在上一篇提到Instagram開發團隊在面臨大量資料時,將其分成shard並透過postgres的schema來將資料進行儲存。在2012年時Ig每秒接收到90個like的儲存請求,而短短不到一年的時間,Ig就要面臨每秒超過1萬個讚的儲存請求到postgres中。面臨針對DB的大量請求,Ig開發團隊提出了幾點可以優化的方向:
如果經常根據特定條件過濾查詢,且這些條件只存在於少數行時,部分索引可以帶來很大的效能提升。通過建立部分索引,根據文中的查詢需求案例中可以讓需要處理15000行資料、耗時215ms的查詢語句變成只需處理169行與耗時3ms
個人觀點:
要找出這樣的篩選邏輯,需要觀察常常出現在where的條件以及最花時間的查詢並且條件能夠有效過濾掉大部分不需要的數據。建立索引的同時,定期觀察資料範圍,更新索引並刪除不必要的索引

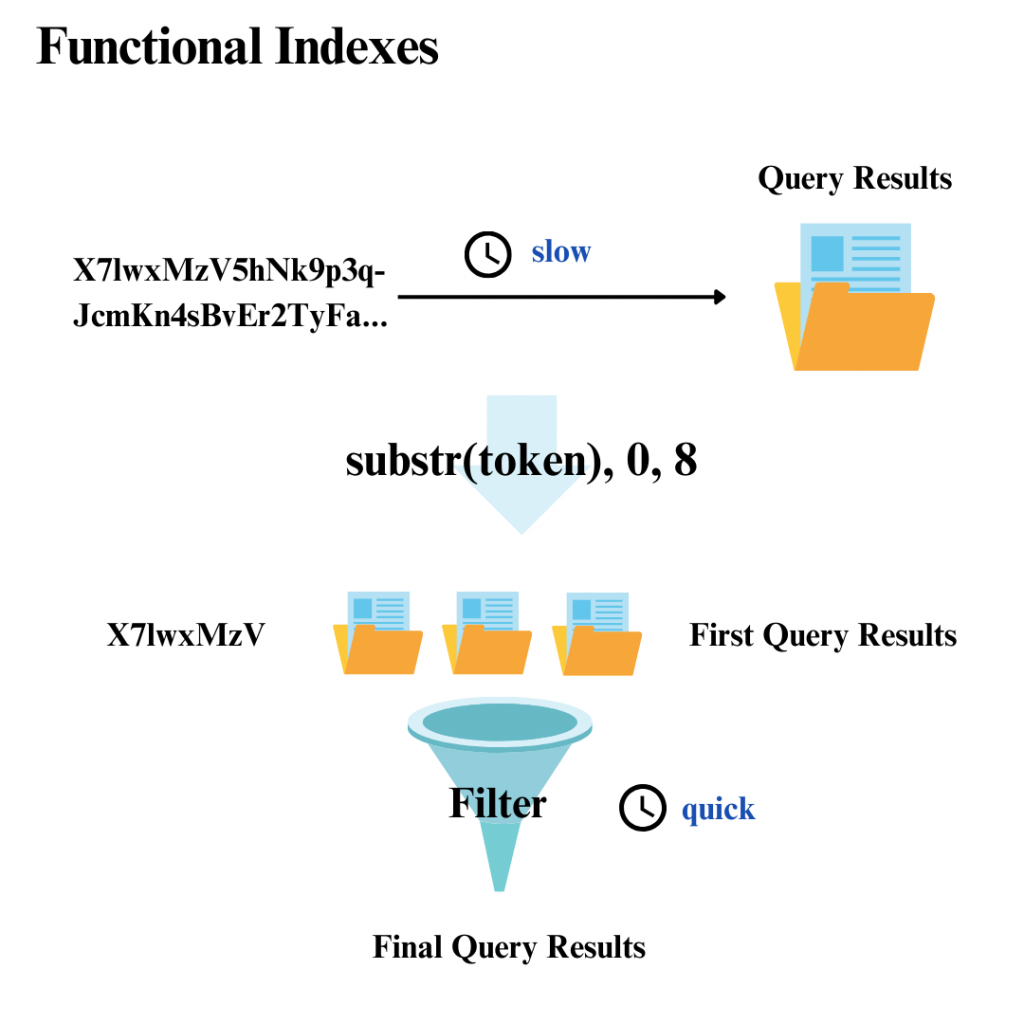
如果要索引的資料是很長的字符串(如64字符的base64令牌),可以只索引字符串的一小部分
當然這樣還是會篩出很多符合前綴的資料,但是此時要做後續的篩選速度就會很快。在保持相對較好的查詢性能時,同時將索引大小減少到原本的1/10
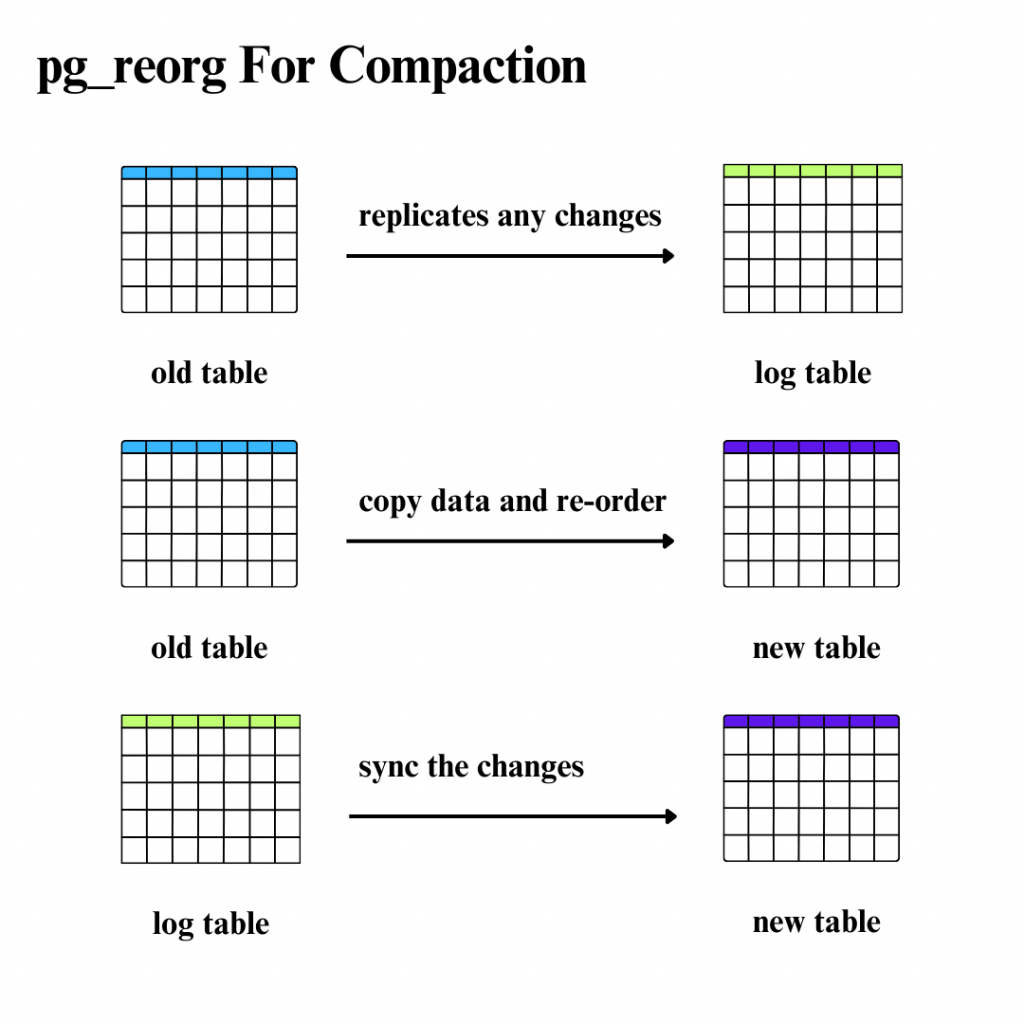
現在pg_reorg已經沒有在維護,取而代之的是pg_repack,但這邊只說他的核心概念。postgres的MVCC(Multi-Version Concurrency Control)機制可能會造成資料膨脹,並且插入資料的順序跟我們理想的查詢狀況可能是不相同的。