
昨天介紹了如何在 GKE 中使用 GPU 節點部署 Mixtral-8x7B-Instruct-v0.1 模型。然而讀者有沒有發現問題,部署過程中使用需要較小記憶體的 Model(mistralai/Mistral-Nemo-Instruct-2407) 會遇到資源浪費。
以 H100 GPU 為例,單卡就擁有 80GB 的記憶體,即使模型只需要一小部分資源,也佔用了一整張卡,造成效能閒置及成本增加。
本章將探討如何解決這個問題,提升 GPU 使用率,並有效降低成本。
為了提高 GPU 利用率,Multi-Instance GPU 可讓您將單個受支持的 GPU 進行分區,最多可分為七個切片。每個切片可以獨立分配給節點上的一個容器,每個 GPU 最多支持 7 個容器。Multi-Instance GPU 在工作負載之間提供硬件隔離,並為 GPU 上運行的所有容器提供一致且可預測的 QoS。
對於 CUDA 應用,每個 GPU 分區都顯示為常規 GPU 資源。這提供了硬體級的隔離,確保每個實例的效能不受其他實例的影響,提供 QoS (服務品質) 保證。
如需詳細了解 Multi-Instance GPU,請參閱 NVIDIA Multi-Instance GPU 用戶指南。
但是目前支持的 Multi-Instance GPU 只有三種,NVIDIA A100 (40GB),NVIDIA A100 (80GB),NVIDIA H100 (80GB)
A100 GPU 和 H100 GPU 由 7 個計算單元和 8 個記憶體單元組成,可以劃分為不同大小的 GPU 實例。
GPU 分區大小使用以下語法:[compute]g.[memory]gb。例如,1g.5gb 的 GPU 分區大小是指具有一個計算單元(GPU 上流式多處理器的 1/7)和一個記憶體單元 (5GB) 的 GPU 實例。可以在部署 Autopilot 工作負載或創建標準集群時指定 GPU 的分區大小。
下表列出了 GKE 支持的分區大小:
| 分區大小 | GPU 實例 |
|---|---|
GPU:NVIDIA A100 (40GB) (nvidia-tesla-a100) |
|
1g.5gb |
7 |
2g.10gb |
3 |
3g.20gb |
2 |
7g.40gb |
1 |
GPU:NVIDIA A100 (80GB) nvidia-a100-80gb |
|
1g.10gb |
7 |
2g.20gb |
3 |
3g.40gb |
2 |
7g.80gb |
1 |
GPU:NVIDIA H100 (80GB) (nvidia-h100-80gb) |
|
1g.10gb |
7 |
1g.20gb |
4 |
2g.20gb |
3 |
3g.40gb |
2 |
7g.80gb |
1 |
3g.40gb) 的 GPU MIG Node Pool為了部署實驗環境所需的機器,可以參考 Day3 的 Terraform 範例,使用 Day3 範例創建的Cluster。
node-pool-variables.tf
### node-pool-variables.tf
module "gke" {
node_pools = [
var.h100-partition-3g.config,
]
node_pools_labels = {
"${var.h100-partition-3g.config.name}" = var.h100-partition-3g.kubernetes_label
}
node_pools_taints = {
"${var.h100-partition-3g.config.name}" = var.h100-partition-3g.taints
}
node_pools_resource_labels = {
"${var.h100-partition-3g.config.name}" = var.h100-partition-3g.node_pools_resource_labels
}
}
### Node pool
variable "h100-partition-3g" {
default = {
config = {
name = "h100-partition-3g"
machine_type = "a3-highgpu-8g"
accelerator_type = "nvidia-h100-80gb"
accelerator_count = "8"
# H100 avaliable values 1g.10gb, 1g.20gb, 2g.20gb, 3g.40gb, 7g.80gb
gpu_partition_size = "3g.40gb"
gpu_driver_version = "LATEST"
node_locations = "us-central1-c"
max_pods_per_node = 64
autoscaling = false
node_count = 1
local_ssd_count = 0
disk_size_gb = 2000
local_ssd_ephemeral_storage_count = 16
spot = true
disk_type = "pd-ssd"
image_type = "COS_CONTAINERD"
enable_gcfs = false
enable_gvnic = false
logging_variant = "DEFAULT"
auto_repair = true
auto_upgrade = true
preemptible = false
}
kubernetes_label = {
role = "h100-standard"
}
taints = [
key = "nvidia/share"
value = "nvidia-mig"
effect = "NO_SCHEDULE"
]
}
}
使用以下指令查看 Node 的標籤,可以看到會自動被打上 cloud.google.com/gke-gpu-partition-size: 3g.40gb 的標籤,可以使用此標籤來作為 Pod 的 nodeAffinity。
