那在今天,我們就要學習我們的最後一個常見的爬蟲庫 – Scrapy,
那廢話不多說,直接進入正題:
同樣的,在學習一個東西之前,我們應該先了解它是一個什麼東西:
簡單來說,Scrapy 就是一個開源且功能強大的 Python 爬蟲框架,
用來高效地抓取網頁數據並進行數據處理。
它的設計目的主要是為了簡化網頁數據抓取過程,並提供一個全面的工具集,
適用於多種爬蟲需求,無論是簡單的網頁數據提取,
還是更複雜的多頁面數據爬取,它都是一個可以使用的工具。
可能有人就會問了「不是阿,阿聽起來跟其他的爬蟲工具都長一樣啊,
什麼BeautifulSoup、Selenium不是也都是這個功能」,
那我想我們也應該要釐清一下它跟其他工具的最大差別:
簡單來說,如果你需要處理大量的靜態網頁、需要高效爬取
且對動態渲染要求不高,那麼 Scrapy 是最佳選擇。
它的異步架構非常適合大規模爬取任務。
再換一個方式來說,如果你的目標網頁是
動態渲染的(如使用 JavaScript 加載內容),或者需要
模擬用戶行為(如點擊、滾動、表單提交等),那Selenium 會比較合適。
而若是你只是需要從靜態網頁中提取數據時,尤其是小規模爬取目標的話,
BeautifulSoup 和 requests 搭配使用是一個輕量級且簡單的選擇。
總而言之,Scrapy就是比較適合進行大規模的靜態抓取任務,
使用者也可以透過自己的需求去選擇使用的工具。
在了解完它的功能後,我們就要進到操作的部分了。首先當然是安裝:
我們一樣使用Win + R開啟cmd,並輸入安裝語法:
pip install scrapy,讓系統進行Scrapy的安裝。
在下一步,我們就是要來測試剛剛是否有進行正確的安裝。
在這邊我們輸入scrapy bench,再看一下下面系統的回應。
而若是系統沒有顯示錯誤的訊息,那代表Scrapy 已經成功安裝
並運行了基準測試 (scrapy bench)。接著就可以進行實際程式撰寫了。
我打算參考https://www.runoob.com/w3cnote/scrapy-detail.html
中的資料,並按照裡面的內容一步步學習。
首先,我們要在cmd中輸入指令scrapy startproject mySpider,
以此在電腦中創建一個名為mySpider的專案。
那資料夾內部的內容如下:
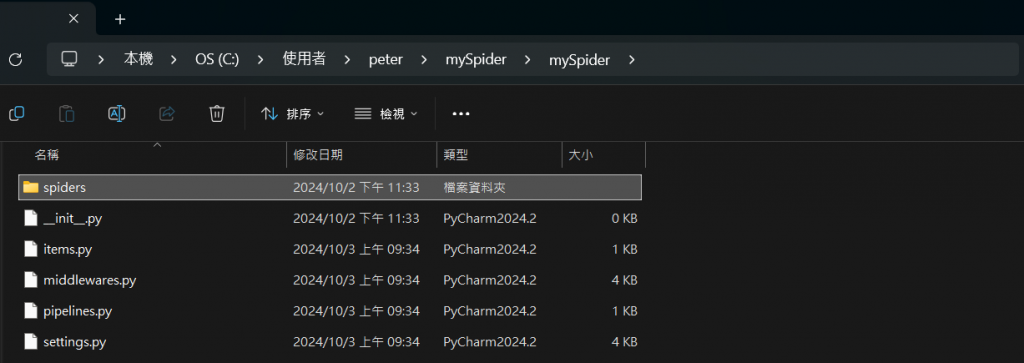
這邊也簡單介紹一下裡面的每個東西都是什麼:
spiders/:
這是存放所有爬蟲檔案的資料夾。每次創建一個新的爬蟲,
Scrapy 就會將該爬蟲的 Python 文件放在這個資料夾裡。
init.py:
這是一個空的 Python 文件,它告訴 Python 把 mySpider 資料夾
視作一個模組。這樣就可以從這個模組中引入其他檔案或函式。
items.py:
