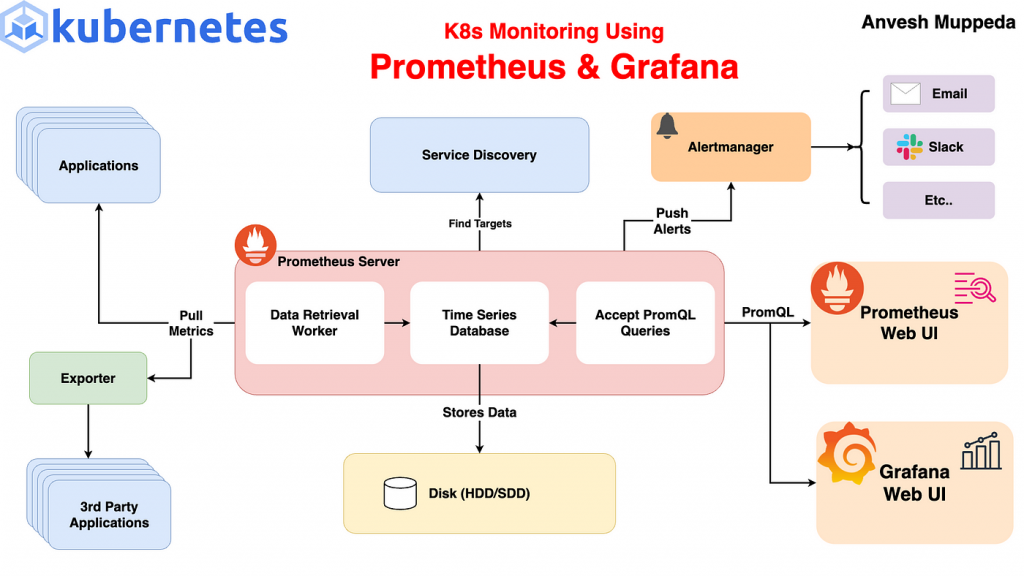
在今天的文章中,我們將學習如何在 Kubernetes 叢集中使用 Prometheus 進行基礎的監控。Prometheus 是一個強大的開源監控工具,能夠自動從系統中收集指標數據,並提供告警功能,幫助我們及時發現系統中的問題。這些監控工具對 DevOps 團隊的日常運作非常重要,因為它能即時提供系統運行狀態的反饋,讓團隊能夠快速應對問題。
Prometheus 是一個開源的監控系統和時間序列數據庫,它專為收集和查詢應用的監控指標而設計。它的主要特點包括:
Prometheus 在 Kubernetes 環境中特別受歡迎,因為它能夠輕鬆地與容器化應用整合,並且自動發現 Kubernetes 叢集中的服務和 Pod。在深入實踐之前,我們先了解 Prometheus 的一些核心概念:
對 DevOps 團隊來說,監控系統是保障應用穩定運行和及時響應問題的關鍵。以下是監控如何影響 DevOps 團隊的幾個方面:
監控不僅在應用上線後起到關鍵作用,還在 CI/CD 流程中發揮了不可或缺的作用:
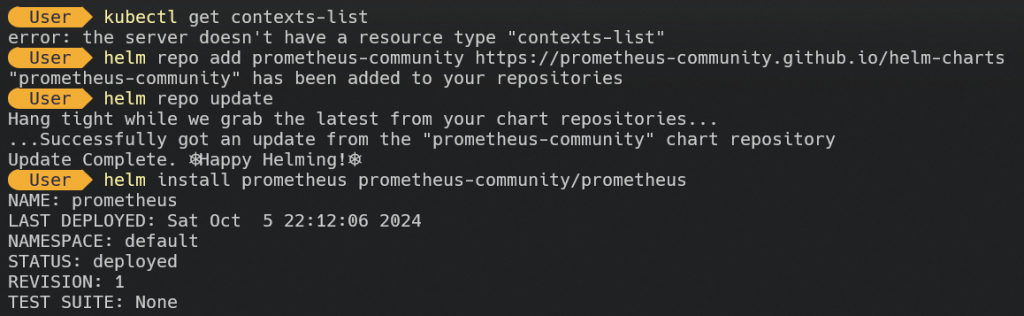
在 Kubernetes 中,我們可以通過 Helm 來快速佈署 Prometheus。
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
更新一下
helm repo update
接下來,使用 Helm 佈署 Prometheus
helm install prometheus prometheus-community/prometheus
這會在 Kubernetes 中啟動 Prometheus 叢集,並且開始自動監控 Kubernetes 內的指標。
使用以下命令檢查 Prometheus 是否成功佈署:
kubectl get pods -l app=prometheus
# 或
kubectl get pods --namespace default -l "app.kubernetes.io/name=prometheus,app.kubernetes.io/instance=prometheus" -o jsonpath="{.items[0].metadata.name}"
這會列出所有 Prometheus 相關的 Pod。當所有 Pod 都處於 Running 狀態時,表示 Prometheus 已經正常運行。
佈署完成後,我們可以通過 Prometheus 的 Web 介面來查詢 Kubernetes 叢集中的指標數據。首先,我們需要訪問 Prometheus 的 Web 介面。
