今天稍微喘口氣回頭看一下 Rust 除了內建的陣列和元組以外的集合型別。
集合(collections)的特色在於可以包含數個數值組成,相對於內建的陣列和元組的資料存在 Stack,標準函數庫(std)提供的集合的資料是存在 Heap,這代表這些資料的數量不會被限制在編譯期必須確定,而是根據程式執行動態調整,使用上會彈性許多,而向量就是其中之一。
向量(Vector)可以在一個資料結構儲存不只一個數值,而且該結構的記憶體會接連排列所有數值,換句話說,它的記憶體是連續的,其實就很像 JavaScript 的 Array 了。
先來看如何建立一個向量:
let v: Vec<i32> = Vec::new();
一種方式是呼叫 Vec 的 new 關聯函數,這樣會建立一個空的向量,不過因爲編譯器判斷不出這個容器內要放什麼型別,需要透過<T>來指定向量元素型別。 Vec<i32> 代表我們要放的是 i32 整數型別。
要新增元素到這個向量的話就用 push 方法,一樣要記得用 mut 標註它是可變的。
fn main() {
let mut v = Vec::new();
v.push(1);
v.push(2);
v.push(3);
v.push(4);
println!("{:?}", v); // [1, 2, 3, 4]
}
上面的例子我們不用再指定是什麼型別,編譯器可以從後續的動作判斷。
需要注意向量的元素的型別全部都要是一樣的,如果不同的話編譯器會報錯,
另一種方式是 Rust 提供了 vec! 巨集,可以更方便的建立向量並直接設置初始的值進去。
let v1 = vec![1, 2, 3, 4];
let v2 = vec![1; 4];
在編譯期間當編譯器遇到 vec! 巨集時,會根據其中的元素和語法,生成對應的 Vec 建構函式呼叫。所以 v1 就和我們第一個例子結果是一樣的,而 v2 是快速建一個有指定數量元素向量的方式,就像陣列的重複表達式(Repeat Expression)寫法一樣。
Rust 提供兩種讀取向量元素的方式,回傳的結果和讀取向量範圍外的元素時的行為是不同的。
直接用索引值:
fn main() {
let v = vec![1, 2, 3, 4];
println!("{}", &v[2]); // 3
}
如果讀取範圍外的元素程式會恐慌(panic)並崩潰。
另外需要特別注意有沒有 & 底層的動作不同,像上面有加 & 代表這是一個參考,不會複製一份實際的數值,沒有加 & 的話代表的是副本,會複製一份資料,有額外開銷。
fn main() {
let v = vec![1, 2, 3, 4];
let point = &v[2];
let mut point2 = v[2]; // 複製值
point2 = 42;
println!("{:?}", point ); // 3, 向量上的值沒變
println!("{:?}", point2 ); // 42
}
可以看到複製資料的 point2 的值改變不會影響到原本在向量上的值。
還有另外一點想補充的,也是自己還不夠熟所有權系統的地方。
如果反過來,改向量上的數值,副本數值不變,這樣其實會編譯失敗的。
fn main() {
let mut v = vec![1, 2, 3, 4];
let point = &mut v[2];
let point2 = v[2];
*point = 42;
println!("{:?}", point );
println!("{:?}", point2 );
}
error[E0502]: cannot borrow `v` as immutable because it is also borrowed as mutable
--> src/main.rs:9:18
|
8 | let point = &mut v[2];
| - mutable borrow occurs here
9 | let point2 = v[2];
| ^ immutable borrow occurs here
10 | *point = 42;
| ----------- mutable borrow later used here
會報這個錯的原因在於雖然 let point2 = v[2]; 是複製一份資料沒錯,但因為它也需要先用索引取得數值再複製,因此也屬於不可變參考,進而造成我們同時有不可變與可變參考的情況,編譯器會報錯。
用 get 方法:
fn main() {
let v = vec![1, 2, 3, 4];
let third: Option<&i32> = v.get(2);
match third {
Some(third) => println!("第三個元素是 {third}"),
None => println!("第三個元素並不存在。"),
}
}
