今天來優化人臉識別模型,嘗試調整超參數,理解過擬合與正則化技術。
1.超參數調整(Hyperparameter Tuning)
超參數的選擇對模型性能有直接影響。常見的超參數包括學習率、批量大小、優化器、卷積層的數量、特徵維度等。
主要超參數:
學習率(Learning Rate):
學習率過高會導致模型不穩定,錯過全局最優解;學習率過低則會導致訓練速度過慢,可能陷入局部最優。
優化策略:嘗試 學習率衰減,如使用指數衰減或在訓練過程中動態調整學習率。例如,在模型性能提升較慢時,逐步減少學習率。
自適應優化器如 Adam 自帶學習率自適應機制,也是一個選擇。
批量大小(Batch Size):
小批量大小能更好地更新權重,提升泛化能力,但會增加隨機性;大批量大小能更快地收斂,但可能會忽略細微的梯度變化。
優化策略:通常開始時用較大的批量大小來穩定訓練,然後嘗試不同的批量大小來取得最佳平衡。
嵌入向量維度:
人臉嵌入模型通常會生成128維或512維向量。較大的向量可能捕捉更多特徵,但會增加過擬合風險。
優化策略:調整嵌入向量的維度,找到能夠平衡準確率和訓練速度的最佳值。
卷積層和全連接層的深度和寬度:
增加卷積層和特徵圖數量有助於提取更高級別的特徵,但也可能增加模型的複雜度。
優化策略:在卷積層之間添加Batch Normalization,以加快訓練過程並防止梯度消失。
調參工具:
Grid Search 和 Random Search 是兩種常見的調參方法:
Grid Search:逐一嘗試所有可能的超參數組合,但對於大量參數會變得非常耗時。
Random Search:隨機選取參數進行測試,往往能以較少的計算資源取得良好的效果。
超參數自動調整框架:
使用工具如 Hyperopt、Optuna 或 Ray Tune 來自動調整超參數,通過貝葉斯優化等技術找到最佳配置。
2. 理解過擬合與防止過擬合
過擬合是指模型在訓練數據上表現良好,但在測試數據上表現不佳。這通常是由於模型過於複雜,過度適應訓練數據中的噪聲或細節,導致模型無法泛化到新的數據。
如何檢測過擬合:
訓練與驗證損失曲線:當訓練損失持續下降,但驗證損失開始上升時,表示模型出現過擬合。
評估指標變化:如果訓練集上的準確率持續提升,但測試集的準確率停滯或下降,這也是過擬合的跡象。
3. 正則化技術
正則化是防止過擬合的有效手段。常見的正則化技術包括 L2 正則化、Dropout、早停(Early Stopping)等。
A. L2 正則化(權重衰減)
L2 正則化在損失函數中添加一個懲罰項,鼓勵模型學到較小的權重,以避免過於複雜的模型。
L2 正則化公式:
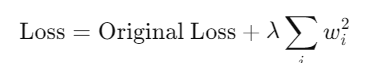
其中,λ 是正則化強度超參數,𝑤𝑖是模型的權重。這有助於抑制過大的權重,讓模型更加簡單。
 1155
1155

 iThome鐵人賽
iThome鐵人賽