kubectl get pods --namespace default -l "[app.kubernetes.io/name=prometheus,app.kubernetes.io/instance=prometheus](http://app.kubernetes.io/name=prometheus,app.kubernetes.io/instance=prometheus)" -o jsonpath="{.items[0].metadata.name}"[adata.name](http://adata.name/)}"
這裡會得到自己正在執行的Prometheus pod 名稱,例如 prometheus-server-xxx
將 Prometheus 的 Web UI 開放給外部訪問
kubectl --namespace default port-forward <prometheus-server-xxx> 9090

這樣,我們可以在本機的 http://localhost:9090 或 http://127.0.0.1:9090 上訪問 Prometheus 的 Web 介面。
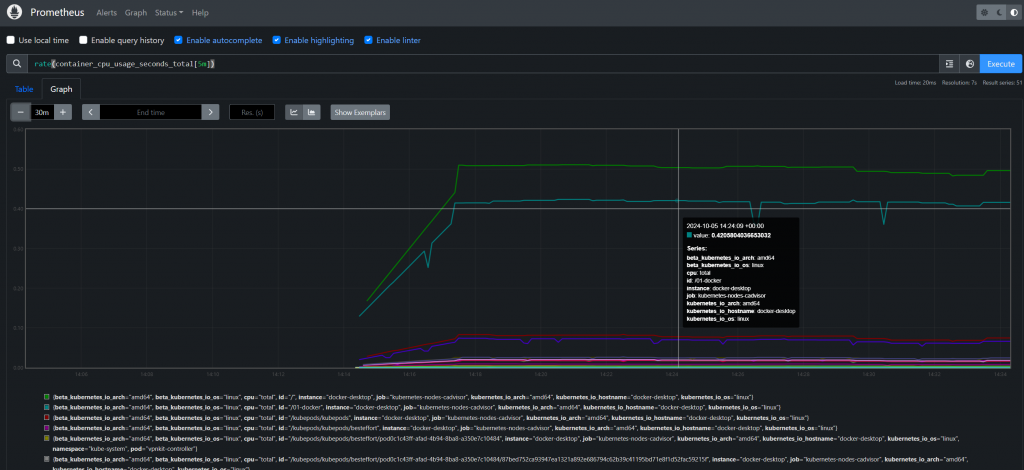
在 Prometheus Web 介面的 "Graph" 頁面,我們可以使用 PromQL 來查詢系統指標。例如:
rate(container_cpu_usage_seconds_total[5m])
container_memory_usage_bytes
這些指標能夠幫助我們了解 Kubernetes 叢集中應用和節點的運行情況。
這個命令會啟動一個不斷消耗 CPU 資源的 Pod,來模擬高 CPU 使用
kubectl run cpu-stress --image=busybox --restart=Never -- /bin/sh -c "while true; do :; done"
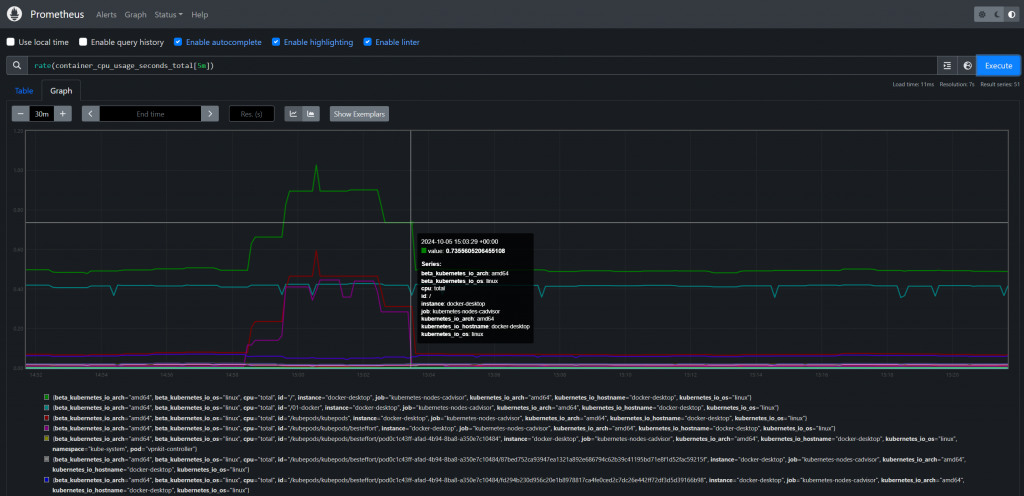
要停止這個模擬測試,可以刪除高 CPU 使用的 Pod
kubectl delete pod cpu-stress
今天我們學習了如何在 Kubernetes 中使用 Prometheus 來進行基礎的監控,並且了解了 Prometheus 的主要功能和配置方法。透過 Prometheus,我們可以即時掌握系統運行情況,從而更快速地響應問題,並且為未來的應用優化提供依據。
明天,我們將介紹如何使用 Grafana 來可視化 Prometheus 中收集到的數據,幫助我們更直觀地理解和分析系統指標。敬請期待!


 iThome鐵人賽
iThome鐵人賽