在本節中,我們將探索強化學習(Reinforcement Learning,RL)的基本概念,以及如何將其應用於金融交易,以開發自適應的交易策略。我們將從理論出發,了解強化學習的核心組成部分,深入介紹深度Q網絡(Deep Q-Network, DQN)的原理和實現,並通過 from-scratch 實踐示例,展示如何使用DQN算法來優化交易決策,包括其損失函數的詳細解釋,明日則會使用廣用的套件來展示。今日 Colab。
人工智慧的三大領域:強化學習是機器學習的三大分支之一,與監督學習和非監督學習並列。
應用範圍廣泛:強化學習在遊戲、機器人控制、自動駕駛等領域取得了顯著的成果。
動態決策:金融市場是一個複雜的動態環境,需要連續的決策過程。
自適應策略:強化學習可以通過與環境的交互,不斷學習和優化策略,適應市場的變化。
最大化長期收益:強化學習的目標是通過累積獎勵,最大化長期回報,這與投資的目標一致。
讓AI自己找尋最佳策略:透過 Reward 的設計讓AI可以找到適合處理複雜的邏輯。

代理(Agent):學習並執動作作的主體,在交易中可以視為交易策略或機器人。
環境(Environment):代理所處的外部系統,在交易中即為金融市場。
狀態(State, S):環境在某一時刻的描述,如價格、技術指標等。
動作(Action, A):代理可以採取的動作,如買入、賣出、持有。
獎勵(Reward, R):代理採取動作後獲得的反饋,用於評估動作的好壞。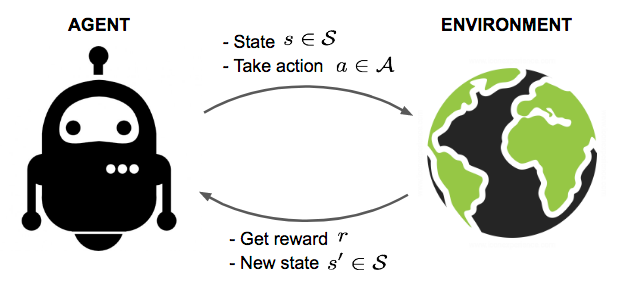
策略(Policy, \pi):代理從狀態到動作的映射,即在某一狀態下應該採取的動作。
值函數(Value Function, V(s)):在狀態 s 下,預期能夠獲得的累積獎勵。
目標:學習最優策略 \pi^*,使得累積獎勵最大化。
模型驅動(Model-based):代理對環境有模型,可預測未來狀態。
無模型(Model-free):代理不知道環境的模型,通過試錯進行學習。
值函數方法:如Q學習,學習狀態-動作對(state-action pair)的值。
策略梯度方法:直接優化策略函數。
狀態空間:包括價格、技術指標、成交量等市場資訊。
動作空間:買入、賣出、持有。
獎勵機制:通常與交易收益相關,如實現的利潤或資產增值。
策略表示:可以使用深度神經網絡來表示策略函數或值函數。
決策過程:代理根據當前的狀態,選擇最優動作。
Q學習(Q-Learning):一種經典的無模型強化學習算法。
深度Q網絡(Deep Q-Network, DQN):結合深度學習的Q學習,適合處理高維度的狀態空間。
策略梯度方法:如A2C、PPO等,直接優化策略函數,效果更佳。
Q學習回顧
Q函數(動作價值函數):Q(s, a),表示在狀態 s 下採取動作 a 所能獲得的期望累積獎勵。
Bellman方程:
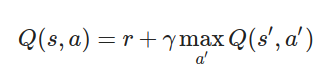
r:當前獎勵\gamma:折扣因子,介於 [0, 1]
s':下一狀態a':下一狀態下的可能動作DQN的改進
使用神經網絡近似Q函數:由於狀態空間可能非常大,無法用表格表示Q函數,DQN使用深度神經網絡作為函數逼近器。
經驗回放(Experience Replay):將代理的經驗存儲在記憶庫中,隨機抽取小批量樣本進行訓練,打破數據的相關性,提高樣本效率。
固定目標網絡(Fixed Target Network):使用一個拷貝的目標網絡來計算目標Q值,定期更新,穩定訓練過程。
目標Q值的計算
目標Q值(Target Q Value):
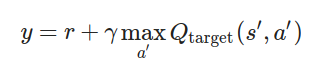
Q_{\text{target}}:目標網絡的Q函數損失函數
均方誤差損失(Mean Squared Error Loss):
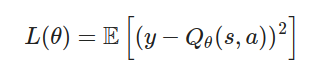
\theta:當前網絡的參數Q_{\theta}(s, a):當前網絡的Q值優化目標
L(\theta),調整網絡參數 \theta,使得當前網絡的Q值逼近目標Q值。初始化:建立當前Q網絡 Q_{\theta} 和目標Q網絡 Q_{\theta^-},並將參數 \theta^- 設置為 \theta。
經驗回放記憶庫:建立一個固定容量的記憶庫,用於存儲代理的經驗 (s, a, r, s', done)。
重複以下步驟:
狀態觀測:從環境獲取當前狀態 s。
選擇動作:使用 \epsilon-貪婪策略,選擇動作 a:
\epsilon 隨機選擇動作(探索)。1 - \epsilon 選擇最大Q值的動作(利用):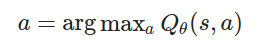
執行動作:在環境中執行動作 a,獲得獎勵 r 和下一狀態 s'。
存儲經驗:將 (s, a, r, s', done) 存入記憶庫。
隨機採樣:從記憶庫中隨機抽取一個小批量經驗。