$ kubectl get nodes $h100_partition_3g_Node_Name --show-labels
# ...以上省略...
cloud.google.com/gke-gpu-partition-size: 3g.40gb
使用上篇文章部署的 mistralai/Mistral-Nemo-Instruct-2407 來示範,這個模型大約 24.5 GB,所以我們切分為 3g.40gb,40 GB 的記憶體夠 Mistral-Nemo 這個模型使用。預計一台 a3-highgpu-8g 總共可以部署 16 個 Pods,replicas 定為 16。
Deployment.yaml
# llm-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: llm-deployment
namespace: ai
spec:
replicas: 16
selector:
matchLabels:
app: llm
template:
metadata:
labels:
app: llm
spec:
terminationGracePeriodSeconds: 60
volumes:
- name: dshm
emptyDir:
sizeLimit: "10Gi"
medium: "Memory"
containers:
- name: llm-chat
image: vllm/vllm-openai:v0.6.2
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /dev/shm
name: dshm
env:
- name: HUGGING_FACE_HUB_TOKEN
# 改成自己的 HUGGING_FACE_HUB_TOKEN
value: "$HUGGING_FACE_HUB_TOKEN"
# 隨便產生一組 VLLM_API_KEY,待會 Call 這隻服務會使用到
- name: VLLM_API_KEY
value: "$VLLM_API_KEY"
args:
- --host=0.0.0.0
- --port=8000
- --model=mistralai/Mistral-Nemo-Instruct-2407
- --tensor-parallel-size=1
- --swap-space=16
- --dtype=bfloat16
- --gpu-memory-utilization=0.9
