接續先前的內容,我們要開始爬取我們要索取的爬蟲了。
首先,我們先把將start_urls的值
修改為需要爬取的第一個URL:
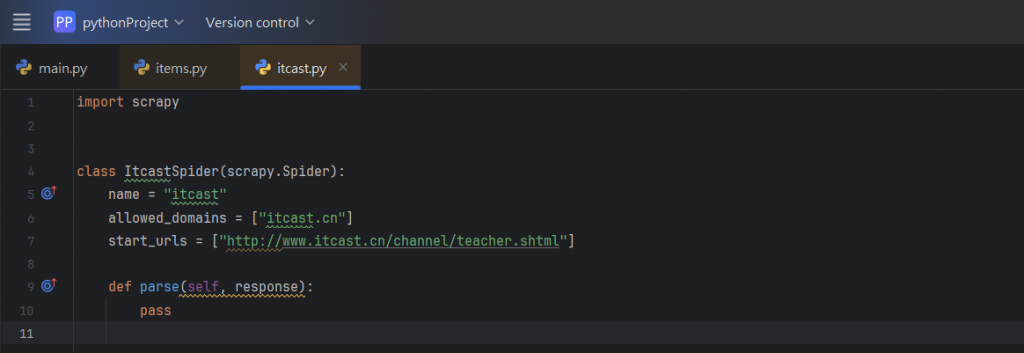
所要爬取的網頁為: http://www.itcast.cn/channel/teacher.shtml
接著,我們再修改下方的程式碼parse():
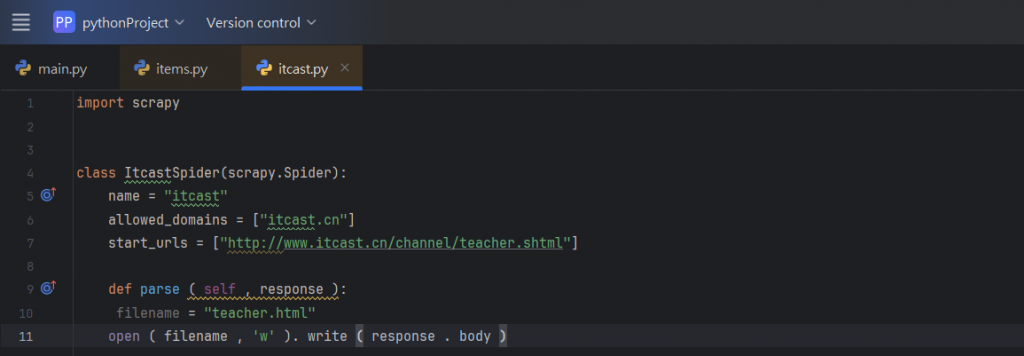
針對修改的方法,這邊再來做一些解釋:
filename = "teacher.html"
這邊新增定義了一個變數 filename,它的值是 "teacher.html",
表示我們要將抓取到的網頁內容存儲到這個名為 teacher.html 的文件中。
而這個文件將會存放在運行爬蟲的目錄中,
也就是我們前一天有提過的爬蟲資料夾內。
open(filename, 'w').write(response.body)
這邊使用 Python 的 open 函數打開或創建名為 teacher.html 的文件。
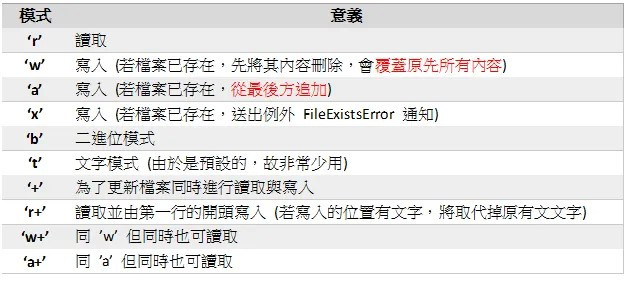
'w' 模式:
這個是在open函數中的一個方法,代表寫入模式,
如果文件不存在,會自動創建。如果文件已經存在,這將覆蓋文件中的內容。