計算目標Q值: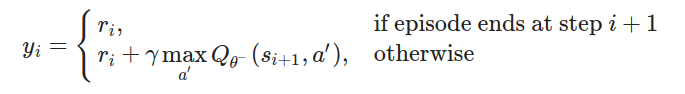
計算損失:
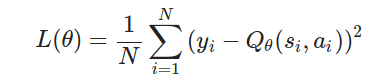
梯度下降更新參數:使用優化器(如Adam)最小化損失 L(\theta)。
更新目標網絡:每隔 C 步,將 \theta^- 更新為 \theta。
調整探索率 \epsilon:隨著訓練進行,逐漸減小 \epsilon,從探索轉向利用。
安裝必要的庫
!pip install torch torchvision
!pip install gym
!pip install pandas numpy matplotlib
#如果在本機上
#pip install torch torchvision
#pip install gym
#pip install pandas numpy matplotlib
導入庫
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
在應用強化學習於交易時,我們需要建立一個環境,讓代理(Agent)可以與之互動。這個環境需要模擬真實的交易情況,包括價格變化、持倉狀態、資金狀況等。
2.1 為什麼需要自定義環境
Gym庫的限制:OpenAI 的 Gym 庫提供了許多現成的環境(如經典控制、遊戲等),但並沒有針對股票交易的預設環境。
特定需求:金融交易環境具有特殊的需求,如多維度的狀態信息、複雜的交易規則、手續費和滑點等。
2.2 環境的組成
狀態(Observation):
包含市場資訊和代理自身的狀態。
在本例中,狀態包括:
開盤價(Open)
最高價(High)
最低價(Low)
收盤價(Close)
資金餘額(Balance)
持有的股票數量(Shares Held)
動作(Action):
定義代理可以採取的動作。
在本例中,動作空間為離散的三個動作:
0:持有(Hold)
1:買入(Buy)
2:賣出(Sell)
獎勵(Reward):
代理在執行動作後獲得的反饋,用於引導學習。
在本例中,獎勵定義為資產淨值的增減量。
2.3 環境的實現
以下是環境的詳細實現,並附有詳細的解釋:
class StockTradingEnv(gym.Env):
def __init__(self, data):
super(StockTradingEnv, self).__init__()
self.data = data
self.current_step = 0
self.balance = 10000 # 初始資金
self.shares_held = 0
self.net_worth = self.balance
self.max_net_worth = self.balance
self.done = False
# 定義動作空間:0-持有,1-買入,2-賣出
self.action_space = gym.spaces.Discrete(3)
# 定義狀態空間
self.observation_space = gym.spaces.Box(low=0, high=np.inf, shape=(6,), dtype=np.float32)
def reset(self):
self.balance = 10000
self.shares_held = 0
self.net_worth = self.balance
self.max_net_worth = self.balance
self.current_step = 0
self.done = False
return self._next_observation()
def _next_observation(self):
obs = np.array([
self.data.iloc[self.current_step]['Open'],
self.data.iloc[self.current_step]['High'],
self.data.iloc[self.current_step]['Low'],
self.data.iloc[self.current_step]['Close'],
self.balance,
self.shares_held
])
return obs
def step(self, action):
current_price = self.data.iloc[self.current_step]['Close']
self.current_step += 1
if action == 1: # 買入
max_shares = int(self.balance / current_price)
shares_bought = max_shares
self.balance -= shares_bought * current_price
self.shares_held += shares_bought
