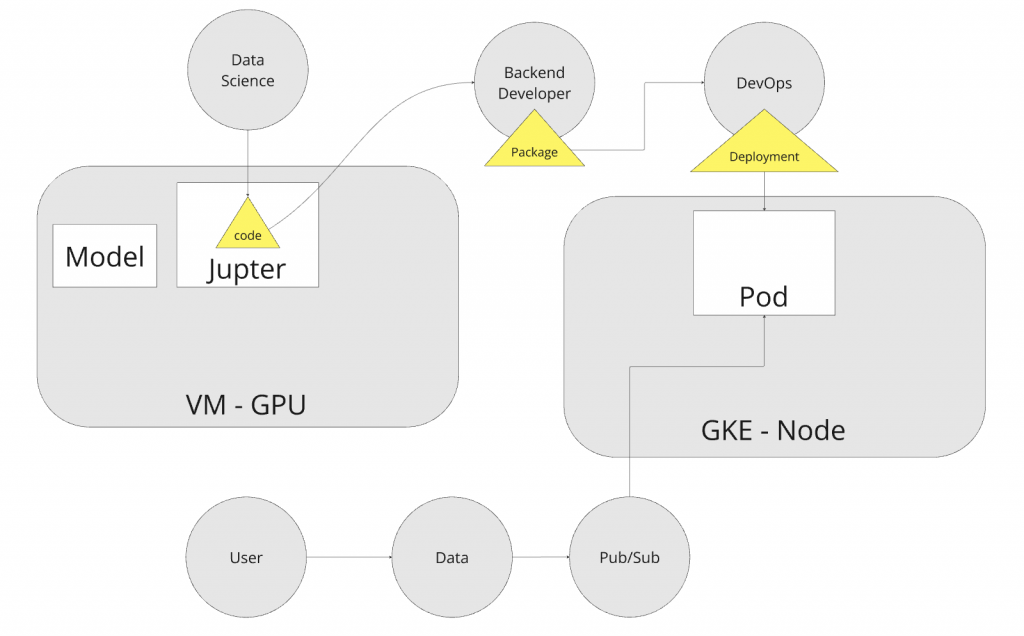
終於有機會接觸 MLops 架構!可以玩玩看不一樣的挑戰。先來看一下需求:現有 ML 的架構大概長這樣:
後端開了一台 gpu 的 VM,在機器上安裝 jupter 跟 pytroch,然後藉由 public url 讓 data 人員可以進行開發並跑 ML。等到 ML 程式開發完之後,會將 code 請後端打包一層 sub 再打包成 image。再請主管將 image 部署在 GKE 架構的正式 GPU instance 上。然後使用者會藉由 cloud run 的 backend 將資料傳進 pub/sub 裡面。整個環節從提供環境(可能要根據 gpu type install 不同 dependency or 環境), 後端打包、部署都需要大量溝通跟人力。這會是接下來要重點處理的項目。
由於沒有看過,我先來研究看看 GCP 官網文件,大概有些概念建立,但可能還需要驗證。
關於 Data Science 需要一個環境來測試 model,我們可以參照文件的 interactive environment,在這個階段會使用 Vertex AI Workbench (Jupyter Notebook service)。
而在operational 環境,我們則會直接將 model 部署在 pipeline 中。
一步步來,我們來拆解如何部署在 Interactive environment
使用 Service Catalog 部署 cloud resource 在這邊可能是 Vertex AI Workbench notebook resource。notebooks
source data 會來源於 outside 環境。Data scientists 可以要求讀的權限,但通常不會給予寫的權限。


 iThome鐵人賽
iThome鐵人賽