在以前的文章,我曾提到 Grafana 的開源服務,學一套幾乎其他套都兼用。
Loki、Tempo、Mimir,到 Pyroscope 亦是如此。
下圖是 Loki 架構中的元件組成。圖片來自OpenTelemetry 入門指南 Ch 10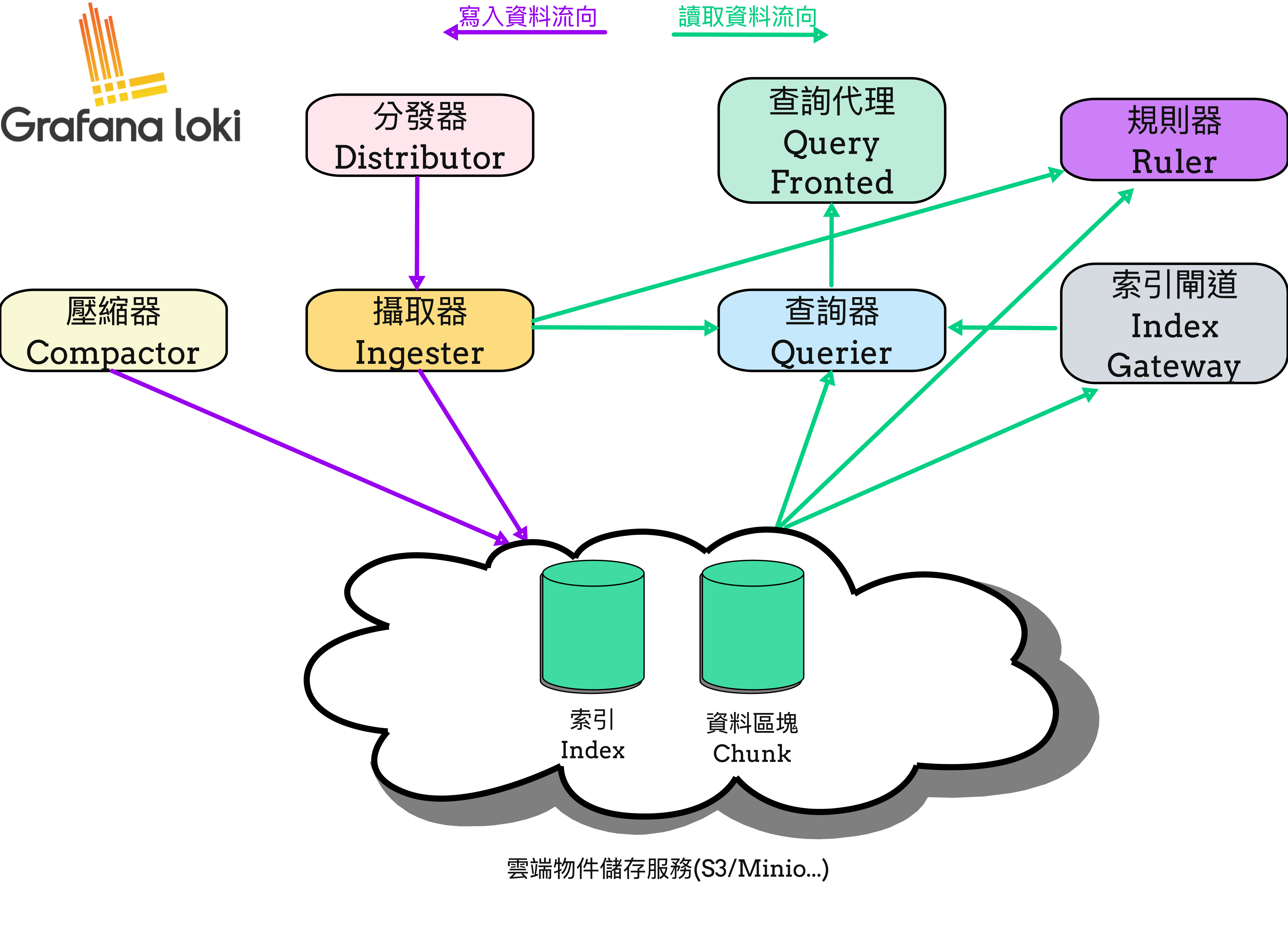
這些熟悉的元件在 Pyroscope 大部分都有一樣的元件存在,且作用是一樣的。
Pyroscope 是一個專門用於 profiling 數據管理和分析的工具,其架構設計基於微服務,這使其具有高度的擴展性和靈活性。Pyroscope 的設計允許用戶輕鬆地在不同環境中進行性能數據的收集、儲存、查詢和可視化,從而幫助用戶快速診斷和優化系統性能。Pyroscope 的微服務架構由多個關鍵元件組成,每個元件各自執行特定的任務,而這些元件在運行時可以彼此協同工作,以完成整個 profiling 的流程。
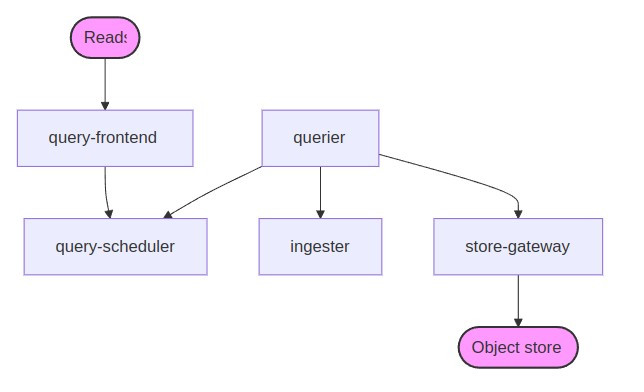
一樣有讀寫元件兩條路徑︰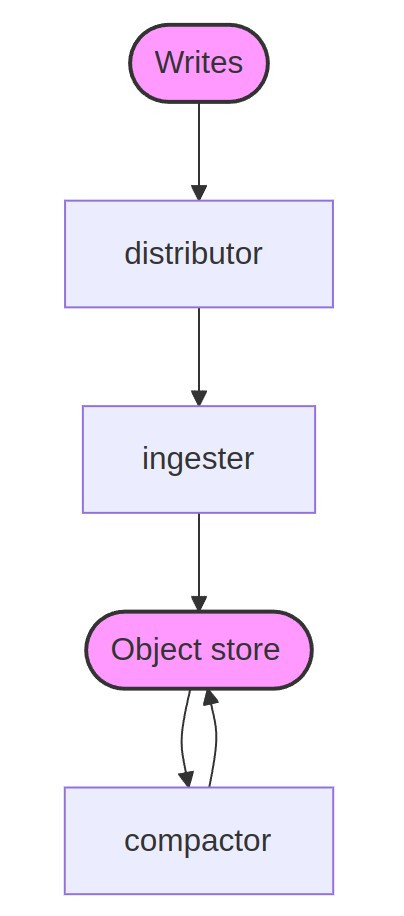
無狀態元件:這些元件不需要持久儲存資料,因此它們可以在重啟後不會丟失任何重要資訊。
有狀態元件:這些元件依賴於非易失性儲存(如硬碟或遠端儲存)來確保重啟後不會丟失資料。
Pyroscope 的核心元件之一是 Distributor。這個元件主要負責接收來自 agent 或 client 的性能剖析數據,並將其分發給多個後端服務進行處理。Distributor 是無狀態的,這意味著它不會保留處理過程中的任何狀態或資料,而是根據接收到的請求,將數據拆分成批次,並以並行的方式發送到不同的 Ingester。每一個序列數據(series)會根據配置的複製因子進行複製和分片。例如,Pyroscope 的預設配置會將每個序列複製到三個不同的 Ingester 中,以確保數據的可靠性和冗餘。Distributor 還會對接收到的數據進行驗證和清理,移除無效的數據樣本,並只將有效的數據傳遞給 Ingester,從而減少後端的處理負擔。Distributor 的無狀態設計和並行處理能力使得 Pyroscope 能夠輕鬆處理大規模的數據流,適應高併發場景。