elif action == 2: # 賣出
self.balance += self.shares_held * current_price
self.shares_held = 0
self.net_worth = self.balance + self.shares_held * current_price
self.max_net_worth = max(self.max_net_worth, self.net_worth)
reward = self.net_worth - self.max_net_worth
if self.current_step >= len(self.data) - 1:
self.done = True
obs = self._next_observation()
return obs, reward, self.done, {}
2.4 程式解釋
__init__ 方法:
初始化環境的各種參數和變數。
self.data:存儲市場數據,用於模擬價格變化。
self.current_step:當前的時間步,用於遍歷數據集中的每一個時間點。
self.balance:代理的資金餘額,初始設定為 10,000 美元。
self.shares_held:代理目前持有的股票數量,初始為 0。
self.net_worth:代理的資產淨值,等於資金餘額加上持有股票的市值。
self.max_net_worth:歷史上資產淨值的最大值,用於計算獎勵。
self.done:環境是否終止的標誌。
self.action_space:定義代理可以採取的動作,共有三個動作(持有、買入、賣出)。
self.observation_space:定義環境的狀態空間,由六個連續的數值組成,代表市場和代理的狀態。
reset 方法:
重置環境到初始狀態,以便開始新的訓練或測試。
重置所有變數,包括資金、持倉、資產淨值和時間步。
調用 _next_observation() 方法獲取初始狀態。
_next_observation 方法:
獲取當前時間步的觀測值(狀態)。
從 self.data 中提取當前時間步的市場數據(Open、High、Low、Close)。
包含代理的資金餘額和持有的股票數量。
返回一個包含六個元素的 NumPy 陣列,作為代理的觀測。
step 方法:
執行代理的動作,並更新環境的狀態。
動作執行:
買入(action == 1):
計算代理可以購買的最大股票數量(max_shares),確保不超過資金餘額。
更新資金餘額(self.balance)和持有的股票數量(self.shares_held)。
賣出(action == 2):
將持有的所有股票賣出。
更新資金餘額,持有的股票數量設置為 0。
持有(action == 0):
狀態更新:
更新資產淨值(self.net_worth),計算當前的總資產。
更新歷史最高資產淨值(self.max_net_worth),用於評估代理的表現。
獎勵計算:
獎勵 定義為資產淨值與歷史最高資產淨值之間的差值。
如果資產淨值超過了之前的最高值,獎勵為正;否則,獎勵為負。
這種獎勵機制鼓勵代理持續提高資產淨值,避免資產的回撤。
終止條件:
self.done = True,表示環境終止。返回值:
新的狀態(觀測值 obs)。
獎勵(reward)。
是否終止(self.done)。
其他信息(此處為空字典 {},可用於擴展)。
2.5 環境設計的注意事項
手續費和滑點:
手續費:在實際交易中,買賣股票會產生手續費,可以在 step 方法中扣除一定比例的費用。
滑點:價格可能因市場流動性等因素而發生偏移,可以在執行買賣時調整成交價格。
資金和持倉限制:
保證金交易:如果允許槓桿交易,需要考慮保證金和槓桿倍數。
持倉限制:確保代理不能賣出超過持有的股票數量,避免出現負持倉。
市場規則:
漲跌停限制:在某些市場中,價格波動有一定的限制,需在價格更新時考慮。
交易時間:模擬交易時間,如開盤和收盤時間,非交易時間不允許下單。
狀態歸一化:
隨機性引入:
安全性檢查:
獲取數據
import yfinance as yf
data = yf.download('AAPL', start='2015-01-01', end='2021-01-01')
data.reset_index(inplace=True)
data = data[['Open', 'High', 'Low', 'Close', 'Volume']]
創建環境實例
env = StockTradingEnv(data)
Agent 類的定義#使用 3 層 FCN 來當作 DQN
class DQN(nn.Module):
def __init__(self, input_dim, action_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.out = nn.Linear(64, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.out(x)
