
今天要來統整下我在整個 DS 開發預測 app 的過程中到底經歷了哪些事情。
故事背景:
過去在沒有 DevOps 甚至是 CICD 的年代,為了讓 DS 可以進行開發,我們是起了一台 GPU VM,並且在 VM 上用 base image 起 Container 提供 Jupyter Lab 給 DS 開發。
以下為當初使用的 docker compose,請注意 Volume 的設定,之後會考
docker compose -f docker-compose.yml -f docker-compose.dev.yml up
# docker-compose.yml
services:
predict-service:
image: predict-service:latest
ports:
- "8888:8888"
- "80:80"
volumes:
- .:/workspace
# - ./temp:/workspace/temp
working_dir: /workspace
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
# docker-compose.dev.yml
services:
predict-service:
volumes:
- ./config/.ssh/:/root/.ssh/
entrypoint: jupyter lab --ip=0.0.0.0 --port=8888 --no-browser --ContentsManager.allow_hidden=True --allow-root
restart: unless-stopped
當 DS 在Jupyter Lab 開發的時候,除了執行 python 的應用,也會在 ubuntu 環境安裝套件,以下是 DS 的筆記
NVIDIA CUDA 相關 Lib
可能需要更新的libstdc++以支持GLIBCXX_3.4.30
創建了一個從/usr/lib/x86_64-linux-gnu/libstdc++.so.6到/opt/conda/lib/libstdc++.so.6的符號鏈接
Transformers
PyTorch
Datasets
Tokenizers
paddlepaddle-gpu
paddleocr
最終會有兩份檔案要執行
startup.py 以及 predict.py
startup.py 主要是創建 OpenCC 轉換器(簡體到繁體)以及初始化 PaddleOCR(不使用 GPU)
import opencc