例如理想中我想要查有關特定用戶的資料,但是插入資料時不可能該用戶的資料剛好都儲存在一起,但是相關資料散佈在磁碟各處,表碎片化的問題會導致查詢的浪費,可以透過幾個步驟來做表的壓縮
要做以上操作時一定要注意剩餘空間是否足夠,而關於鎖的細節文章中就沒有特別展開了,可能需要深入了解pg_repack機制
Ig開發團隊將postgres預寫日誌檔透過Heroku工具包中的WAL-E進行歸檔,WAL-E將PG伺服器產生的WAL檔案存在Amazon S3。透過將WAL檔與基本備份結合使用,在修復故障或是轉移時可以將資料庫還原到備份以後的任意時間點
因為使用Django這個python框架做開發,因此使用更多基於python驅動引擎的psycopg2。而postgres具備transaction特性,所以許多操作具備BEGIN/COMMIT來維持一制性。而在許多只讀操作中,就可以設置autocommit mode來伺服器與資料庫的通訊量,減輕CPU壓力
另一個psycopg2的實用功能是能夠註冊wait_callback以支援協程。在先前的文章提到Ig團隊透過postgres的schema將資料進行分布式儲存,因此這樣的fan-out查詢方式比起傳統輪流查詢每個shard的方式會節省更多時間。同時使用協程也能夠幫助建立多節點的socket通訊(python中的select套件),並且也能搭配像gevent這個支援協程的python套件
 blank
blank

 iThome鐵人賽
iThome鐵人賽