class Agent:
def __init__(self, state_size, action_size):
self.state_size = state_size # 狀態空間的維度
self.action_size = action_size # 行動空間的維度
self.memory = [] # 經驗回放記憶庫
self.gamma = 0.99 # 折扣因子,用於計算未來獎勵的現值
self.epsilon = 1.0 # 探索率(初始值),控制隨機行動的概率
self.epsilon_min = 0.01 # 探索率的最小值
self.epsilon_decay = 0.995 # 探索率的衰減率
self.model = DQN(state_size, action_size) # 當前 Q 網絡
self.target_model = DQN(state_size, action_size) # 目標 Q 網絡
self.update_target_model() # 初始化目標網絡的權重
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001) # 優化器
self.criterion = nn.MSELoss() # 損失函數(均方誤差)
state_size:狀態向量的維度,即環境觀測的特徵數量。action_size:行動的種類數量。在我們的交易環境中,有三個行動:持有、買入、賣出。memory:經驗回放記憶庫,用於存儲代理在環境中收集的經驗樣本 (state, action, reward, next_state, done)。gamma:折扣因子,介於 0 和 1 之間,用於平衡即時獎勵和未來獎勵的重要性。值越接近 1,表示代理更重視長期獎勵。epsilon:探索率,初始為 1.0,表示代理在訓練初期完全隨機選擇行動,以充分探索環境。epsilon_min:探索率的下限,防止探索率衰減至 0,保證代理始終有一定概率進行探索。epsilon_decay:每次更新後,探索率乘以該衰減率,逐漸降低隨機行動的概率。self.model 和 self.target_model:兩個深度 Q 網絡,使用相同的結構,但權重不同。self.model 用於選擇行動和更新權重,self.target_model 用於計算目標 Q 值,定期從 self.model 更新權重。self.optimizer:使用 Adam 優化器,學習率為 0.001,用於更新 self.model 的權重。self.criterion:損失函數,採用均方誤差(MSE),用於衡量預測 Q 值與目標 Q 值之間的差距。更新目標網絡的方法
def update_target_model(self):
self.target_model.load_state_dict(self.model.state_dict())
解釋:
load_state_dict:PyTorch 的方法,用於加載模型的權重參數。def act(self, state):
if np.random.rand() <= self.epsilon:
return np.random.choice(self.action_size)
state = torch.FloatTensor(state).unsqueeze(0)
act_values = self.model(state)
return torch.argmax(act_values, dim=1).item()
解釋:
np.random.rand() <= self.epsilon:產生一個介於 0 和 1 之間的隨機數,如果小於等於探索率 epsilon,則進行隨機探索。np.random.choice(self.action_size) 從可用的行動中隨機選擇一個。state 轉換為 PyTorch 的張量,並增加一個維度以匹配模型輸入的形狀。self.model 對當前狀態進行前向傳播,得到對各個行動的 Q 值估計。torch.argmax 獲取 Q 值最大的行動,並返回對應的行動索引。def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
解釋:
state:當前狀態。action:採取的行動。reward:收到的獎勵。next_state:執行行動後的新狀態。done:是否達到終止狀態(回合結束)。def replay(self, batch_size):
if len(self.memory) < batch_size:
return
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
