在之前的學習中,我們深入探討了注意力機制和視覺 Transformer,了解了如何在計算機視覺中引入先進的模型結構。今天,我們將探索另一個當前研究的熱點領域:自我監督學習(Self-Supervised Learning)。自我監督學習旨在利用大量未標註的數據,從中學習有效的特徵表示,從而減少對人工標註數據的依賴。在計算機視覺領域,自我監督學習已經取得了顯著的成果,並為多種下游任務提供了有力的支持。
自我監督學習(Self-Supervised Learning) 是一種機器學習方法,通過從數據本身自動生成標籤,構建預測任務,從而在無需人工標註的情況下進行學習。
自我監督學習的關鍵在於設計合適的預測任務,使模型能夠學習有用的特徵。以下是一些常見的方法:
基本原理
對比學習通過讓模型區分相似和不相似的樣本,學習有判別性的特徵表示。
損失函數
InfoNCE 損失: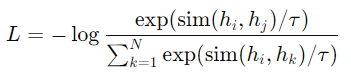
ℎ𝑖,ℎ𝑗:正樣本對的特徵表示
sim(⋅):相似度函數,如餘弦相似度
𝜏:溫度參數
典型方法
SimCLR
MoCo(Momentum Contrast)
今天我們深入學習了自我監督學習與計算機視覺的基本概念和方法。從預測任務的設計,到對比學習的原理,我們了解了如何在無標註數據上學習有效的特徵表示。自我監督學習為解決標註數據匱乏問題提供了一條新路徑,並在計算機視覺領域取得了顯著的成果。未來,隨著理論和方法的不斷完善,自我監督學習將在更多的應用中發揮重要作用。
那我們就明天見了~掰掰~~


 iThome鐵人賽
iThome鐵人賽