這邊也查詢了其他有關讀寫檔案的語法,大家可以參考一下。
而response.body 就是 Scrapy 從網頁獲得的原始 HTML 資料,
我們使用 write 方法將 response.body 的內容
寫入 teacher.html 文件中。
在最終,我們會在本地文件夾中生成一個 HTML 文件,
保存了這個網頁的完整內容。
修改完程式碼後,我們回到剛剛開啟的cmd中進行執行,
我們要輸入scrapy crawl itcast,這個是在scrapy裡面通用的執行語法。:


但我們可以發現,上面是沒有正確執行的,
我有想到可能是賦值的問題,所以我又對程式碼做了一次更改:
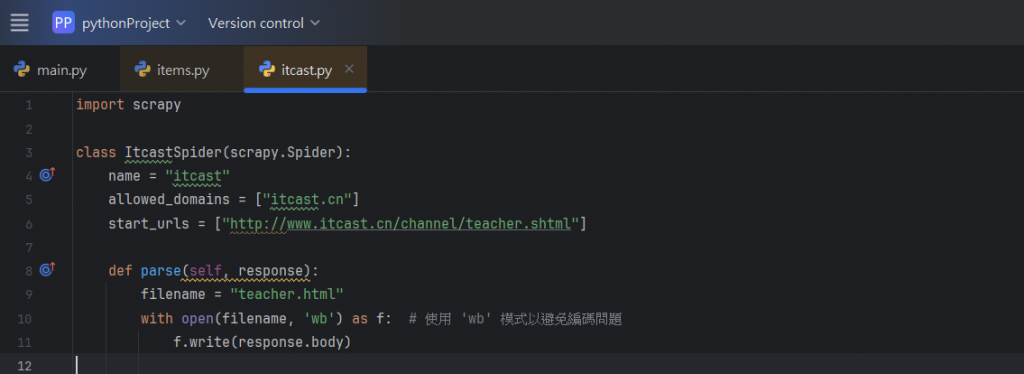
然後在cmd做再一次的執行:
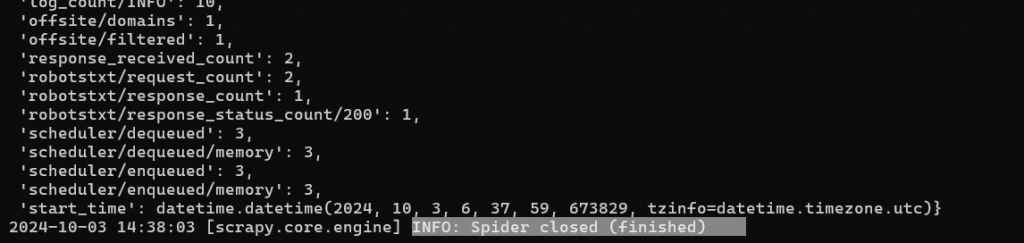
這次則出現了INFO: Spider closed (finished),
代表我們有成功執行了。
我們就可以去本機上的爬蟲資料夾看一下有沒有東西了:
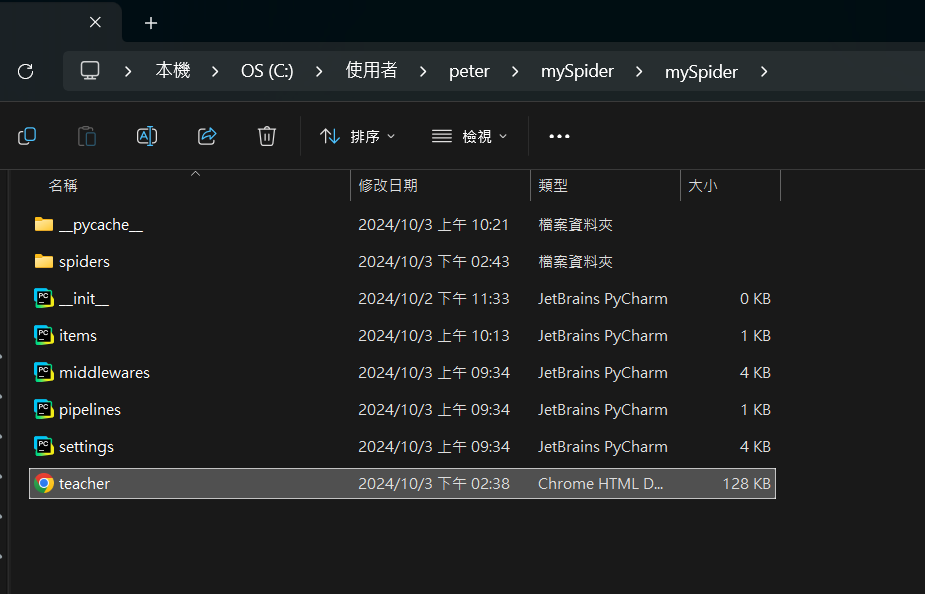
可以發現,我們的資料夾內出現了一個Chrome HTML Document檔案,
我們可以點進去看一下:
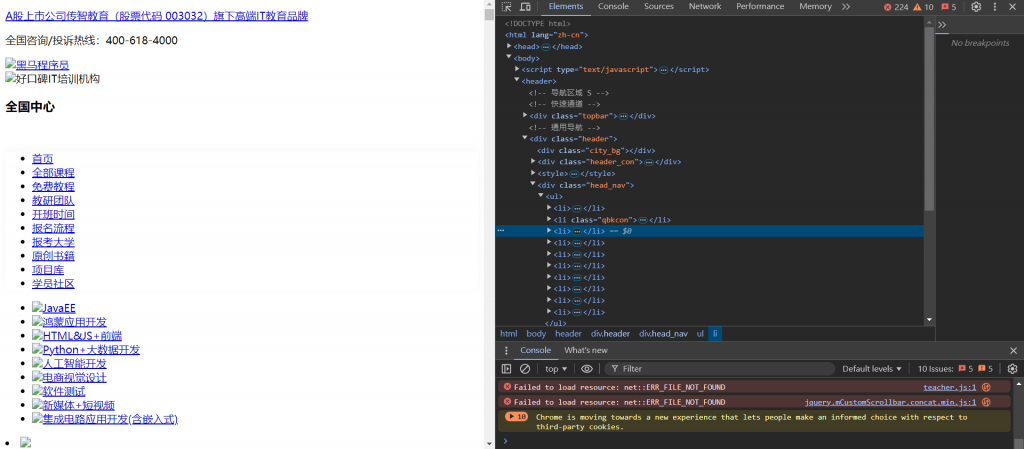
這個就是我們獲取到的網頁了。
那在可以準確的獲取網頁後,我們就要來試著獲取裡面的資訊了。
這邊的目標是想獲取該網頁「導師」相關的訊息,
那因為學習網頁所介紹的Xpath是我之前沒有接觸過的,
學習的時間也相對不足,所以我透過改編程式碼來獲取數據,
而沒有使用範例所推薦的方法。
那就先來看看更改過後的程式碼:
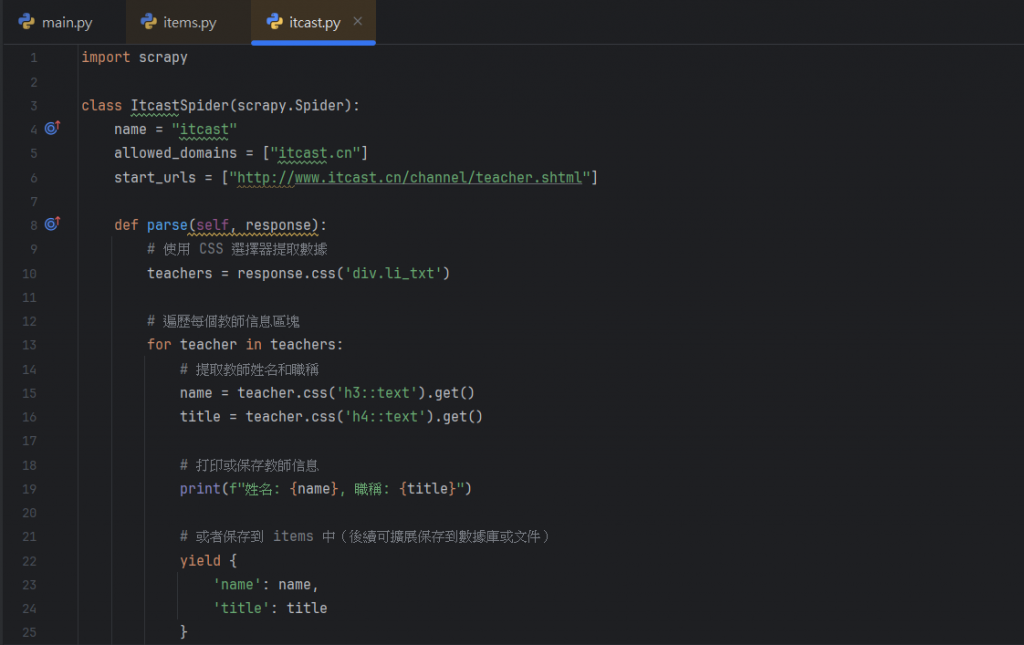
這邊先針對修改的程式碼他們的功用來做一些講解:
teachers = response.css('div.li_txt'):
這一行是使用 Scrapy 中的 CSS 選擇器來抓取包含教師信息的 div 元素。
div.li_txt 就是表示它會選擇所有類名為 li_txt 的 div 元素,
這些元素就包含該網頁教師的姓名和職稱。
for teacher in teachers:
這一行是 for 循環的意思,就是找出從上一行選擇的
所有 div.li_txt 元素,其中每一個 teacher
都是對應於一個教師的 HTML 區塊。
name = teacher.css('h3::text').get():
這行則是一樣使用了 CSS 選擇器來提取教師的名字。