from paddleocr import PaddleOCR
converter = opencc.OpenCC("s2t")
ocr = PaddleOCR(use_gpu=False)
predict.py 主要是要接收 job id,然後從對應 job 找到 bucket 取得需要預測的資料。
故事前情提要到這邊,上面都不了解沒關係,只要知道我們當前 Container 有安裝特定套件,以及有兩個檔案需要執行。
但因為開發上 base image 的 ubuntu 套件可能會直接被 DS 安裝更新套件,而這些東西可能不會被 DS 告知,所以會造成原本的 base image 設定遠遠地落後正在使用的狀況。這也導致未來為了在正式環境上運作程式順利,我們是直接在 VM 上執行 docker commit 更新 image。這是第一個手工藝。
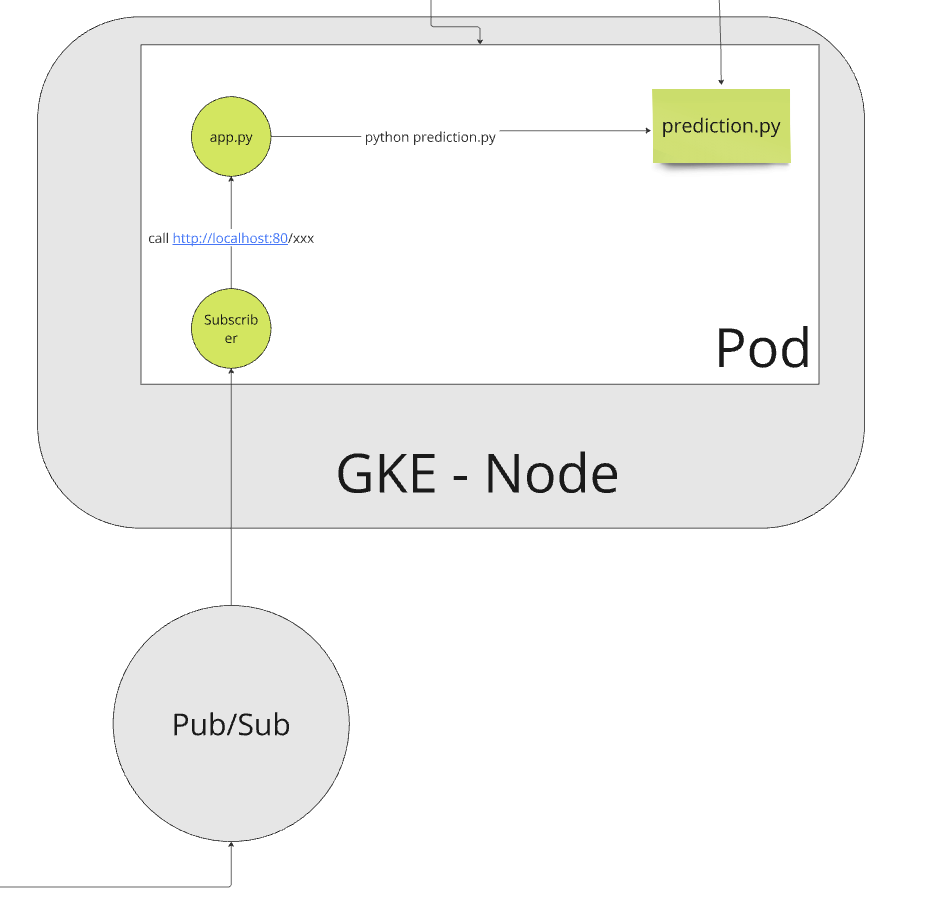
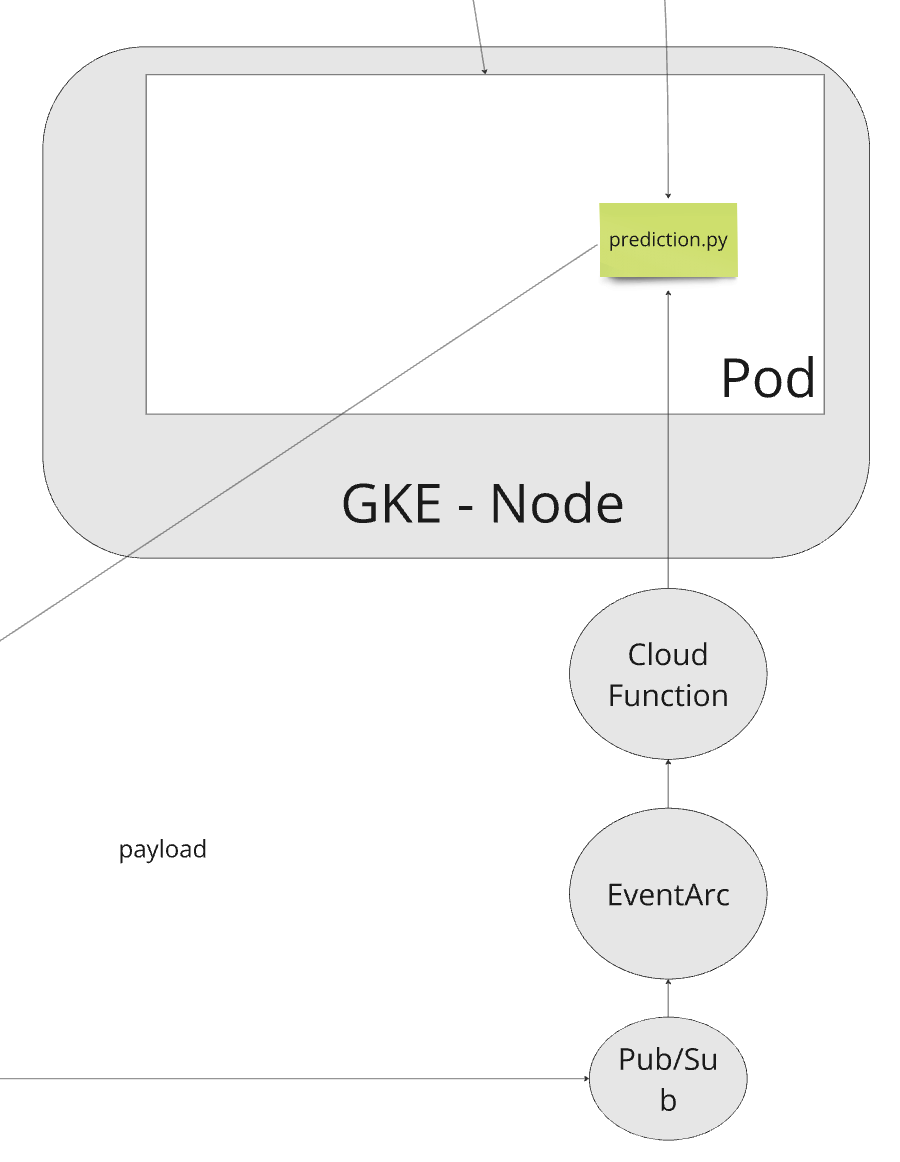
第二個手工藝是因為我們不希望掉資料,所以在 BE 是使用 pubsub 更新 job id。為了要讓 predict.py 可以跟此機制互動。我們是額外建立一個 subscriber.py 做訂閱。並且起一個 app.py 開出 api,當subscriber.py 收到 msg,會打 app.py 的 api。當 app.py 收到後,他會用 sub-process 的方式執行 python predict.py -arg …。而這邊我們都直接埋在 entrypoint 內
#!/bin/bash
python startup.py &&
gunicorn app.main:app &
python subscriber.py
第三個手工藝是結合以上兩點,我們在 DS 開發完要上新版的時候,因為還是要區分正在開發跟部署的 image,所以我們會多一層 release。這邊也會因為 base-image 會涵蓋很多開發的 cache 變超級肥大,所以有進行清除
ARG BASE_IMAGE
ARG CODE_PATH
FROM $BASE_IMAGE
RUN rm -r /root/.cache
COPY $CODE_PATH /workspace
ENTRYPOINT [ "./entrypoint.sh" ]
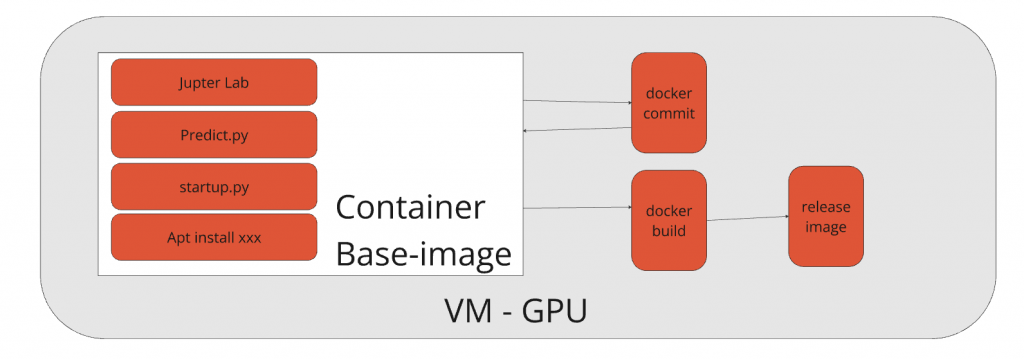
為了解決以上三個問題,並且讓最終 DS 可以自己處理上版,我們做了些優化

 iThome鐵人賽
iThome鐵人賽