get 的話會回傳列舉,需要注意 Option 的模式 Option<&T> 也和前一例一樣,不想要複製副本的話要在泛型部分加入& ,代表取用的是參考型別,不然會複製一份。
列舉會強迫做對應的處理,如果希望行為是程式不要崩潰的話就可以用這個方法。
另外一個比較特別的行為是如果我們在有向量元素參考的時候,再去新增元素到這個向量,編譯器會報錯:
fn main() {
let mut v = vec![1, 2, 3, 4];
let first = &v[0];
v.push(5);
println!("{}", first);
}
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:24:5
|
23 | let first = &v[0];
| - immutable borrow occurs here
24 | v.push(5);
| ^^^^^^^^^ mutable borrow occurs here
25 | println!("{}", first);
| ----- immutable borrow later used here
因為對 Rust 來說向量新增元素也是一種可變借用。
這樣設計的理由在於,向量新增元素要放在前一個記憶體後面,如果空間不夠的話會找到另外一段足夠空間的記憶體把資料搬過去,向量內部的指針會指向新的記憶體,並釋放舊的記憶體空間,這個過程稱為重新分配(reallocation)。這種情況如果有參考指向舊的位址就會造成記憶體安全的風險,Rust 選擇迴避這種風險。
前面提到搬動資料的行為,和向量的容量有關,這是因為向量的長度可變動,為了效能考量的設計。
向量的容量(capacity)包含預留的空間,代表在不需要重新分配記憶體的情況下,向量可以容納的元素數量。
向量的長度(length)是目前實際包含的元素數量。
如下圖: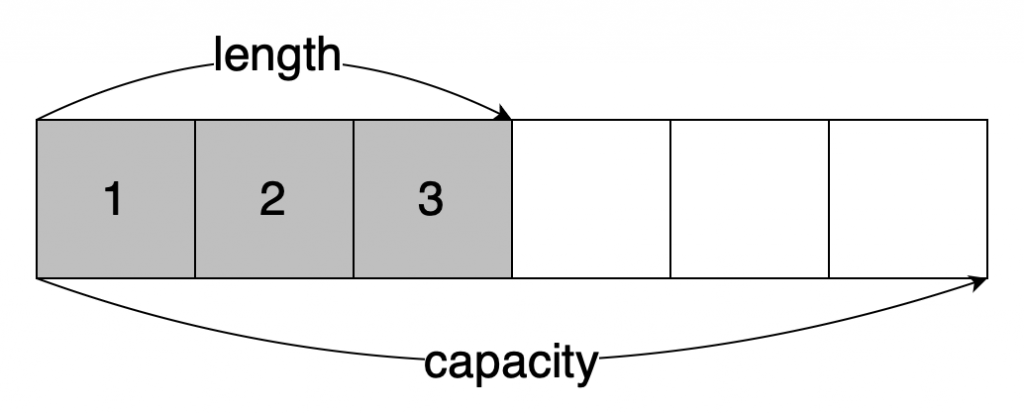
如前面說的,當我們向向量新增元素時,如果容量已經滿了,會觸發重新分配,影響效能。
如果要優化效能,我們可以使用with_capacity關聯函數來建立一個具有指定預設容量的向量:
fn main() {
let mut v = Vec::with_capacity(4);
for i in 1..6 {
v.push(i);
println!("vector: {:?}", v);
println!("length: {}", v.len());
println!("capacity: {}", v.capacity());
}
}
len 和 capacity 方法分別能確認向量的長度和容量。
結果如下:
vector: [1]
length: 1
capacity: 4
vector: [1, 2]
length: 2
capacity: 4
vector: [1, 2, 3]
length: 3
capacity: 4
vector: [1, 2, 3, 4]
length: 4
capacity: 4
vector: [1, 2, 3, 4, 5] // 加入的元素超過容量
length: 5
capacity: 8 // 重新分配容量變成 2 倍
如果向量的容量用完,會自動增加,通常會把容量翻倍,這樣小幅度的長度變更就不會導致頻繁的重新分配,影響效能。
所以在預先就知道這個向量會有多少元素的時候,可以透過指定容量的方式改進效能,
當然就算之後長度超過預設值,它的容量還是會自動增加,不用擔心。
如果需要遍歷向量上的元素可以用 for 迴圈的方式,一樣是用 & 取得參考:
fn main() {
let v = vec![1, 2, 3, 4];
for i in &v {
println!("{i}");
}
}
也可以用遍歷改變元素的值:
* 叫做解參考運算子,因為 for 迴圈拿到的 i 是參考,要做運算需要解參考取得對應的值。
fn main() {
let mut v = vec![1, 2, 3, 4];
for i in &mut v {
*i += 50;
}
println!("{:?}", v); // [51, 52, 53, 54]
}
但是用 for 不能改變向量的長度:pop是移除並回傳向量中的最後一個元素的方法。
fn main() {
let mut v = vec![1, 2, 3, 4];
for i in &mut v {
*i += 1;
if *i < 4 {
v.pop();
}
}
println!("{:?}", v);
}
error[E0499]: cannot borrow `v` as mutable more than once at a time
--> src/main.rs:26:13
|
23 | for i in &mut v {
| ------
| |
| first mutable borrow occurs here
| first borrow later used here
...