作為 Pyroscope 架構中的另一個核心元件,Ingester 則是有狀態的。這意味著 Ingester 需要儲存並管理接收到的數據,並確保這些數據能夠在查詢時被有效地檢索。當 Distributor 將性能剖析數據傳遞到 Ingester 時,這些數據不會立即被寫入長期儲存(OSS,AWS S3)中。相反,Ingester 會首先將數據保存在記憶體中,或暫時卸載到本地硬碟。這種設計有助於減少長期儲存的壓力,因為長期儲存往往無法承受頻繁的寫入操作。Ingester 會根據一定的間隔時間,將數據從記憶體或硬碟中批量寫入長期儲存,並壓縮這些數據以提高存儲效率。這種寫入放大(write de-amplification) 機制是 Pyroscope 保持低總擁有成本(TCO)的關鍵因素之一。
除了數據的批量寫入,Ingester 還承擔著數據的複製責任。當 Pyroscope 的集群中某個 Ingester 發生故障時,其他 Ingester 中存有該序列數據的複製,可以確保數據不會丟失。這種複製機制增強了系統的容錯能力,特別是在高可用性要求較高的營運環境中。然而,若多個 Ingester 同時失效,則可能會導致某些數據序列的丟失,這是系統在極端情況下的風險之一。
在 Pyroscope 的查詢過程中,Query-Frontend 是負責處理和加速查詢的無狀態元件。當查詢請求到達 Query-Frontend 時,它首先會檢查這些請求是否可以從快取中直接提供結果,或是否需要進一步分片和排程。如果查詢需要進行計算,Query-Frontend 會將查詢請求傳遞給 Query-Scheduler,後者維護著一個記憶體中的查詢隊列。Query-Scheduler 的主要職責是負責將查詢分配給可用的 Querier,並確保每個查詢能夠被公平地處理。Querier 是具體執行查詢的元件,它從 Query-Scheduler 中提取任務並進行計算,然後將結果返回給 Query-Frontend,最終由 Query-Frontend 將結果發送回給客戶端。這種分布式查詢處理架構大大提高了系統的查詢效率,並能夠在多租戶環境下確保查詢的公平性和負載均衡。
Pyroscope 的架構還包含一個重要的元件,稱為 Compactor。Compactor 是用於優化數據儲存和查詢性能的元件。其主要作用是將來自多個 Ingester 的數據區塊進行合併,從而減少數據冗餘,並降低長期儲存的使用量。Compactor 的壓縮過程分為兩個階段:垂直壓縮 和 水平壓縮。垂直壓縮負責將相同時間範圍內的數據區塊進行合併,並移除重複的樣本;而水平壓縮則是將相鄰時間範圍內的數據區塊合併,從而進一步減少存儲空間的使用。這種壓縮策略不僅能減少存儲成本,還能提高查詢的速度,因為查詢過程中需要處理的區塊數量變少了。