next_state_tensor = torch.FloatTensor(next_state).unsqueeze(0)
target = reward + self.gamma * torch.max(self.target_model(next_state_tensor)).item()
state_tensor = torch.FloatTensor(state).unsqueeze(0)
target_f = self.model(state_tensor)
target_f = target_f.clone().detach()
target_f[0][action] = target
self.optimizer.zero_grad()
output = self.model(state_tensor)
loss = self.criterion(output, target_f)
loss.backward()
self.optimizer.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
解釋:
batch_size,則不進行訓練,等待收集更多經驗。random.sample 從記憶庫中隨機選取 batch_size 條經驗,組成小批次(minibatch)。done:
next_state_tensor = torch.FloatTensor(next_state).unsqueeze(0)
max_future_q = torch.max(self.target_model(next_state_tensor)).item()
target = reward + self.gamma * max_future_q
target = reward
state_tensor = torch.FloatTensor(state).unsqueeze(0)
target_f = self.model(state_tensor)
clone().detach() 方法斷開計算圖,避免梯度傳播:
target_f = target_f.clone().detach()
target_f[0][action] = target
將梯度緩存清零:
self.optimizer.zero_grad()
通過模型計算輸出:
output = self.model(state_tensor)
使用均方誤差損失函數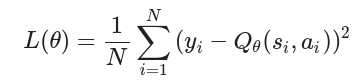
output 是模型當前的預測,target_f 是目標Q值。loss = self.criterion(output, target_f)
反向傳播計算梯度:
loss.backward()
更新模型參數:
self.optimizer.step()
epsilon:
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
模型保存和加載的方法
def load(self, name):
self.model.load_state_dict(torch.load(name))
def save(self, name):
torch.save(self.model.state_dict(), name)
解釋:
load 方法:
torch.load(name):從指定的文件中加載模型權重。self.model.load_state_dict():將加載的權重應用到當前模型。save 方法:
torch.save():將模型的權重保存到指定的文件中。完整的 Agent 類
class Agent:
def __init__(self, state_size, action_size):
self.state_size = state_size # 狀態空間的維度
self.action_size = action_size # 行動空間的維度
self.memory = [] # 經驗回放記憶庫
self.gamma = 0.99 # 折扣因子
self.epsilon = 1.0 # 初始探索率
self.epsilon_min = 0.01 # 最小探索率
self.epsilon_decay = 0.995 # 探索率衰減率
self.model = DQN(state_size, action_size) # 當前 Q 網絡
self.target_model = DQN(state_size, action_size) # 目標 Q 網絡
self.update_target_model() # 初始化目標網絡
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001) # 優化器
self.criterion = nn.MSELoss() # 損失函數