- --max-model-len=8192
- --max-num-seqs=256
ports:
- name: http
containerPort: 8000
readinessProbe:
httpGet:
path: /health
port: http
periodSeconds: 20
livenessProbe:
httpGet:
path: /health
port: http
periodSeconds: 20
startupProbe:
httpGet:
path: /health
port: http
initialDelaySeconds: 300 # LLM 啟動較久,這裡設定為 300 秒
periodSeconds: 30 # 最多可以等到 1 小時(30 * 120 = 3600s)
failureThreshold: 120
resources:
requests:
cpu: "10"
memory: 30Gi
nvidia.com/gpu: "1"
limits:
cpu: "24"
memory: 100Gi
nvidia.com/gpu: "1"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.google.com/gke-gpu-partition-size
operator: In
values:
- 3g.40gb
tolerations:
- key: "nvidia.com/gpu"
operator: Equal
value: "present"
effect: NoSchedule
- key: "nvidia/share"
operator: Equal
value: "nvidia-mig"
effect: NoSchedule
以上 Yaml 有以下幾點需要注意:
containers.args.tensor-parallel-size=1 :雖然我們有使用 MIG ,但是每個 GPU 分區都顯示為常規 GPU 資源,所以當作單張卡設定為 1。resources.requests.nvidia.com/gpu=1:同上原因,雖然我們有使用 MIG ,但是每個 GPU 分區都顯示為常規 GPU 資源,所以當作單張卡設定為 1。tolerations記得要加入我們在 Node Pool 打上的 Taints 以及 GKE GPU Node 預設的 Taints。將 Deployment 部署上去後,等待大約 1 小時,可以看到 16 個 LLM 的 Pod 都 Ready 了。
