相信大家一定都有自己口袋中常用的分析工具,今天也來整理一下我從過去到現在接觸過的一些分析工具,算是我自己的工具箱。
但我會比較從『目的』的角度來做整理,這也是提醒我自己剛開始學分析時,常常為了用而用,
|『當你手上有一把錘子,看什麼都像是個釘子』。

我們可以把分析目的先做四個大分類:『Descriptive(敘述型)』、『Diagnostic(診斷型)』、『Predictive(預測型)』、『Prescriptive(推薦型)』
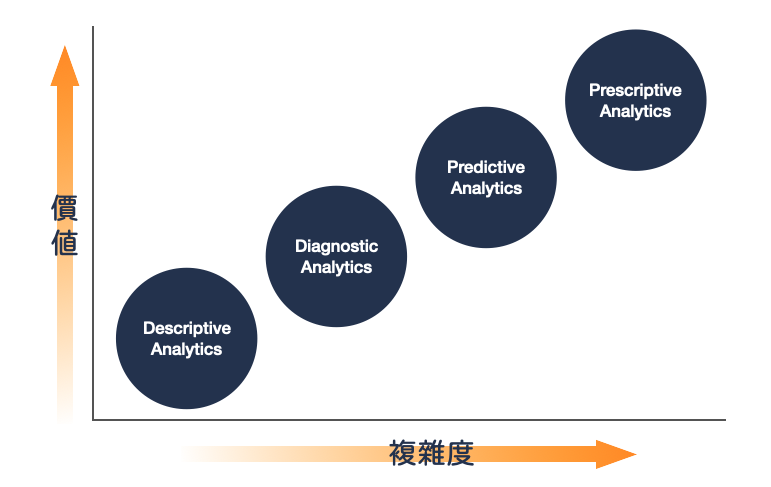
描述過去的數據和事件,總結出趨勢、模式和關鍵指標。敘述型分析回答了「發生了什麼?」的問題,常用於商業和回顧性分析。
最常使用的工具是:
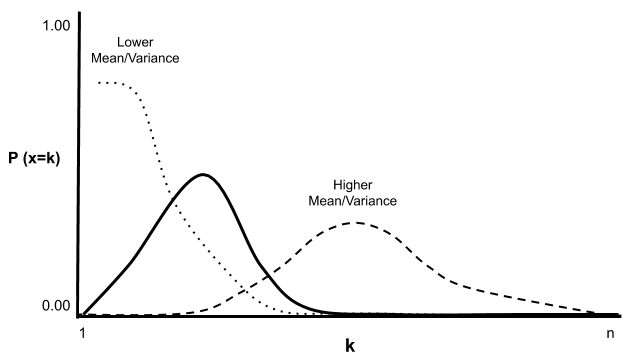
圖片來源 :https://www.ml-science.com/poisson-distribution
用來識別和分析資料中的原因和相關性,回答「為什麼會發生?」的問題。它幫助找到問題的根源,通常與探索性數據分析相關。
另一個我常用的方式是 『購物籃分析』,核心概念是透過 items 一起出現的頻率,找出相關性高的項目,鼎鼎大名的啤酒與尿布,就是透過這個演算法來做的。
基於歷史數據和模型進行預測,回答「未來會發生什麼?」的問題,常用於預測趨勢、需求和行為,例如 time series analysis 或 linear regression。
機器學習:基於資料訓練模型來進行預測,而不需明確的規則或假設。常見的機器學習算法包括隨機森林、決策樹、支持向量機(SVM)等。這些算法適合於結構複雜的數據,且能在大量特徵下進行準確的預測。
深度學習:深度學習模型是多層神經網絡的一種形式,尤其適用於大規模資料集和高維度的複雜問題,如影像、語音和自然語言處理。它擅長自動從數據中學習到關鍵特徵來進行預測。
Ensemble方法:運作概念是『委員會投票多數決』,Ensemble學習通過結合多個模型的預測來提升準確性。常見的方法包括Bagging(如隨機森林)、Boosting(如XGBoost)等。這些技術利用多個弱學習器來建構強大的預測模型,從而提升整體的效能。
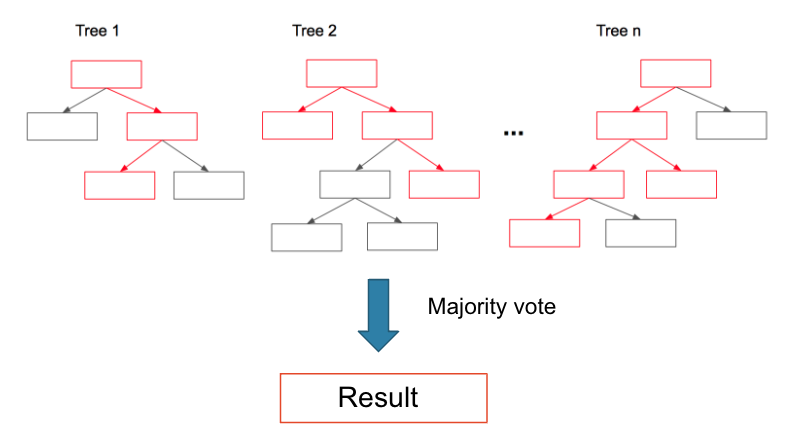
圖片:隨機森林模型
白箱模型:這類模型如線性回歸、決策樹,具有高度可解釋性,用戶能夠清楚了解每個變數對結果的影響,模型內部的運行邏輯透明,適合需要高解釋性的應用場合。
黑箱模型:像深度學習和某些Ensemble方法,它們雖然具備強大的預測能力,但內部運行機制較為複雜且難以解釋,因此被稱為黑箱模型。在某些應用中,解釋能力的缺乏可能會限制其使用。