def update_target_model(self):
# 將當前模型的權重複製到目標模型
self.target_model.load_state_dict(self.model.state_dict())
def act(self, state):
# 根據當前狀態選擇行動
if np.random.rand() <= self.epsilon:
# 隨機選擇行動(探索)
return np.random.choice(self.action_size)
# 使用模型預測行動(利用)
state = torch.FloatTensor(state).unsqueeze(0)
act_values = self.model(state)
return torch.argmax(act_values, dim=1).item()
def remember(self, state, action, reward, next_state, done):
# 將經驗存入記憶庫
self.memory.append((state, action, reward, next_state, done))
def replay(self, batch_size):
# 從記憶庫中取樣進行訓練
if len(self.memory) < batch_size:
return
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
next_state_tensor = torch.FloatTensor(next_state).unsqueeze(0)
target = reward + self.gamma * torch.max(self.target_model(next_state_tensor)).item()
state_tensor = torch.FloatTensor(state).unsqueeze(0)
target_f = self.model(state_tensor)
target_f = target_f.clone().detach()
target_f[0][action] = target
self.optimizer.zero_grad()
output = self.model(state_tensor)
loss = self.criterion(output, target_f)
loss.backward()
self.optimizer.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def load(self, name):
# 加載模型權重
self.model.load_state_dict(torch.load(name))
def save(self, name):
# 保存模型權重
torch.save(self.model.state_dict(), name)
損失函數的詳細解釋
計算目標Q值
target = reward
if not done:
next_state = torch.FloatTensor(next_state).unsqueeze(0)
target = (reward + self.gamma * torch.max(self.target_model(next_state)).item())
計算當前Q值
state = torch.FloatTensor(state).unsqueeze(0)
target_f = self.model(state)
target_f = target_f.clone().detach()
target_f[0][action] = target
target_f 是模型對當前狀態的Q值預測,使用 detach() 避免梯度計算。
將目標Q值替換到對應的動作位置。
計算損失
output = self.model(state)
loss = self.criterion(output, target_f)
使用均方誤差損失函數 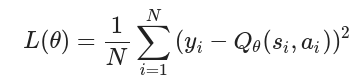
output 是模型當前的預測,target_f 是目標Q值。
更新模型參數
loss.backward()
self.optimizer.step()
更新目標網絡
def update_target_model(self):
self.target_model.load_state_dict(self.model.state_dict())
設置訓練參數
n_episodes = 50
batch_size = 32
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = Agent(state_size, action_size)
訓練循環
import random