h3::text 選擇 h3 標籤中的文本內容。
title = teacher.css('h4::text').get():
這行則是提取教師的職稱,來使用 h4 標籤中的文本。
(上述兩行都要透過觀察HTML來跟著改變,並非一成不變)
yield { 'name': name, 'title': title }:
這邊就是將每位教師的名字和職稱作為字典返回。
這些數據可以後續處理,例如保存到 JSON 文件或數據庫中。
簡單總結,這段代碼的目的是從指定網頁 http://www.itcast.cn/channel/teacher.shtml
上提取教師的名字和職稱,並且把這些信息抓出來或者保存。
Scrapy 框架會自動幫我們處理好所有 HTTP 請求跟響應,
而我們只需要專注於從回應中提取我們需要的數據就好了。
那知道上述程式碼是什麼功用後,就要直接來執行了:
我們這邊用的執行碼是scrapy crawl itcast -o teachers.json,
簡單來說就是把獲取的數據轉換成JSON檔來呈現:

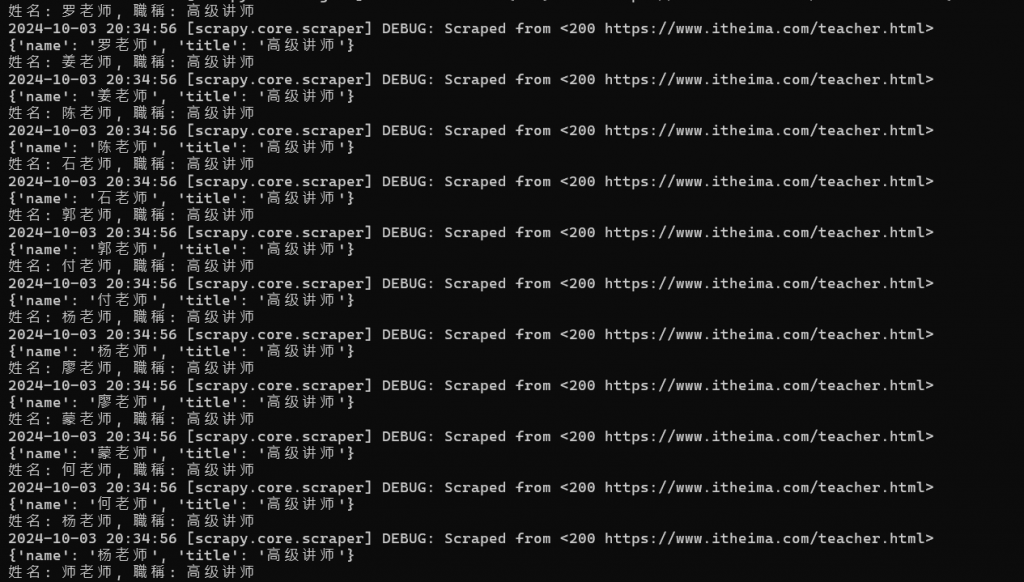

如果有出現上述的畫面跟最後的INFO: Spider closed (finished),
就代表我們成功執行了。