這個文件用來定義爬取數據的結構。可以在這裡指定要抓取的字段,
例如:標題、描述、價格等。
middlewares.py:
這裡可以定義一些中間件,用於修改請求或回應的處理邏輯。
pipelines.py:
在這裡定義管道,用來處理爬取到的數據,通常用來保存或清理數據。
settings.py:
這是專案的設定檔,用來設定專案的各種配置選項,
如下載延遲、User-Agent、啟用的擴展等。
接下來,我們要先定義我們的目標網站,我這邊一樣是按照範例的https://www.itheima.com/teacher.html
作為我們這次的目標網站。
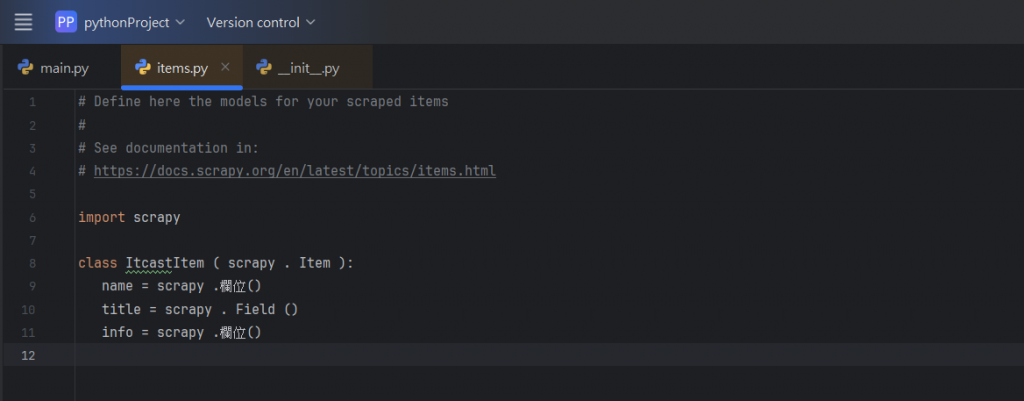
然後,我們要在剛剛講到的item中建立一個ItcastItem 類,
和建立item 模型(model):
再來,我們就要進行到爬蟲的正式部份了。首先是第一步-爬數據:
我們一樣的要先開啟cmd作為輸入的地方,
然後我們要進入已經建立的 Scrapy 專案目錄,所以要先導入方向:

我們使用了cd C:\Users\peter\mySpider\mySpider來進入專案。
接著,我們再輸入指令scrapy genspider itcast "itcast.cn":
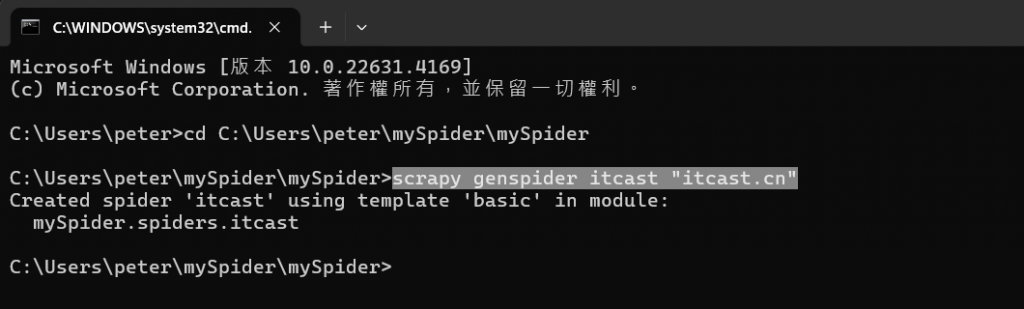
這行命令的目的主要是自動生成一個新的爬蟲文件,
並且指定該爬蟲的目標域名為 itcast.cn。這可以讓 Scrapy 快速生成
基本的爬蟲結構,讓你可以專注於編寫實際的爬取邏輯,
而不必從零開始手動編寫所有代碼 (自己寫太累了)。
輸入完後,你就可以發現在你的spider資料夾中多出了個東西:
我們把剛剛建立的itcast.py打開,就可以發現裡面新增的內容:
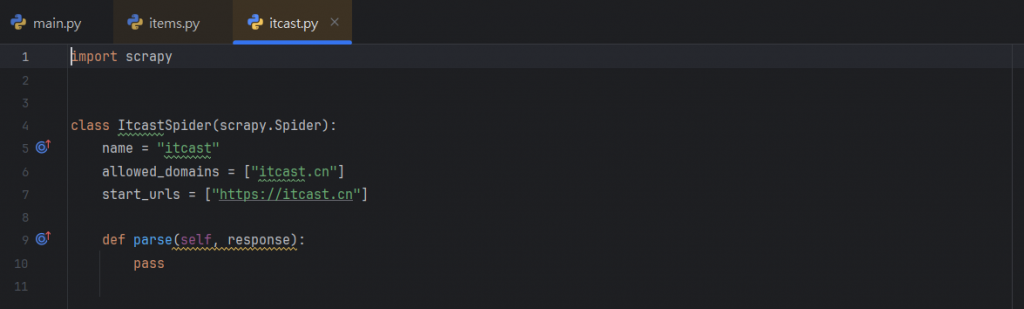
那在這邊也來稍微解釋一下這幾行的意思:
name = "itcast":
這是爬蟲的名稱,與在命令中指定的名稱一致。
allowed_domains = ["itcast.cn"]:
這告訴 Scrapy 只允許爬取 itcast.cn 這個域名下的網頁。
如果網站的域名不在這個列表中,Scrapy 將忽略該網站的請求,
從而限制爬蟲只抓取特定的網站,
防止爬蟲無意中抓取了其他不相關的域名內容。
start_urls:
這是爬蟲開始抓取的起始網址列表。當啟動爬蟲時,
它會從這裡列出的 URL 開始進行抓取,是爬蟲開始爬取的起始 URL 列表。
parse:
這是爬蟲的主要解析方法,我們可以在這裡編寫解析網頁內容的邏輯,
處理從網站獲得的 HTTP 響應。
上面的這段全部代碼是 Scrapy 自動生成的爬蟲框架,
它幫助我們可以快速搭建起基本的爬蟲結構,
而我們也可以在這個基礎上編寫爬蟲的邏輯來解析網站數據。
(下篇續……)