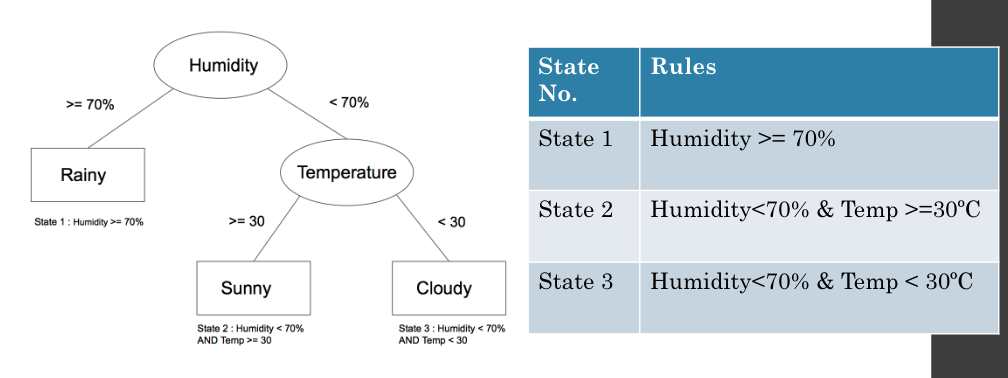
圖片:決策樹
時間序列分析(Time Series Analysis):這種方法專注於處理時間維度的資料。它通過分析歷史數據的時間序列模式(如季節性、趨勢、週期)來預測未來數值,常用於銷售預測、需求預測等領域。ARIMA和SARIMA是常見的時間序列模型。
馬可夫模型(Markov Model):這是一種隨機過程模型,適合用來描述時間序列中當前狀態只與前一個狀態相關的系統。它被廣泛應用於金融、機器翻譯等領域來進行狀態轉移預測。
推薦型分析提供最佳的行動建議,用來回答「接下來應該做什麼?」的問題。它根據數據預測結果,結合規則或模型,推薦最佳決策或行動方案。
最常見的也相對簡單是透過分類、回歸模型,不管是用 linear regression, SVM, decision trees, random forest,或是較複雜一些的深度學習 transformer, sequence models 等等,例如:
我可以透過決策樹來學習通常什麼樣的病患生理特徵,會被送進加護病房,什麼樣的狀態可以送到普通病房,透過訓練資料訓練模型以後,就可以用來預測之後新的病人狀況。
推薦系統是一種典型的推薦型分析應用,根據使用者的行為數據(如瀏覽紀錄、購物歷史等)或偏好來提供個性化的產品或內容建議。這種系統常見於電商平台、串流媒體服務(如Netflix、Spotify)等,幫助提升用戶體驗並增加互動與銷售。
協同過濾(Collaborative Filtering) 與 內容過濾(Content-based Filtering): 是推薦系統的兩大核心技術,能根據相似用戶的行為或個別用戶的偏好來提供建議。
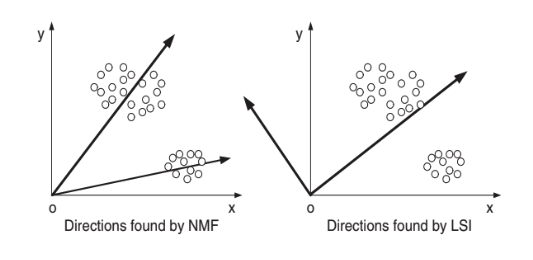
矩陣分解(Matrix Factorization): 矩陣分解是一種推薦系統中常用的技術,特別適合解決大規模數據中的推薦問題。它的核心是將使用者與物品的互動數據矩陣(如使用者評分矩陣)分解為多個低維矩陣,從而識別出潛在的因子(如用戶偏好、物品特徵),用來進行推薦。SVD常用於處理稀疏數據,而NMF則因其非負特性而更具解釋性,適合多種推薦場景
今天從『目的』出發來整理我過去用過的分析工具和方法,從回顧過去到預測未來,涵蓋了數據分析的完整過程。敘述型分析用於了解現狀,診斷型分析解釋原因,預測型分析預測未來趨勢,而推薦型分析則通過建議行動方案,讓分析能夠產生具體行動。它們共同構成了數據驅動決策的強大基礎,能夠幫助組織在各個工作流程上提升效率。

