Power BI 的公司,多數都將資料分析師放在業務部門內,資料團隊只負責將資料放進資料倉儲 / 資料庫中,其他都交由分析師自己處理,而資料分析師處理的流程如下圖:
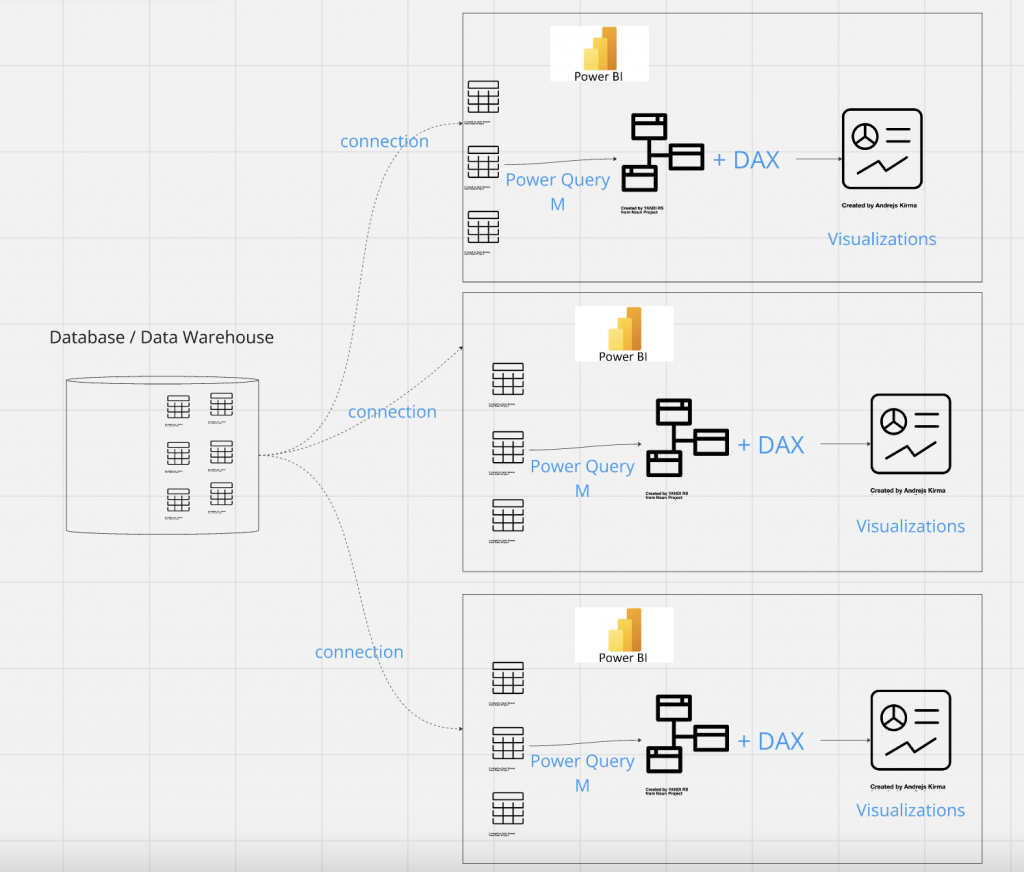
資料分析師一接到需求,便自行利用 Power BI 連接資料庫,選取想要的資料表後,利用內建的 Power Query 進行資料轉換以及資料建模(我目前觀察到的工作生態基本上都是大表,或是自己東拼西湊的資料模型,跟 Dimensional Modeling 相差甚遠),再利用 DAX 定義好 Measure (也就是我們通稱的指標) 後,再生成資料視覺化。
這麼做的缺點主要有三:
1. 每當有新需求產生,就需要重新寫一次 Power Query 以及 DAX。
2. 如果有直接從 database/ data warehouse 撈取資料的需求,那做在 Power Query 內的資料轉換是毫無用武之地。
3. 沒有資料建模的知識,導致 DAX 用的不上手。
要解決上述的缺點,其實很簡單,只需要將資料轉換改成在資料倉儲中進行、理解 Dimensional Modeling,利用 Power BI 的 connection mode,就有機會解決這些問題。
