今天來學習如何:處理多種人臉識別的挑戰,如光線變化、姿勢變化、遮擋等。
在人臉識別的應用中,光線變化、姿勢變化、遮擋等問題經常導致模型性能下降。這些挑戰增加了識別的難度,因為它們改變了人臉的外觀,讓模型難以準確提取特徵。為了提升模型的泛化能力,可以通過引入 數據增強技術(Data Augmentation)來改善模型在不同場景下的表現。
1. 數據增強技術的介紹
數據增強是一種在訓練過程中對訓練數據進行隨機變換的技術,通過擴充數據集來防止模型過擬合並提高泛化能力。這些變換模擬了現實中的多樣場景,如光線條件變化、不同角度的拍攝等。
2. 針對具體挑戰的數據增強方法
A. 光線變化
光線條件變化(如明暗對比度的不同或陰影的影響)會對人臉識別造成干擾。通過數據增強來模擬不同的光照條件,可以讓模型學會忽略光線變化帶來的影響。
增強方法:
調整圖像的亮度和對比度
改變曝光度或添加光源
模擬局部陰影和反射
Python 實現範例(TensorFlow + Keras):
PyTorch: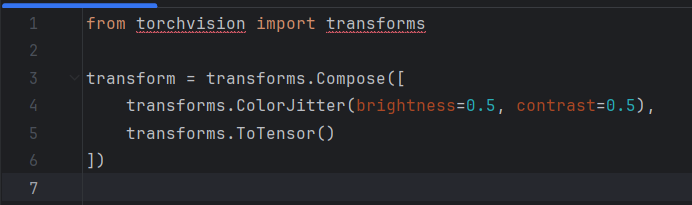
B. 姿勢變化
不同角度的拍攝會改變人臉在圖像中的位置和形狀,尤其是側面臉或傾斜的人臉。數據增強可以通過旋轉、平移和縮放來模擬這些姿勢變化。
增強方法:
隨機旋轉圖像
隨機平移圖像(水平或垂直移動)
進行幾何變換,如傾斜或剪切變換
Python 實現範例(TensorFlow + Keras):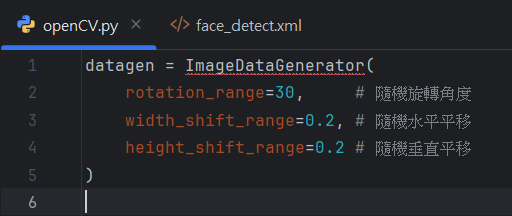
PyTorch: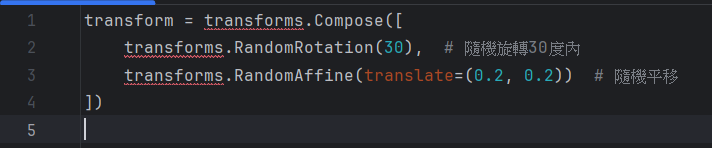
C. 遮擋
遮擋(如佩戴眼鏡、口罩、手遮臉等)會讓模型無法識別完整的人臉。因此,應通過增強技術來模擬遮擋情況,使模型能在這些情況下仍然做出準確預測。
增強方法:
添加隨機噪聲
添加部分遮擋區域(如模擬口罩、手等)
使用 Cutout 或 Random Erasing 進行隨機擦除部分像素
Python 實現範例(TensorFlow + Keras):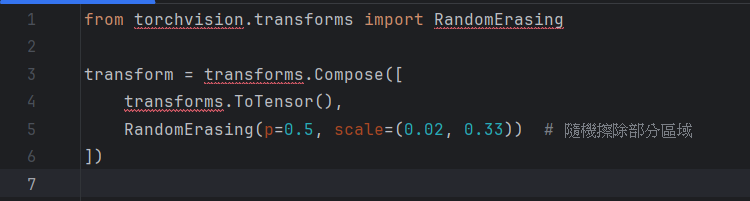
D. 表情變化
不同的表情會影響人臉的外觀。增強技術可以用來模擬一些表情變化,或通過更多樣化的數據集來涵蓋不同表情。
增強方法:
使用現有的包含多樣表情的人臉數據集,如 CelebA、AffectNet 等
人工生成具有不同表情的樣本
3. 數據增強的工具與庫
多個深度學習框架都提供了便捷的數據增強工具。以下是一些常用的工具和庫,能夠實現多種數據增強方法:
TensorFlow/Keras: ImageDataGenerator 支持圖像旋轉、平移、縮放、翻轉等常見增強。
PyTorch: torchvision.transforms 提供了各種增強操作,如隨機旋轉、剪裁、擦除等。
Albumentations: 一個專業的圖像增強庫,支持更複雜的增強策略,適合高級應用場景。
Albumentations 的範例: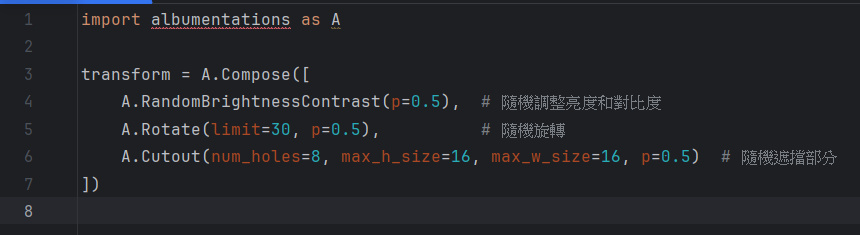
4. 提升模型泛化能力的其他技巧
除了數據增強技術,還可以使用以下方法進一步提升人臉識別模型的泛化能力:
A. 正則化
使用正則化技術(如 L2 正則化或 Dropout)可以抑制模型過擬合,提高其在未知數據上的表現。
L2 正則化 在損失函數中引入懲罰項,防止模型學習到過於複雜的模式。
B. 更大的訓練數據集
利用多樣化的數據集來訓練模型,這樣可以讓模型學習更多不同條件下的人臉特徵。例如,使用大規模數據集如 LFW、MS-Celeb-1M、VGGFace2 等。
C. 遷移學習
如果數據量有限,可以使用預訓練的模型(如 FaceNet、DeepFace 等)進行遷移學習,並在新的數據集上進行微調。
總結
為了提升人臉識別模型的泛化能力,應針對光線變化、姿勢變化、遮擋等挑戰,採用數據增強技術來模擬多種場景。透過這些增強技術,模型能更好地適應不同條件下的輸入,進一步提升準確率和穩定性。
如果需要更高的精度或應對複雜場景,可以結合正則化、遷移學習以及大規模數據集來提升模型性能。這些技術不僅能解決現有問題,還能讓模型具備更強的泛化能力,應對更廣泛的應用場景。
 1155
1155

 iThome鐵人賽
iThome鐵人賽