整體來看,Pyroscope 的架構設計高度模組化,並且充分考慮了 profiling 數據的處理需求。每個元件在其各自的領域內發揮了關鍵作用,例如 Distributor 的數據分發與驗證、Ingester 的批次寫入與複製、Query-Frontend 與 Query-Scheduler 的查詢加速以及 Compactor 的數據壓縮等。這些元件的無縫協作使得 Pyroscope 能夠在大規模系統中運行,同時保持高效和穩定的性能。
Pyroscope 的微服務架構還具備靈活的部署模式。根據需求,Pyroscope 可以以 Monolithic 模式運行,這意味著所有的元件會在一個進程中運行,適合於開發或小規模測試環境。然而,對於營運環境,Pyroscope 更推薦使用 Microservices 模式,這樣每個元件可以獨立運行並根據需要水平擴展。例如,當查詢請求量增大時,Query-Frontend 和 Query-Scheduler 可以單獨進行擴展,而不影響其他元件的性能。這種靈活的擴展能力使得 Pyroscope 能夠應對各種不同規模和負載的系統需求。


此外,Pyroscope 還集成了多種長期儲存選項,用戶可以根據需求選擇使用 Amazon S3、Google Cloud Storage 或本地文件系統等作為長期儲存後端。這些存儲選項使得 Pyroscope 的架構更具靈活性,能夠適應不同的部署環境。Compactor 和 Ingester 會定期將數據上傳到長期儲存,確保數據的持久性和可檢索性。
總結來說,Pyroscope 的架構設計不僅考慮了性能剖析數據處理的效率,還注重了系統的擴展性和高可用性。無論是在大規模營運環境中,還是在小規模開發測試環境中,Pyroscope 都能夠靈活地進行配置和部署,從而提供穩定、高效的性能剖析數據管理解決方案。其模組化的設計理念,無狀態和有狀態元件的結合,以及強大的數據複製和容錯機制,都是 Pyroscope 能夠成為性能剖析工具中的佼佼者的原因。
所以投資在 Grafana ecosystem 的維運團隊其實不用學習太多套的架構與組成方式。而且查詢用的 API 也幾乎格式相同,監控指標也是大同小異。算是很好重複利用的。
好處還有 AWS S3 的管理也就很簡單了,就都信任這些服務就好。只要 VPC endpoint 設置好。AWS S3 成本真的超低,只要私有網段要存取 S3 記得設置 vpc endpoint,那這些遙測資料的儲存費用幾乎能低到無視。跟公司其他服務的費用相比幾乎是 1-3%。