在新的架構中,只需要先使用 dbt 在資料倉儲中完成資料轉換,以及維度表和事實表的建立,再透過 Power BI 建立表格與表格間的關係和 DAX 的定義 (也就是 Semantic Dataset),最後每次接收到需求時,只需要透過 Power BI 內部的 Connection Mode 連接建立好的 Semantic Dataset 就能直接使用定義好的指標,直接拖拉就能完成視覺化。也因為只要拖拉就能完成,在經過適度的教育訓練後,也很有機會能讓商業使用者自己產生想要的報表。
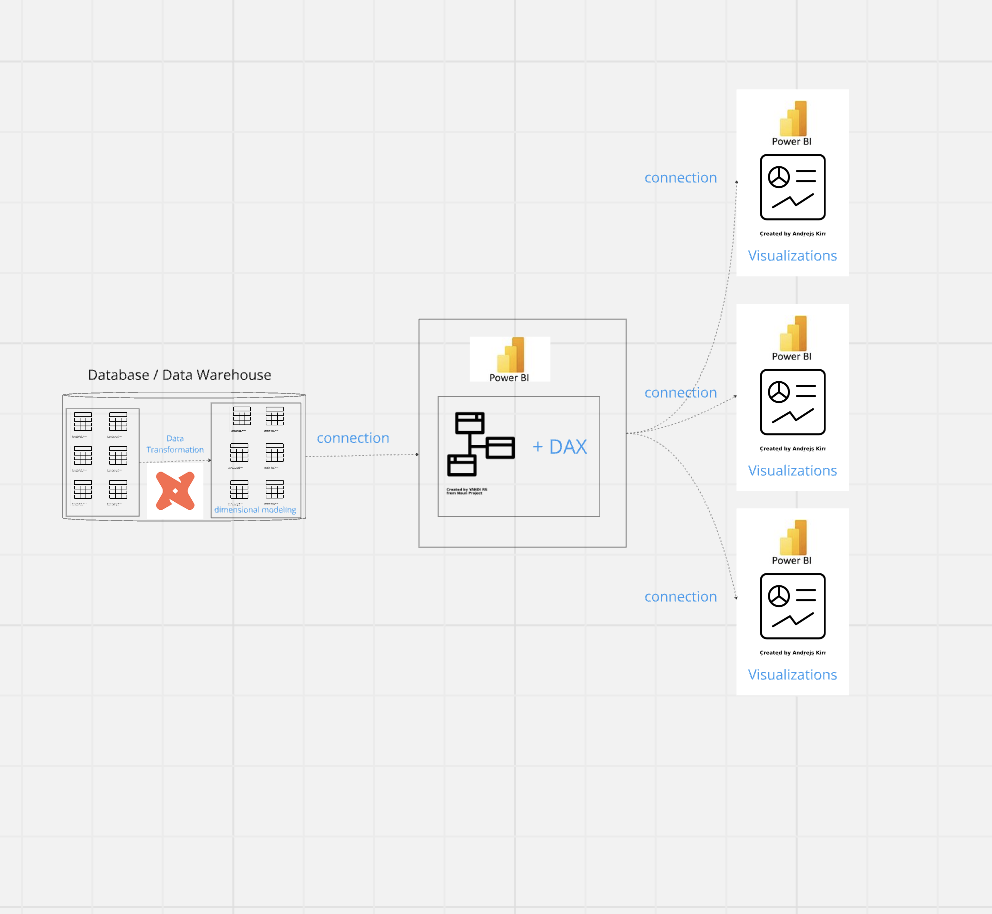
圖中 Data Modeling 就是資料市集,至於該包括哪些商業流程,就看這個專案只想支援單一部門,還是是想做一個企業級的資料倉儲,但如同前面說到的,多數企業都將使用 PBI 的資料分析師放在業務部門內,因此之後的問張就會假設以單一部門為主。這時,如果:
有需要用 SQL 從資料倉儲中撈資料,那就可以用已經建立好的資料市集,程式碼也就多數只需要 join 以及 group by
當新需求進來時,如果該需求只需要定義好的指標,那就只需要做視覺化的部分就可以了。如果該需求需要新增指標,也因為 Dimensional Model 的彈性,就只需要新增的指標,納入原本的 data model 以及 semantic model 之中。
Data Modeling 的知識前面已經講過了,下一篇會先從 dbt 會用到的工具講起。


 iThome鐵人賽
iThome鐵人賽