接著我們就可以回到本機內的爬蟲資料夾內,來看看有什麼變化:
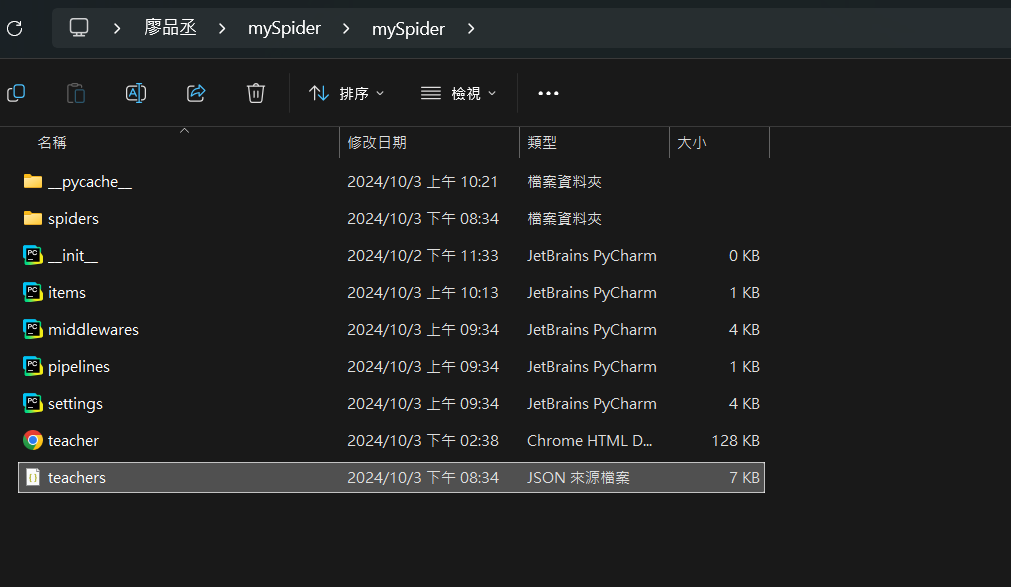
可以看到上面多出了一個JSON檔,這就是我們剛剛所產生出來的成果。
那我們就點進去來看一下:
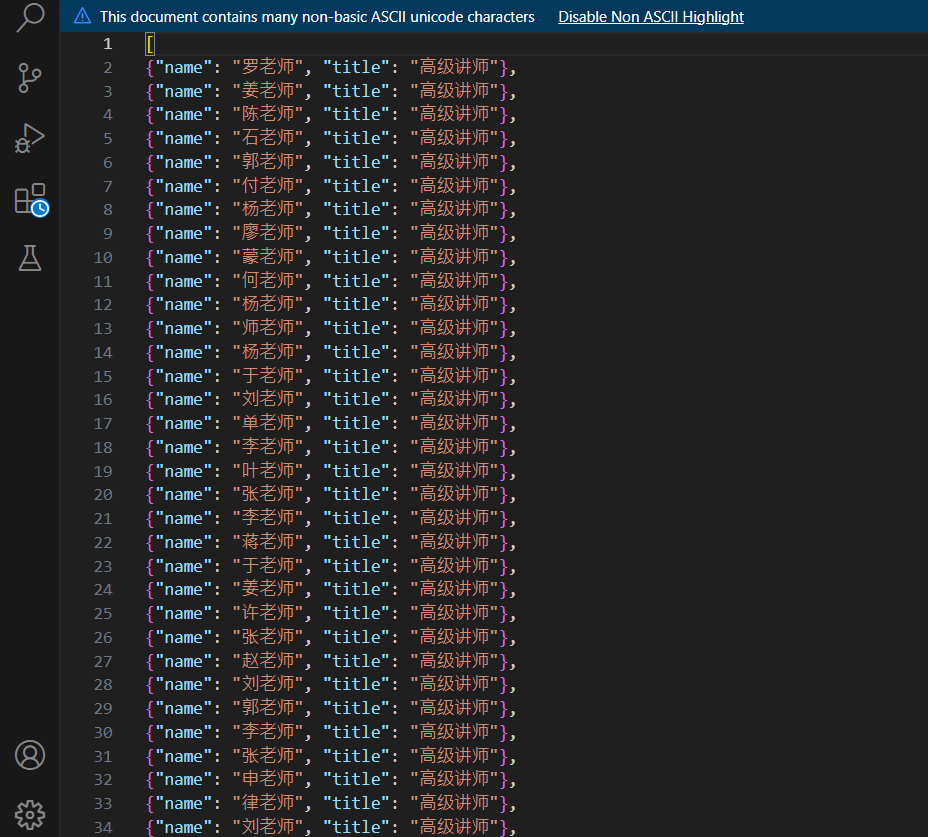
這就是我們所想要抓取的成果了,收工!!!
我們利用這兩天的時間學習了scrapy的相關內容,
必須要說,Scrapy的學習真的比其他的爬蟲工具還要麻煩許多,
最直觀的就是不是透過在編譯器內直接執行,而是需要跳到專案目錄中,
光是這點就令我頭痛不少。
不過透過這兩天的學習,我也對於scrapy的知識增進不少,
無論是語法或者是它的操作方式,都讓我對於爬蟲概念又更加進步了。
參考資料:
https://www.runoob.com/w3cnote/scrapy-detail.html
https://ghost831105.medium.com/python%E5%AD%B8%E7%BF%92%E6%97%A5%E8%AA%8C-%E6%AA%94%E6%A1%88%E8%AE%80%E5%8F%96-%E5%AF%AB%E5%85%A5-%E6%A8%A1%E5%BC%8F%E6%AF%94%E8%BC%83-r-a-w-caac9e1aef72

