本系列文章部分內容由AI生成,最後有經過人工確認及潤稿。
隨著深度學習的發展, 注意力機制(Attention Mechanism) 在自然語言處理(NLP)領域取得了巨大成功,如 Transformer 模型。然而,注意力機制不僅適用於 NLP,也在計算機視覺領域展現了強大的能力。 視覺 Transformer(Vision Transformer, ViT) 作為一種新興的模型架構,將 Transformer 引入到圖像處理中,取得了與卷積神經網絡(CNN)相媲美的效果。今天我們將深入探討注意力機制在計算機視覺中的應用,以及視覺 Transformer 的原理和實踐。
本日學習目標
理解注意力機制的基本概念和原理
學習視覺 Transformer 的結構與訓練方法
掌握注意力機制在計算機視覺中的應用
了解視覺 Transformer 的優勢和挑戰
注意力機制概述
什麼是注意力機制
注意力機制(Attention Mechanism) 最初是在機器翻譯中提出的,旨在讓模型在處理序列數據時,能夠聚焦於與當前輸出相關的輸入部分。
- 核心思想:為每個輸入元素分配一個權重,表示其對當前任務的重要程度。
- 優勢:能夠捕捉長距離依賴關係,緩解 RNN 中的梯度消失問題。
注意力機制的基本原理
- 查詢(Query):當前需要處理的目標。
- 鍵(Key):數據庫中所有可能的匹配項目。
- 值(Value):與鍵相關的數據。
注意力機制通過計算查詢與鍵之間的相似度,獲得權重,然後加權求和值,得到最終的輸出。
- 計算公式:
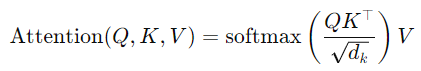
- 𝑄:查詢矩陣
- 𝐾:鍵矩陣
- 𝑉:值矩陣
- 𝑑𝑘:鍵的維度
視覺 Transformer(ViT)
ViT 的提出背景
傳統的 CNN 通過卷積層提取局部特徵,對長距離依賴的捕捉較弱。為了克服這一限制,研究者嘗試將 Transformer 應用於圖像領域,提出了 視覺 Transformer(ViT)。
ViT 的基本結構
- 圖像切片
- 圖像劃分為 Patch:將輸入圖像劃分為固定大小的圖像塊(如 16×16 的小塊)。
- 線性嵌入:將每個圖像塊展平成向量,通過線性變換映射到高維空間。
- 位置編碼
原因:Transformer 缺乏對序列位置的敏感性,需要加入位置編碼以保留位置信息。
方法:為每個圖像塊添加可學習的位置嵌入向量。
- Transformer 編碼器
- 多頭自注意力機制:捕捉圖像塊之間的關聯性。
- 前饋神經網絡:對每個位置的特徵進行非線性變換。
- 層歸一化與殘差連接:穩定訓練過程,防止梯度消失。
- 分類頭
- CLS Token:在輸入序列前添加一個特殊的分類標記,最終輸出作為整體圖像的表示。
- 全連接層:將 CLS Token 的輸出映射到分類結果。
ViT 的訓練策略
- 預訓練:在大規模數據集(如 ImageNet-21k)上進行預訓練。
- 微調:在目標任務的數據集上進行微調,適應特定任務。
注意力機制在計算機視覺中的應用
自注意力機制在 CNN 中的融合
- SENet(Squeeze-and-Excitation Network)
- 提出者:Hu 等人在 2018 年提出。
- 主要思想:通過學習通道間的關係,自適應調節各個通道的權重。
- 結構:
- Squeeze:全局平均池化,獲取全局特徵。
- Excitation:兩個全連接層,學習通道間的相關性。
- 重標定:將權重乘回特徵圖,調節通道特徵。
- CBAM(Convolutional Block Attention Module)
- 提出者:Woo 等人在 2018 年提出。
- 主要思想:同時考慮通道注意力和空間注意力,增強重要特徵。
- 結構:
- 通道注意力模塊:學習通道間的重要性。
- 空間注意力模塊:學習特徵圖中不同位置的重要性。
Transformer 與 CNN 的結合
- Swin Transformer
- 提出者:Liu 等人在 2021 年提出。
- 主要思想:引入層次化的 Transformer 結構,使用滑動窗口進行計算。
- 優勢:兼具 CNN 的局部性和 Transformer 的長距依賴建模能力。
- CNN-Transformer 混合模型
- 方法:將 CNN 用於提取低級特徵,Transformer 用於高級特徵的關係建模。
- 應用:圖像分類、目標檢測、語義分割等任務。
實踐案例
使用 ViT 進行圖像分類
由於課程進度安排,日後會有番外篇來讓各位練習及使用程式碼。
注意力機制的優勢和挑戰
優勢
- 全局關係建模:能夠捕捉特徵之間的長距離依賴關係。
- 靈活性:適用於各種任務,包括分類、檢測、分割等。
- 性能提升:在大型數據集上表現優異,取得了領先的結果。
挑戰
- 計算量大:注意力機制的計算量與輸入的序列長度平方成正比,對高分辨率圖像不友好。
- 數據需求高:需要大量的數據進行預訓練,對小數據集效果有限。
- 模型解釋性:Transformer 的黑盒性使得模型解釋變得困難。
未來發展與應用
模型優化
- 稀疏注意力:引入稀疏機制,降低計算複雜度。
- 混合架構:結合 CNN 和 Transformer 的優點,構建更高效的模型。
應用拓展
- 目標檢測:如 DETR(Detection Transformer)將 Transformer 應用於目標檢測。
- 語義分割:利用注意力機制提高分割的精度。
- 跨模態學習:結合文本、音頻等多模態數據,進行更全面的理解。
本日總結
今天我們深入學習了注意力機制與視覺 Transformer在計算機視覺中的應用。從注意力機制的基本原理,到 ViT 的結構和訓練方法,我們了解了 Transformer 如何在視覺領域展現強大的能力。雖然面臨計算量和數據需求的挑戰,但隨著技術的不斷進步,注意力機制和視覺 Transformer 將在更多的應用中發揮重要作用。


 iThome鐵人賽
iThome鐵人賽