26 | v.pop();
| ^ second mutable borrow occurs here
用while就可以在迴圈中改變向量長度:
fn main() {
let mut v = vec![1, 2, 3, 4];
let mut i = 0;
while i < v.len() {
v[i] += 1;
if v[i] < 5 {
v.pop();
} else {
i += 1;
}
}
println!("{:?}", v);
}
不過就如上面提到,改變長度會增加取得空指標的風險,需要謹慎評估。
這也是為什麼介紹迴圈的時候會說官方建議使用 for 的寫法。
前面提到一個向量內的型別必須是同一種,不過我們可以用列舉的方式來定義:
fn main() {
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("藍色")),
SpreadsheetCell::Float(10.12),
];
}
這樣實際上我們還是可以利用變體存不同的數值型別,因為對向量來說他們都是同一種列舉型別。
Rust 如果允許向量持有不同型別,在對向量中元素做處理的時候可能就會有型別錯誤,用列舉就會強迫處理每一種可能的型別。
Rust 需要在編譯時期知道向量中元素的型別,結合 Rust 的記憶佈局規則,來計算出向量所需的最少記憶體。這個計算過程會考慮到元素的對齊、結構體和列舉的內部佈局等因素,以確保高效的記憶體利用。
反過來說,如果沒辦法一開始就完整定義列舉會有哪些型別的話就必須用特徵來處理。
以下範例是設計角色特徵,遊戲的玩家和怪物都會實作 Character 特徵。
trait Character {
fn name(&self) -> &str;
fn health(&self) -> u32;
fn attack(&self) -> u32;
fn defend(&self) -> u32;
}
struct Player {
name: String,
health: u32,
attack: u32,
defense: u32,
class: String,
}
impl Character for Player {
fn name(&self) -> &str {
&self.name
}
fn health(&self) -> u32 {
self.health
}
fn attack(&self) -> u32 {
self.attack
}
fn defend(&self) -> u32 {
self.defense
}
}
struct Monster {
name: String,
health: u32,
attack: u32,
defense: u32,
boss: bool,
}
impl Character for Monster {
fn name(&self) -> &str {
&self.name
}
fn health(&self) -> u32 {
self.health
}
fn attack(&self) -> u32 {
self.attack
}
fn defend(&self) -> u32 {
self.defense
}
}
fn main() {
let mut characters: Vec<Box<dyn Character>> = Vec::new();
let player = Box::new(Player {
name: "玩家".to_string(),
health: 100,
attack: 20,
defense: 15,
class: "勇者".to_string(),
});
let monster = Box::new(Monster {
name: "史萊姆".to_string(),
health: 50,
attack: 10,
defense: 5,
boss: false,
});
characters.push(player);
characters.push(monster);
// 遍歷所有角色
for character in &characters {
println!("{} 的生命值為 {}", character.name(), character.health());
}
}
向量需要在編譯期就知道元素型別大小,這個限制沒有改變。
但是有同一種特徵的型別大小我們沒辦法確定,解決的方式是把特徵多用一層 Box 包裝起來, Box 是個指標,指標的大小不會隨著指向的資料大小改變,這樣向量能知道它的元素大小了。
向量和其他集合一樣,在離開作用域時會發生以下情況:
struct MyStruct<'a> {
data: String,
point: &'a str,
}
fn main() {
let s = String::from("hello");
{
let mut v = Vec::new();
v.push(MyStruct {
data: String::from("world"),
point: &s, // 儲存的是引用
});
} // v 離開作用域記憶體被釋放
println!("{s}"); // s 不會被 v 影響
}
決定指向的資料能不能被釋放,除了生命週期、所有權外,還有一個機制引用計數:如果 point 所指向的字串被多個 MyStruct 實例共享,那麼可以使用 Rc 或 Arc 智慧指標來實現引用計數,確保該字串在所有引用都消失後才會被釋放。
向量是 Rust 中一個極其重要且常用的數據類型,其最關鍵的特點在於可以動態變動長度。儘管長度可變,量仍然保持記憶體連續性,這確保了高效的讀取操作。這種靈活性和效率的結合使得向量在實務中有廣泛的應用,例如作為緩衝區、進行批量操作等。
理想情況下,如果資料都能存在 Stack、能在編譯的時候就知道各種型別、大小會是最有效率的。可惜實務上就是會有動態變動、要等到執行的時候才知道的資料,Rust 面臨的挑戰在於:如何在保持靜態分析和編譯時檢查的優勢下,有效管理這些動態資料。
本篇提到的 Box、 Rc 和 Arc都屬於智慧指標,正是 Rust 面對編譯期沒辦法完全處理情況的關鍵。
這些工具提供了我們安全、高效地管理記憶體的方式,使得 Rust 能夠在靜態類型系統的安全性和動態資料結構的靈活性之間取得平衡。因此,我們下一篇將開始介紹智慧指標。


 iThome鐵人賽
iThome鐵人賽