for e in range(n_episodes):
state = env.reset()
total_reward = 0
for time in range(len(data) - 1):
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
agent.remember(state, action, reward, next_state, done)
state = next_state
total_reward += reward
if done:
agent.update_target_model()
print(f"Episode: {e+1}/{n_episodes}, Total Reward: {total_reward:.2f}, Epsilon: {agent.epsilon:.2f}")
break
agent.replay(batch_size)
更新目標網絡:在每個episode結束後,更新目標網絡。
打印訓練資訊:輸出當前episode的總獎勵和探索率。
可得以下圖形: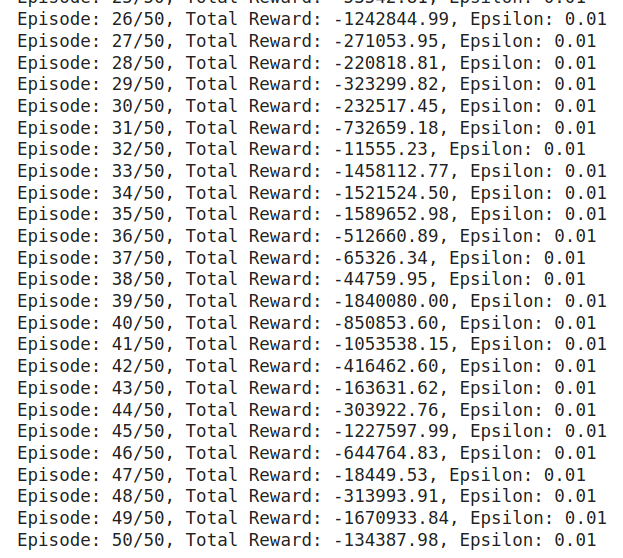
RL 本身容易因為超參數而敏感因此有興趣的人可以嘗試調整看看超參數看有沒有更好的訓練結果
測試代理
state = env.reset()
total_reward = 0
net_worths = []
for time in range(len(data) - 1):
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
state = next_state
total_reward += reward
net_worths.append(env.net_worth)
if done:
print(f"Total Test Reward: {total_reward:.2f}")
break
繪製資產淨值變化
plt.plot(net_worths)
plt.xlabel('Time Step')
plt.ylabel('Net Worth')
plt.title('Agent Net Worth Over Time')
plt.show()
可以看到淨值有上升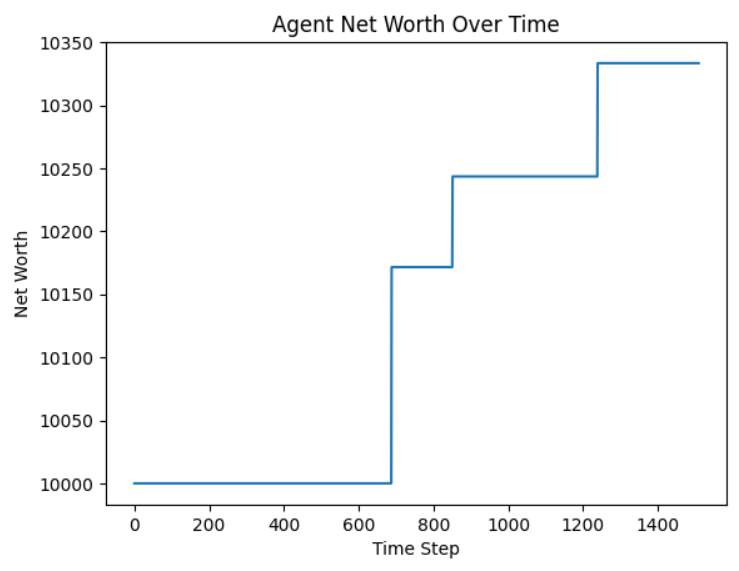
市場的不確定性:金融市場具有高度的隨機性和不確定性,難以預測。
樣本效率:強化學習通常需要大量的數據進行訓練,這在金融領域可能導致過擬合。
風險控制:單純追求收益可能導致高風險,需要引入風險管理機制。
環境設計:需要謹慎設計環境和獎勵機制,確保代理學習到正確的策略。
過擬合問題:採用交叉驗證、早停等方法,防止模型過擬合。
評估方式:使用回測等方法對策略進行全面評估,考慮交易成本、滑點等實際因素。
策略梯度方法:如A2C、PPO,可以直接優化策略,收斂速度更快。
分層強化學習:將決策過程分解為多個層級,提高策略的靈活性。
多資產交易:擴展到多個資產的組合交易。
更多特徵:引入技術指標、基本面數據、新聞情緒等作為狀態特徵。
引入風險約束:如最大回撤、夏普比率等,調整獎勵函數。
風險敏感的策略:採用CVaR等風險測度,優化策略的風險收益比。
在本節中,我們:
深入了解了深度Q網絡(DQN)的原理和實現,包括其損失函數的詳細解釋。
了解了強化學習的基本概念,包括代理、環境、狀態、動作和獎勵等核心組成部分。
探討了如何將強化學習應用於交易,設計了交易環境和代理,並使用DQN進行交易策略的開發。
認識到強化學習應用於交易的挑戰和注意事項,包括市場不確定性、樣本效率、風險控制等。
討論了改進和擴展的方向,如使用更先進的算法、增加狀態和動作空間的維度、引入風險控制等。
通過這次實踐,應該對強化學習在交易中的應用有了深入的了解,並掌握了DQN的核心原理和實現方法。強化學習是一個強大但複雜的工具,需要深入的研究和謹慎的應用。
作業:
嘗試使用其他強化學習算法:如A2C、PPO等,替換DQN,觀察策略的表現差異。
增加狀態特徵:將技術指標、基本面數據等加入狀態空間,提升代理的決策能力。
優化獎勵函數:引入風險控制指標,調整獎勵函數,使代理學習到更穩健的策略。
多資產交易:擴展環境,讓代理可以在多個資產之間進行交易。
透過這些練習,您將能夠更深入地理解強化學習在交易中的應用,並提高模型的實際效果。
提示:
數據預處理:確保數據的質量,處理缺失值和異常值,對數據進行歸一化。
調參技巧:強化學習模型的效果對參數敏感,嘗試不同的學習率、折扣因子等參數。
日誌和監控:在訓練過程中記錄代理的表現,使用可視化工具觀察訓練進展。
注意:
風險提示:金融市場具有高度的不確定性,強化學習模型的預測結果僅供參考,不應作為實際投資決策的唯一依據。
合規要求:在應用交易策略時,需遵守相關的法律法規和市場規則。
倫理考慮:確保模型的設計和應用符合道德和倫理標準,不得利用市場漏洞或進行操縱行為。