$ kubectl get pods -n ai
NAME READY STATUS RESTARTS AGE
llm-deployment-b6bcdb6c4-2pcvw 1/1 Running 0 1h10m
llm-deployment-b6bcdb6c4-8h68d 1/1 Running 0 55m
llm-deployment-b6bcdb6c4-c8rph 1/1 Running 0 1h10m
llm-deployment-b6bcdb6c4-ctj8n 1/1 Running 0 1h10m
llm-deployment-b6bcdb6c4-cxrv9 1/1 Running 0 54m
llm-deployment-b6bcdb6c4-fmnwc 1/1 Running 0 54m
llm-deployment-b6bcdb6c4-g4g4w 1/1 Running 0 54m
llm-deployment-b6bcdb6c4-hxvrl 1/1 Running 0 1h10m
llm-deployment-b6bcdb6c4-jt64k 1/1 Running 0 54m
llm-deployment-b6bcdb6c4-kwqf6 1/1 Running 0 54m
llm-deployment-b6bcdb6c4-m94tt 1/1 Running 0 1h10m
llm-deployment-b6bcdb6c4-mmbhk 1/1 Running 0 1h10m
llm-deployment-b6bcdb6c4-tjgps 1/1 Running 0 1h10m
llm-deployment-b6bcdb6c4-vpd96 1/1 Running 0 1h10m
llm-deployment-b6bcdb6c4-wprqk 1/1 Running 0 54m
llm-deployment-b6bcdb6c4-znvvr 1/1 Running 0 54m
可以任意進入其中一個 Pod ,輸入指令 nvidia-smi 來查看當前 Pod 所使用的 GPU 的狀態。
# 輸入指令進入 Pod
$ exec kubectl exec -i -t -n ai $Pod_Name -c llm-chat -- sh -c "clear; (bash || ash || sh)"
# 進入 Pod 以後使用 nvidia-smi 查看當前 Pod 所在的 GPU 狀態,以 watch 每一秒刷新一次
root@$Pod_Name:/vllm-workspace$ watch -n 1 nvidia-smi
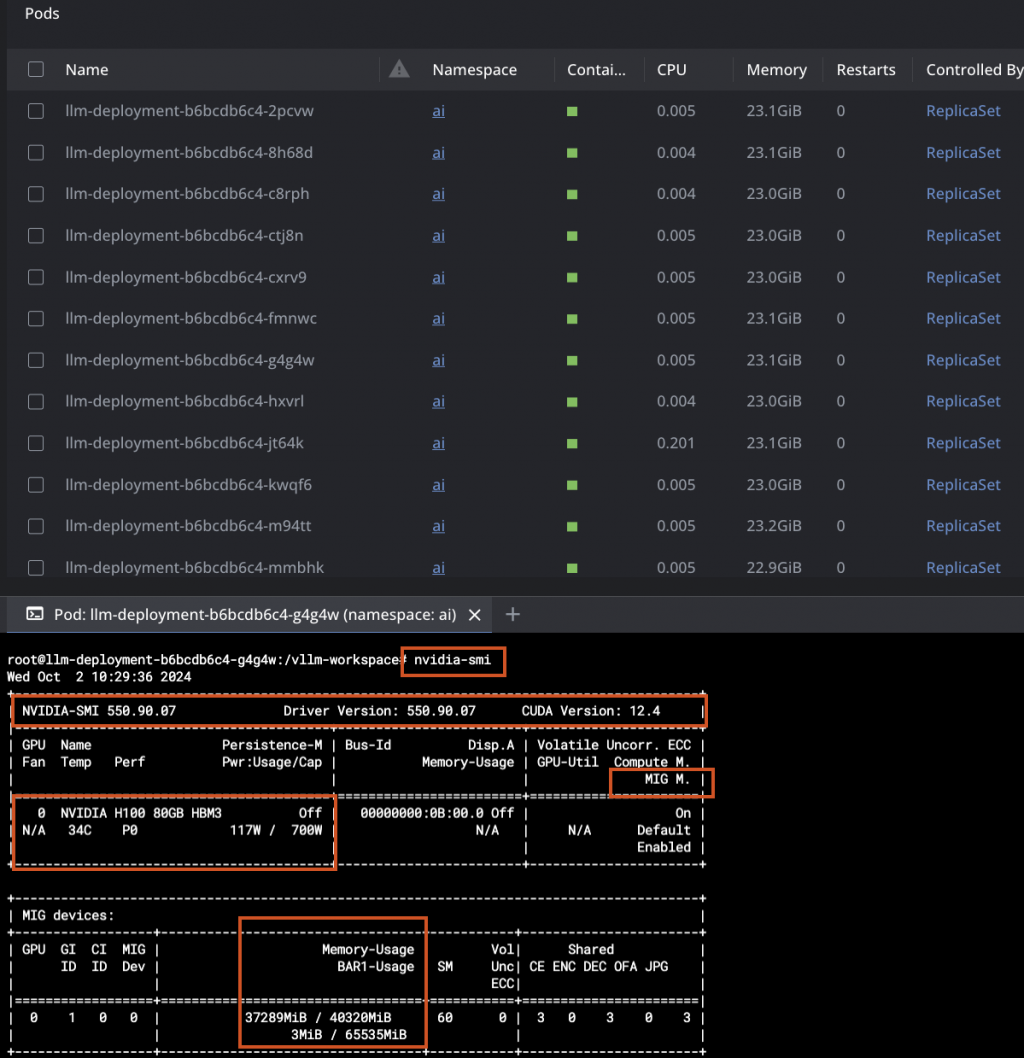
從輸出的格式中可以看到,使用了 NVIDIA H100 80GB GPU 正在運行,驅動版本為 550.90.07,CUDA 版本為 12.4。
進入 GKE 的觀測能力頁面,調整到 DCGM,可以發現將顯示卡切半(3g.40g) 以後,可以使用到所有的 GPU 中的記憶體,使用率達到 91%,有效提升 GPU 使用率。
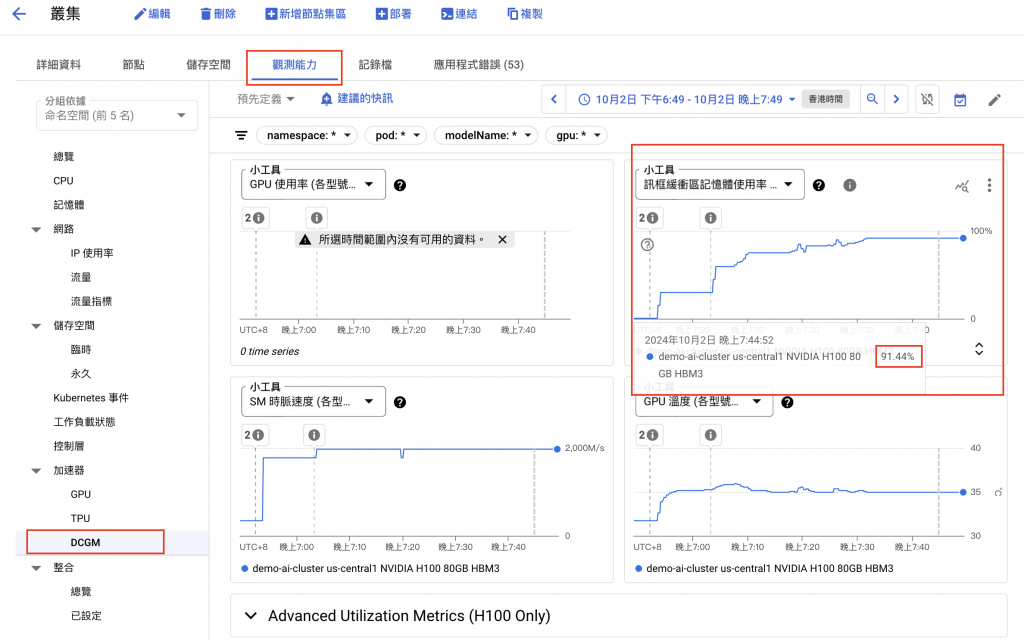
接下來使用上一篇文章的 K6 壓測工具,會發現因為顯示卡切半,Pod 的數量變成兩倍,所以 Prompt Token Output 也會變成兩倍,提升 GPU 使用率的同時,也有效降低成本。
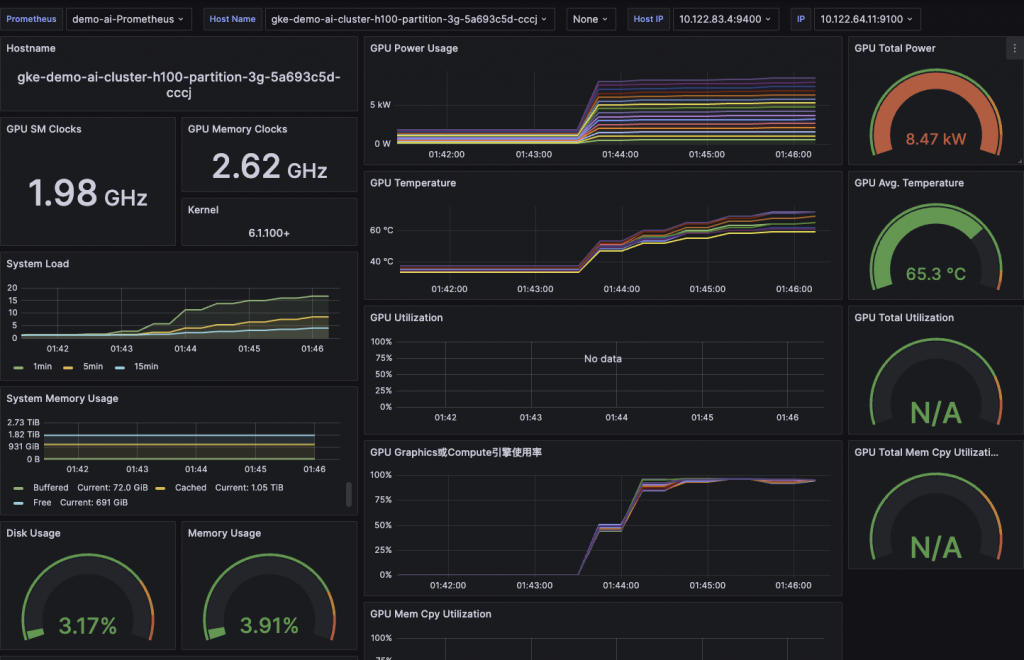
以下是我使用 Grafana 搭配 Prometheus dcgm exporter 所製成的監控圖表,和 GKE 的監控圖表看到的類似。但是也因為將 MIG 所以 GPU Utilization 及 GPU Mem Cpy Utilization 會看不到。
這裡有一個小亮點,當一台 8 張卡的 H100 高負載運轉時,耗電量可以達到 8 Kw 以上,根本吃電怪獸,筆者第一次壓測時也嚇到,這才了解到為什麼發展 AI 的同時也要蓋電廠。
本文示範了如何在 Google Kubernetes Engine (GKE) 上部署 Multi-Instance GPUs (MIG) 節點,並利用其高效能特性部署大型語言模型 (LLM)。
透過將 H100 GPU 切分為更小的 3g.40g 執行個體,我們得以更精細地分配 GPU 資源,滿足不同 LLM 推論任務的需求。 實驗中,我們成功將 Pod 數量提升兩倍,有效降低了單個請求的 GPU 成本,並提升了資源利用率。
此方法讓使用者能更彈性地運用昂貴的 GPU 資源,在控制成本的同時,維持 LLM 推論效能,對於追求高效能且經濟實惠的 AI 應用部署至關重要。 未來,MIG 技術將在 AI 領域扮演更重要的角色,尤其在日益增長的 LLM 推論需求下,其精細的資源分配能力將成為重要的成本優化策略。

